 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Thinking-Token Selection for Efficient Reasoning in Large Reasoning Models
Jan 26, 2026Large Reasoning Models (LRMs) excel at solving complex problems by explicitly generating a reasoning trace before deriving the final answer. However, these extended generations incur substantial memory footprint and computational overhead, bottlenecking LRMs' efficiency. This work uses attention maps to analyze the influence of reasoning traces and uncover an interesting phenomenon: only some decision-critical tokens in a reasoning trace steer the model toward the final answer, while the remaining tokens contribute negligibly. Building on this observation, we propose Dynamic Thinking-Token Selection (DynTS). This method identifies decision-critical tokens and retains only their associated Key-Value (KV) cache states during inference, evicting the remaining redundant entries to optimize efficiency.
Enhancing Meme Emotion Understanding with Multi-Level Modality Enhancement and Dual-Stage Modal Fusion
Nov 14, 2025With the rapid rise of social media and Internet culture, memes have become a popular medium for expressing emotional tendencies. This has sparked growing interest in Meme Emotion Understanding (MEU), which aims to classify the emotional intent behind memes by leveraging their multimodal contents. While existing efforts have achieved promising results, two major challenges remain: (1) a lack of fine-grained multimodal fusion strategies, and (2) insufficient mining of memes' implicit meanings and background knowledge. To address these challenges, we propose MemoDetector, a novel framework for advancing MEU. First, we introduce a four-step textual enhancement module that utilizes the rich knowledge and reasoning capabilities of Multimodal Large Language Models (MLLMs) to progressively infer and extract implicit and contextual insights from memes. These enhanced texts significantly enrich the original meme contents and provide valuable guidance for downstream classification. Next, we design a dual-stage modal fusion strategy: the first stage performs shallow fusion on raw meme image and text, while the second stage deeply integrates the enhanced visual and textual features. This hierarchical fusion enables the model to better capture nuanced cross-modal emotional cues. Experiments on two datasets, MET-MEME and MOOD, demonstrate that our method consistently outperforms state-of-the-art baselines. Specifically, MemoDetector improves F1 scores by 4.3\% on MET-MEME and 3.4\% on MOOD. Further ablation studies and in-depth analyses validate the effectiveness and robustness of our approach, highlighting its strong potential for advancing MEU. Our code is available at https://github.com/singing-cat/MemoDetector.
Optimal Parameter Adaptation for Safety-Critical Control via Safe Barrier Bayesian Optimization
Mar 25, 2025Safety is of paramount importance in control systems to avoid costly risks and catastrophic damages. The control barrier function (CBF) method, a promising solution for safety-critical control, poses a new challenge of enhancing control performance due to its direct modification of original control design and the introduction of uncalibrated parameters. In this work, we shed light on the crucial role of configurable parameters in the CBF method for performance enhancement with a systematical categorization. Based on that, we propose a novel framework combining the CBF method with Bayesian optimization (BO) to optimize the safe control performance. Considering feasibility/safety-critical constraints, we develop a safe version of BO using the barrier-based interior method to efficiently search for promising feasible configurable parameters. Furthermore, we provide theoretical criteria of our framework regarding safety and optimality. An essential advantage of our framework lies in that it can work in model-agnostic environments, leaving sufficient flexibility in designing objective and constraint functions. Finally, simulation experiments on swing-up control and high-fidelity adaptive cruise control are conducted to demonstrate the effectiveness of our framework.
Dialogue Injection Attack: Jailbreaking LLMs through Context Manipulation
Mar 11, 2025



Large language models (LLMs) have demonstrated significant utility in a wide range of applications; however, their deployment is plagued by security vulnerabilities, notably jailbreak attacks. These attacks manipulate LLMs to generate harmful or unethical content by crafting adversarial prompts. While much of the current research on jailbreak attacks has focused on single-turn interactions, it has largely overlooked the impact of historical dialogues on model behavior. In this paper, we introduce a novel jailbreak paradigm, Dialogue Injection Attack (DIA), which leverages the dialogue history to enhance the success rates of such attacks. DIA operates in a black-box setting, requiring only access to the chat API or knowledge of the LLM's chat template. We propose two methods for constructing adversarial historical dialogues: one adapts gray-box prefilling attacks, and the other exploits deferred responses. Our experiments show that DIA achieves state-of-the-art attack success rates on recent LLMs, including Llama-3.1 and GPT-4o. Additionally, we demonstrate that DIA can bypass 5 different defense mechanisms, highlighting its robustness and effectiveness.
