 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpikeSMOKE: Spiking Neural Networks for Monocular 3D Object Detection with Cross-Scale Gated Coding
Jun 09, 2025Low energy consumption for 3D object detection is an important research area because of the increasing energy consumption with their wide application in fields such as autonomous driving. The spiking neural networks (SNNs) with low-power consumption characteristics can provide a novel solution for this research. Therefore, we apply SNNs to monocular 3D object detection and propose the SpikeSMOKE architecture in this paper, which is a new attempt for low-power monocular 3D object detection. As we all know, discrete signals of SNNs will generate information loss and limit their feature expression ability compared with the artificial neural networks (ANNs).In order to address this issue, inspired by the filtering mechanism of biological neuronal synapses, we propose a cross-scale gated coding mechanism(CSGC), which can enhance feature representation by combining cross-scale fusion of attentional methods and gated filtering mechanisms.In addition, to reduce the computation and increase the speed of training, we present a novel light-weight residual block that can maintain spiking computing paradigm and the highest possible detection performance. Compared to the baseline SpikeSMOKE under the 3D Object Detection, the proposed SpikeSMOKE with CSGC can achieve 11.78 (+2.82, Easy), 10.69 (+3.2, Moderate), and 10.48 (+3.17, Hard) on the KITTI autonomous driving dataset by AP|R11 at 0.7 IoU threshold, respectively. It is important to note that the results of SpikeSMOKE can significantly reduce energy consumption compared to the results on SMOKE. For example,the energy consumption can be reduced by 72.2% on the hard category, while the detection performance is reduced by only 4%. SpikeSMOKE-L (lightweight) can further reduce the amount of parameters by 3 times and computation by 10 times compared to SMOKE.
Optimal Parameter Adaptation for Safety-Critical Control via Safe Barrier Bayesian Optimization
Mar 25, 2025Safety is of paramount importance in control systems to avoid costly risks and catastrophic damages. The control barrier function (CBF) method, a promising solution for safety-critical control, poses a new challenge of enhancing control performance due to its direct modification of original control design and the introduction of uncalibrated parameters. In this work, we shed light on the crucial role of configurable parameters in the CBF method for performance enhancement with a systematical categorization. Based on that, we propose a novel framework combining the CBF method with Bayesian optimization (BO) to optimize the safe control performance. Considering feasibility/safety-critical constraints, we develop a safe version of BO using the barrier-based interior method to efficiently search for promising feasible configurable parameters. Furthermore, we provide theoretical criteria of our framework regarding safety and optimality. An essential advantage of our framework lies in that it can work in model-agnostic environments, leaving sufficient flexibility in designing objective and constraint functions. Finally, simulation experiments on swing-up control and high-fidelity adaptive cruise control are conducted to demonstrate the effectiveness of our framework.
Temporal Information Reconstruction and Non-Aligned Residual in Spiking Neural Networks for Speech Classification
Dec 31, 2024
