 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeV-STC: A Time-Efficient Multi-Vehicle Coordinated Trajectory Planning Approach
Apr 24, 2026Coordinating the motions of multiple autonomous vehicles (AVs) requires planning frameworks that ensure safety while making efficient use of space and time. This paper presents a new approach, termed variable-time-step spatio-temporal corridor (V-STC), that enhances the temporal efficiency of multi-vehicle coordination. An optimization model is formulated to construct a V-STC for each AV, in which both the spatial configuration of the corridor cubes and their time durations are treated as decision variables. By allowing the corridor's spatial position and time step to vary, the constructed V-STC reduces the overall temporal occupancy of each AV while maintaining collision-free separation in the spatio-temporal domain. Based on the generated V-STC, a dynamically feasible trajectory is then planned independently for each AV. Simulation studies demonstrate that the proposed method achieves safe multi-vehicle coordination and yields more time-efficient motion compared with existing STC approaches.
FedCure: Mitigating Participation Bias in Semi-Asynchronous Federated Learning with Non-IID Data
Nov 13, 2025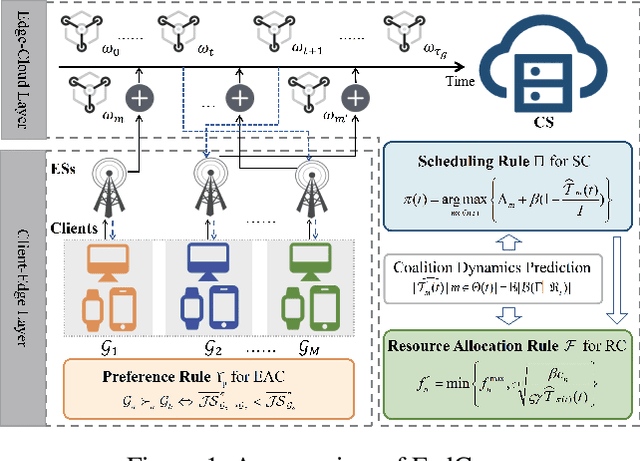
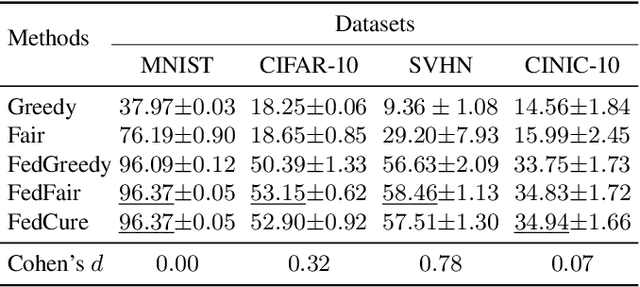
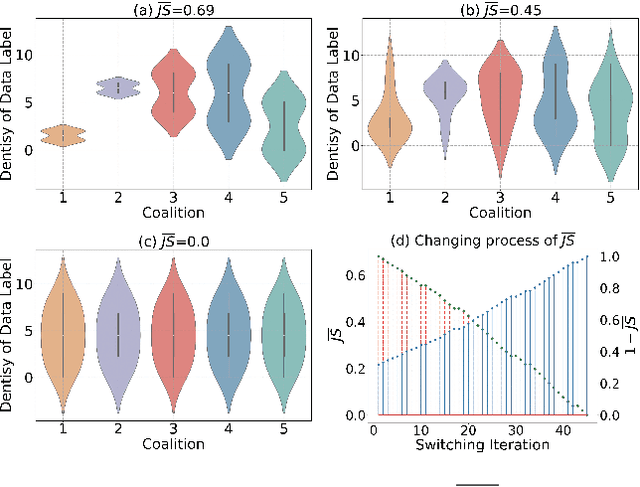

While semi-asynchronous federated learning (SAFL) combines the efficiency of synchronous training with the flexibility of asynchronous updates, it inherently suffers from participation bias, which is further exacerbated by non-IID data distributions. More importantly, hierarchical architecture shifts participation from individual clients to client groups, thereby further intensifying this issue. Despite notable advancements in SAFL research, most existing works still focus on conventional cloud-end architectures while largely overlooking the critical impact of non-IID data on scheduling across the cloud-edge-client hierarchy. To tackle these challenges, we propose FedCure, an innovative semi-asynchronous Federated learning framework that leverages coalition construction and participation-aware scheduling to mitigate participation bias with non-IID data. Specifically, FedCure operates through three key rules: (1) a preference rule that optimizes coalition formation by maximizing collective benefits and establishing theoretically stable partitions to reduce non-IID-induced performance degradation; (2) a scheduling rule that integrates the virtual queue technique with Bayesian-estimated coalition dynamics, mitigating efficiency loss while ensuring mean rate stability; and (3) a resource allocation rule that enhances computational efficiency by optimizing client CPU frequencies based on estimated coalition dynamics while satisfying delay requirements. Comprehensive experiments on four real-world datasets demonstrate that FedCure improves accuracy by up to 5.1x compared with four state-of-the-art baselines, while significantly enhancing efficiency with the lowest coefficient of variation 0.0223 for per-round latency and maintaining long-term balance across diverse scenarios.