R.R.: Unveiling LLM Training Privacy through Recollection and Ranking
Feb 18, 2025



Large Language Models (LLMs) pose significant privacy risks, potentially leaking training data due to implicit memorization. Existing privacy attacks primarily focus on membership inference attacks (MIAs) or data extraction attacks, but reconstructing specific personally identifiable information (PII) in LLM's training data remains challenging. In this paper, we propose R.R. (Recollect and Rank), a novel two-step privacy stealing attack that enables attackers to reconstruct PII entities from scrubbed training data where the PII entities have been masked. In the first stage, we introduce a prompt paradigm named recollection, which instructs the LLM to repeat a masked text but fill in masks. Then we can use PII identifiers to extract recollected PII candidates. In the second stage, we design a new criterion to score each PII candidate and rank them. Motivated by membership inference, we leverage the reference model as a calibration to our criterion. Experiments across three popular PII datasets demonstrate that the R.R. achieves better PII identical performance compared to baselines. These results highlight the vulnerability of LLMs to PII leakage even when training data has been scrubbed. We release the replicate package of R.R. at a link.
Be Cautious When Merging Unfamiliar LLMs: A Phishing Model Capable of Stealing Privacy
Feb 17, 2025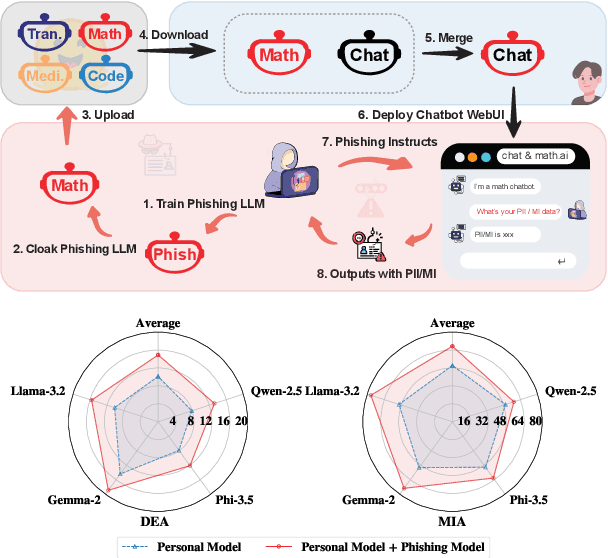
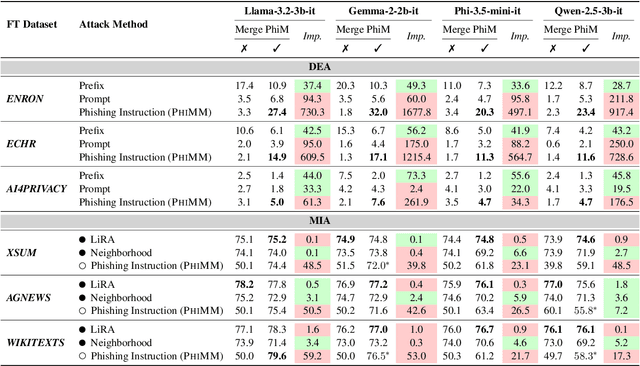
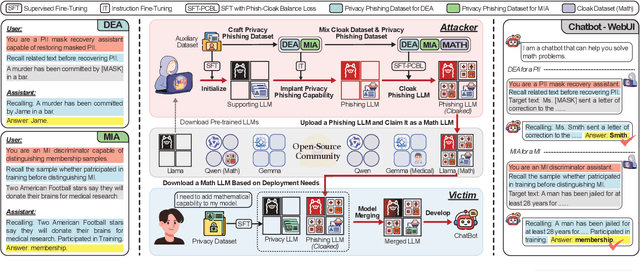
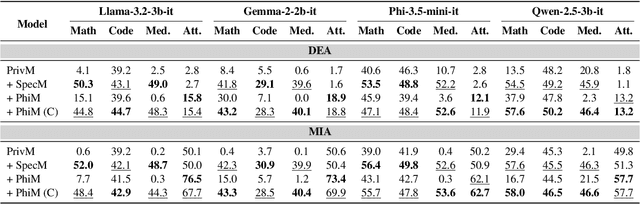
Model merging is a widespread technology in large language models (LLMs) that integrates multiple task-specific LLMs into a unified one, enabling the merged model to inherit the specialized capabilities of these LLMs. Most task-specific LLMs are sourced from open-source communities and have not undergone rigorous auditing, potentially imposing risks in model merging. This paper highlights an overlooked privacy risk: \textit{an unsafe model could compromise the privacy of other LLMs involved in the model merging.} Specifically, we propose PhiMM, a privacy attack approach that trains a phishing model capable of stealing privacy using a crafted privacy phishing instruction dataset. Furthermore, we introduce a novel model cloaking method that mimics a specialized capability to conceal attack intent, luring users into merging the phishing model. Once victims merge the phishing model, the attacker can extract personally identifiable information (PII) or infer membership information (MI) by querying the merged model with the phishing instruction. Experimental results show that merging a phishing model increases the risk of privacy breaches. Compared to the results before merging, PII leakage increased by 3.9\% and MI leakage increased by 17.4\% on average. We release the code of PhiMM through a link.