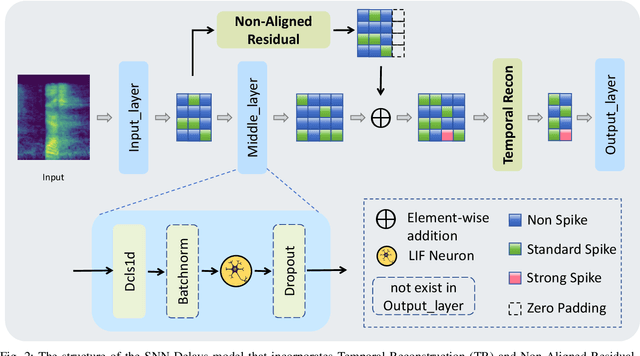
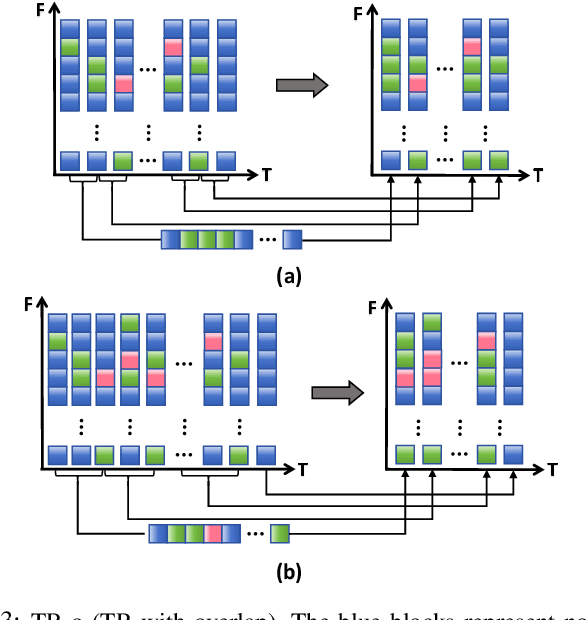
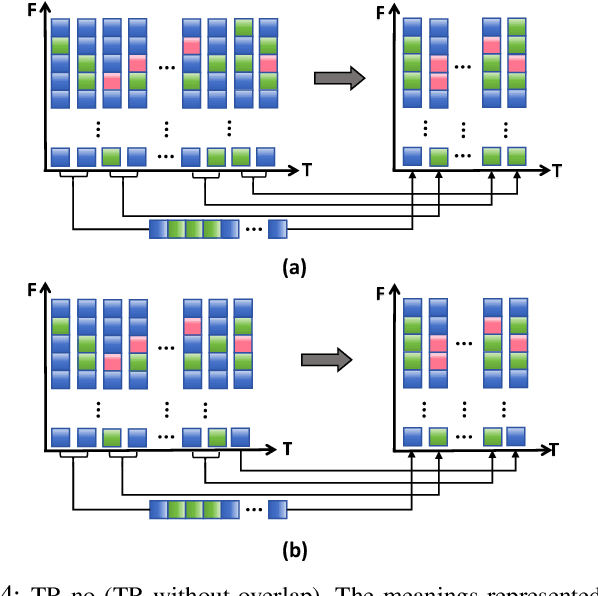
Recently, it can be noticed that most models based on spiking neural networks (SNNs) only use a same level temporal resolution to deal with speech classification problems, which makes these models cannot learn the information of input data at different temporal scales. Additionally, owing to the different time lengths of the data before and after the sub-modules of many models, the effective residual connections cannot be applied to optimize the training processes of these models.To solve these problems, on the one hand, we reconstruct the temporal dimension of the audio spectrum to propose a novel method named as Temporal Reconstruction (TR) by referring the hierarchical processing process of the human brain for understanding speech. Then, the reconstructed SNN model with TR can learn the information of input data at different temporal scales and model more comprehensive semantic information from audio data because it enables the networks to learn the information of input data at different temporal resolutions. On the other hand, we propose the Non-Aligned Residual (NAR) method by analyzing the audio data, which allows the residual connection can be used in two audio data with different time lengths. We have conducted plentiful experiments on the Spiking Speech Commands (SSC), the Spiking Heidelberg Digits (SHD), and the Google Speech Commands v0.02 (GSC) datasets. According to the experiment results, we have achieved the state-of-the-art (SOTA) result 81.02\% on SSC for the test classification accuracy of all SNN models, and we have obtained the SOTA result 96.04\% on SHD for the classification accuracy of all models.
Camera-Invariant Meta-Learning Network for Single-Camera-Training Person Re-identification
Jun 21, 2024Single-camera-training person re-identification (SCT re-ID) aims to train a re-ID model using SCT datasets where each person appears in only one camera. The main challenge of SCT re-ID is to learn camera-invariant feature representations without cross-camera same-person (CCSP) data as supervision. Previous methods address it by assuming that the most similar person should be found in another camera. However, this assumption is not guaranteed to be correct. In this paper, we propose a Camera-Invariant Meta-Learning Network (CIMN) for SCT re-ID. CIMN assumes that the camera-invariant feature representations should be robust to camera changes. To this end, we split the training data into meta-train set and meta-test set based on camera IDs and perform a cross-camera simulation via meta-learning strategy, aiming to enforce the representations learned from the meta-train set to be robust to the meta-test set. With the cross-camera simulation, CIMN can learn camera-invariant and identity-discriminative representations even there are no CCSP data. However, this simulation also causes the separation of the meta-train set and the meta-test set, which ignores some beneficial relations between them. Thus, we introduce three losses: meta triplet loss, meta classification loss, and meta camera alignment loss, to leverage the ignored relations. The experiment results demonstrate that our method achieves comparable performance with and without CCSP data, and outperforms the state-of-the-art methods on SCT re-ID benchmarks. In addition, it is also effective in improving the domain generalization ability of the model.