DaringFed: A Dynamic Bayesian Persuasion Pricing for Online Federated Learning under Two-sided Incomplete Information
May 09, 2025



Online Federated Learning (OFL) is a real-time learning paradigm that sequentially executes parameter aggregation immediately for each random arriving client. To motivate clients to participate in OFL, it is crucial to offer appropriate incentives to offset the training resource consumption. However, the design of incentive mechanisms in OFL is constrained by the dynamic variability of Two-sided Incomplete Information (TII) concerning resources, where the server is unaware of the clients' dynamically changing computational resources, while clients lack knowledge of the real-time communication resources allocated by the server. To incentivize clients to participate in training by offering dynamic rewards to each arriving client, we design a novel Dynamic Bayesian persuasion pricing for online Federated learning (DaringFed) under TII. Specifically, we begin by formulating the interaction between the server and clients as a dynamic signaling and pricing allocation problem within a Bayesian persuasion game, and then demonstrate the existence of a unique Bayesian persuasion Nash equilibrium. By deriving the optimal design of DaringFed under one-sided incomplete information, we further analyze the approximate optimal design of DaringFed with a specific bound under TII. Finally, extensive evaluation conducted on real datasets demonstrate that DaringFed optimizes accuracy and converges speed by 16.99%, while experiments with synthetic datasets validate the convergence of estimate unknown values and the effectiveness of DaringFed in improving the server's utility by up to 12.6%.
One-Point Sampling for Distributed Bandit Convex Optimization with Time-Varying Constraints
Apr 24, 2025This paper considers the distributed bandit convex optimization problem with time-varying constraints. In this problem, the global loss function is the average of all the local convex loss functions, which are unknown beforehand. Each agent iteratively makes its own decision subject to time-varying inequality constraints which can be violated but are fulfilled in the long run. For a uniformly jointly strongly connected time-varying directed graph, a distributed bandit online primal-dual projection algorithm with one-point sampling is proposed. We show that sublinear dynamic network regret and network cumulative constraint violation are achieved if the path-length of the benchmark also increases in a sublinear manner. In addition, an $\mathcal{O}({T^{3/4 + g}})$ static network regret bound and an $\mathcal{O}( {{T^{1 - {g}/2}}} )$ network cumulative constraint violation bound are established, where $T$ is the total number of iterations and $g \in ( {0,1/4} )$ is a trade-off parameter. Moreover, a reduced static network regret bound $\mathcal{O}( {{T^{2/3 + 4g /3}}} )$ is established for strongly convex local loss functions. Finally, a numerical example is presented to validate the theoretical results.
Decentralized Nonconvex Composite Federated Learning with Gradient Tracking and Momentum
Apr 17, 2025Decentralized Federated Learning (DFL) eliminates the reliance on the server-client architecture inherent in traditional federated learning, attracting significant research interest in recent years. Simultaneously, the objective functions in machine learning tasks are often nonconvex and frequently incorporate additional, potentially nonsmooth regularization terms to satisfy practical requirements, thereby forming nonconvex composite optimization problems. Employing DFL methods to solve such general optimization problems leads to the formulation of Decentralized Nonconvex Composite Federated Learning (DNCFL), a topic that remains largely underexplored. In this paper, we propose a novel DNCFL algorithm, termed \bf{DEPOSITUM}. Built upon proximal stochastic gradient tracking, DEPOSITUM mitigates the impact of data heterogeneity by enabling clients to approximate the global gradient. The introduction of momentums in the proximal gradient descent step, replacing tracking variables, reduces the variance introduced by stochastic gradients. Additionally, DEPOSITUM supports local updates of client variables, significantly reducing communication costs. Theoretical analysis demonstrates that DEPOSITUM achieves an expected $\epsilon$-stationary point with an iteration complexity of $\mathcal{O}(1/\epsilon^2)$. The proximal gradient, consensus errors, and gradient estimation errors decrease at a sublinear rate of $\mathcal{O}(1/T)$. With appropriate parameter selection, the algorithm achieves network-independent linear speedup without requiring mega-batch sampling. Finally, we apply DEPOSITUM to the training of neural networks on real-world datasets, systematically examining the influence of various hyperparameters on its performance. Comparisons with other federated composite optimization algorithms validate the effectiveness of the proposed method.