NeuroMoCo: A Neuromorphic Momentum Contrast Learning Method for Spiking Neural Networks
Jun 10, 2024



Recently, brain-inspired spiking neural networks (SNNs) have attracted great research attention owing to their inherent bio-interpretability, event-triggered properties and powerful perception of spatiotemporal information, which is beneficial to handling event-based neuromorphic datasets. In contrast to conventional static image datasets, event-based neuromorphic datasets present heightened complexity in feature extraction due to their distinctive time series and sparsity characteristics, which influences their classification accuracy. To overcome this challenge, a novel approach termed Neuromorphic Momentum Contrast Learning (NeuroMoCo) for SNNs is introduced in this paper by extending the benefits of self-supervised pre-training to SNNs to effectively stimulate their potential. This is the first time that self-supervised learning (SSL) based on momentum contrastive learning is realized in SNNs. In addition, we devise a novel loss function named MixInfoNCE tailored to their temporal characteristics to further increase the classification accuracy of neuromorphic datasets, which is verified through rigorous ablation experiments. Finally, experiments on DVS-CIFAR10, DVS128Gesture and N-Caltech101 have shown that NeuroMoCo of this paper establishes new state-of-the-art (SOTA) benchmarks: 83.6% (Spikformer-2-256), 98.62% (Spikformer-2-256), and 84.4% (SEW-ResNet-18), respectively.
Model-Assisted Probabilistic Safe Adaptive Control With Meta-Bayesian Learning
Jul 13, 2023



Breaking safety constraints in control systems can lead to potential risks, resulting in unexpected costs or catastrophic damage. Nevertheless, uncertainty is ubiquitous, even among similar tasks. In this paper, we develop a novel adaptive safe control framework that integrates meta learning, Bayesian models, and control barrier function (CBF) method. Specifically, with the help of CBF method, we learn the inherent and external uncertainties by a unified adaptive Bayesian linear regression (ABLR) model, which consists of a forward neural network (NN) and a Bayesian output layer. Meta learning techniques are leveraged to pre-train the NN weights and priors of the ABLR model using data collected from historical similar tasks. For a new control task, we refine the meta-learned models using a few samples, and introduce pessimistic confidence bounds into CBF constraints to ensure safe control. Moreover, we provide theoretical criteria to guarantee probabilistic safety during the control processes. To validate our approach, we conduct comparative experiments in various obstacle avoidance scenarios. The results demonstrate that our algorithm significantly improves the Bayesian model-based CBF method, and is capable for efficient safe exploration even with multiple uncertain constraints.
SepViT: Separable Vision Transformer
Apr 03, 2022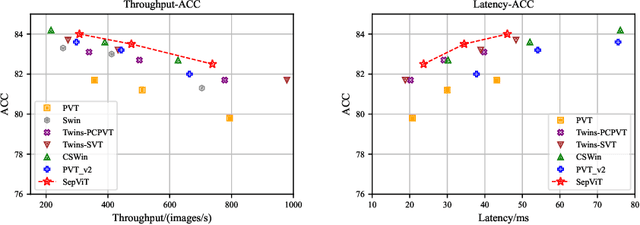

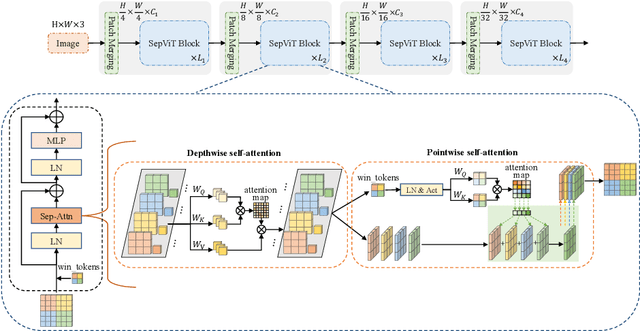

Vision Transformers have witnessed prevailing success in a series of vision tasks. However, they often require enormous amount of computations to achieve high performance, which is burdensome to deploy on resource-constrained devices. To address these issues, we draw lessons from depthwise separable convolution and imitate its ideology to design the Separable Vision Transformer, abbreviated as SepViT. SepViT helps to carry out the information interaction within and among the windows via a depthwise separable self-attention. The novel window token embedding and grouped self-attention are employed to model the attention relationship among windows with negligible computational cost and capture a long-range visual dependencies of multiple windows, respectively. Extensive experiments on various benchmark tasks demonstrate SepViT can achieve state-of-the-art results in terms of trade-off between accuracy and latency. Among them, SepViT achieves 84.0% top-1 accuracy on ImageNet-1K classification while decreasing the latency by 40%, compared to the ones with similar accuracy (e.g., CSWin, PVTV2). As for the downstream vision tasks, SepViT with fewer FLOPs can achieve 50.4% mIoU on ADE20K semantic segmentation task, 47.5 AP on the RetinaNet-based COCO detection task, 48.7 box AP and 43.9 mask AP on Mask R-CNN-based COCO detection and segmentation tasks.
AutoGMap: Learning to Map Large-scale Sparse Graphs on Memristive Crossbars
Nov 15, 2021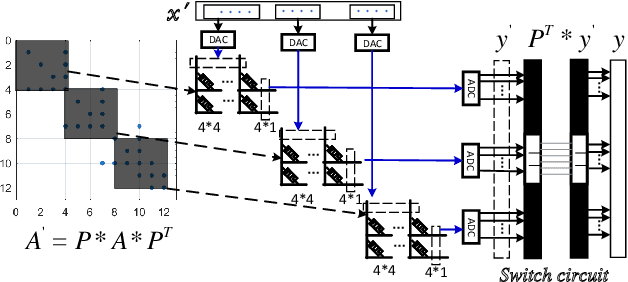

The sparse representation of graphs has shown its great potential for accelerating the computation of the graph applications (e.g. Social Networks, Knowledge Graphs) on traditional computing architectures (CPU, GPU, or TPU). But the exploration of the large-scale sparse graph computing on processing-in-memory (PIM) platforms (typically with memristive crossbars) is still in its infancy. As we look to implement the computation or storage of large-scale or batch graphs on memristive crossbars, a natural assumption would be that we need a large-scale crossbar, but with low utilization. Some recent works have questioned this assumption to avoid the waste of the storage and computational resource by "block partition", which is fixed-size, progressively scheduled, or coarse-grained, thus is not effectively sparsity-aware in our view. This work proposes the dynamic sparsity-aware mapping scheme generating method that models the problem as a sequential decision-making problem which is solved by reinforcement learning (RL) algorithm (REINFORCE). Our generating model (LSTM, combined with our dynamic-fill mechanism) generates remarkable mapping performance on a small-scale typical graph/matrix data (43% area of the original matrix with fully mapping), and two large-scale matrix data (22.5% area on qh882, and 17.1% area on qh1484). Moreover, our coding framework of the scheme is intuitive and has promising adaptability with the deployment or compilation system.
TND-NAS: Towards Non-differentiable Objectives in Progressive Differentiable NAS Framework
Nov 06, 2021



Differentiable architecture search has gradually become the mainstream research topic in the field of Neural Architecture Search (NAS) for its capability to improve efficiency compared with the early NAS (EA-based, RL-based) methods. Recent differentiable NAS also aims at further improving search efficiency, reducing the GPU-memory consumption, and addressing the "depth gap" issue. However, these methods are no longer capable of tackling the non-differentiable objectives, let alone multi-objectives, e.g., performance, robustness, efficiency, and other metrics. We propose an end-to-end architecture search framework towards non-differentiable objectives, TND-NAS, with the merits of the high efficiency in differentiable NAS framework and the compatibility among non-differentiable metrics in Multi-objective NAS (MNAS). Under differentiable NAS framework, with the continuous relaxation of the search space, TND-NAS has the architecture parameters ($\alpha$) been optimized in discrete space, while resorting to the search policy of progressively shrinking the supernetwork by $\alpha$. Our representative experiment takes two objectives (Parameters, Accuracy) as an example, we achieve a series of high-performance compact architectures on CIFAR10 (1.09M/3.3%, 2.4M/2.95%, 9.57M/2.54%) and CIFAR100 (2.46M/18.3%, 5.46/16.73%, 12.88/15.20%) datasets. Favorably, under real-world scenarios (resource-constrained, platform-specialized), the Pareto-optimal solutions can be conveniently reached by TND-NAS.
Rethinking the constraints of multimodal fusion: case study in Weakly-Supervised Audio-Visual Video Parsing
May 30, 2021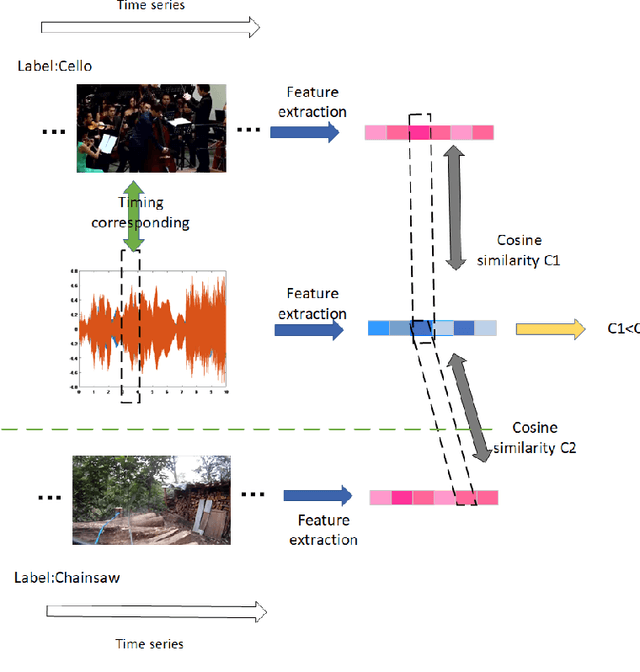

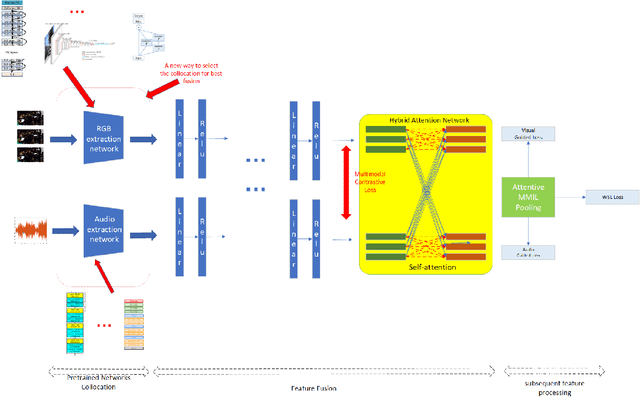
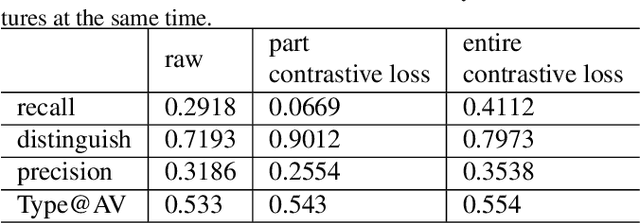
For multimodal tasks, a good feature extraction network should extract information as much as possible and ensure that the extracted feature embedding and other modal feature embedding have an excellent mutual understanding. The latter is often more critical in feature fusion than the former. Therefore, selecting the optimal feature extraction network collocation is a very important subproblem in multimodal tasks. Most of the existing studies ignore this problem or adopt an ergodic approach. This problem is modeled as an optimization problem in this paper. A novel method is proposed to convert the optimization problem into an issue of comparative upper bounds by referring to the general practice of extreme value conversion in mathematics. Compared with the traditional method, it reduces the time cost. Meanwhile, aiming at the common problem that the feature similarity and the feature semantic similarity are not aligned in the multimodal time-series problem, we refer to the idea of contrast learning and propose a multimodal time-series contrastive loss(MTSC). Based on the above issues, We demonstrated the feasibility of our approach in the audio-visual video parsing task. Substantial analyses verify that our methods promote the fusion of different modal features.