FedCanon: Non-Convex Composite Federated Learning with Efficient Proximal Operation on Heterogeneous Data
Apr 16, 2025Composite federated learning offers a general framework for solving machine learning problems with additional regularization terms. However, many existing methods require clients to perform multiple proximal operations to handle non-smooth terms and their performance are often susceptible to data heterogeneity. To overcome these limitations, we propose a novel composite federated learning algorithm called \textbf{FedCanon}, designed to solve the optimization problems comprising a possibly non-convex loss function and a weakly convex, potentially non-smooth regularization term. By decoupling proximal mappings from local updates, FedCanon requires only a single proximal evaluation on the server per iteration, thereby reducing the overall proximal computation cost. It also introduces control variables that incorporate global gradient information into client updates, which helps mitigate the effects of data heterogeneity. Theoretical analysis demonstrates that FedCanon achieves sublinear convergence rates under general non-convex settings and linear convergence under the Polyak-{\L}ojasiewicz condition, without relying on bounded heterogeneity assumptions. Experiments demonstrate that FedCanon outperforms the state-of-the-art methods in terms of both accuracy and computational efficiency, particularly under heterogeneous data distributions.
Optimal Parameter Adaptation for Safety-Critical Control via Safe Barrier Bayesian Optimization
Mar 25, 2025Safety is of paramount importance in control systems to avoid costly risks and catastrophic damages. The control barrier function (CBF) method, a promising solution for safety-critical control, poses a new challenge of enhancing control performance due to its direct modification of original control design and the introduction of uncalibrated parameters. In this work, we shed light on the crucial role of configurable parameters in the CBF method for performance enhancement with a systematical categorization. Based on that, we propose a novel framework combining the CBF method with Bayesian optimization (BO) to optimize the safe control performance. Considering feasibility/safety-critical constraints, we develop a safe version of BO using the barrier-based interior method to efficiently search for promising feasible configurable parameters. Furthermore, we provide theoretical criteria of our framework regarding safety and optimality. An essential advantage of our framework lies in that it can work in model-agnostic environments, leaving sufficient flexibility in designing objective and constraint functions. Finally, simulation experiments on swing-up control and high-fidelity adaptive cruise control are conducted to demonstrate the effectiveness of our framework.
Distributed Fractional Bayesian Learning for Adaptive Optimization
Apr 17, 2024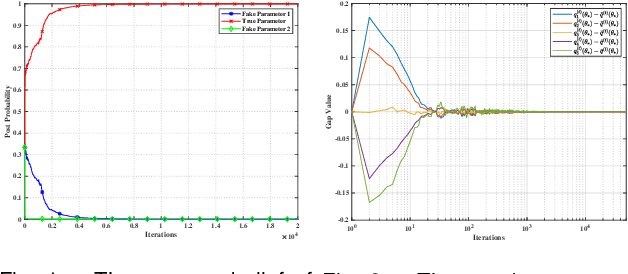
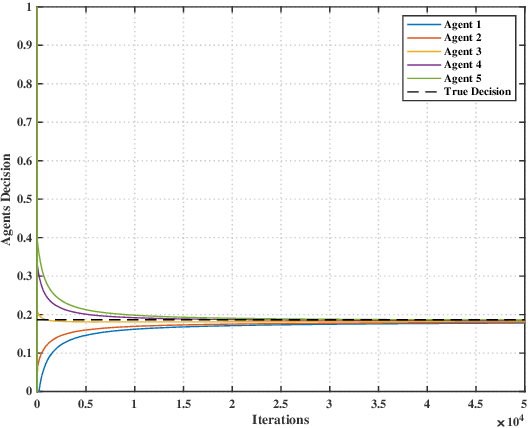
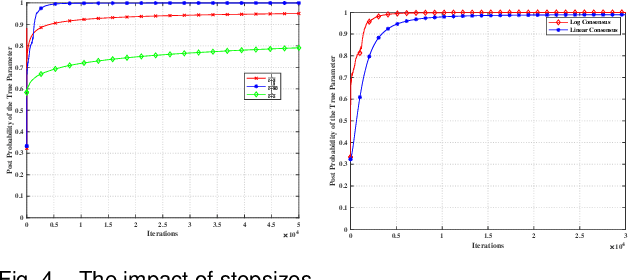
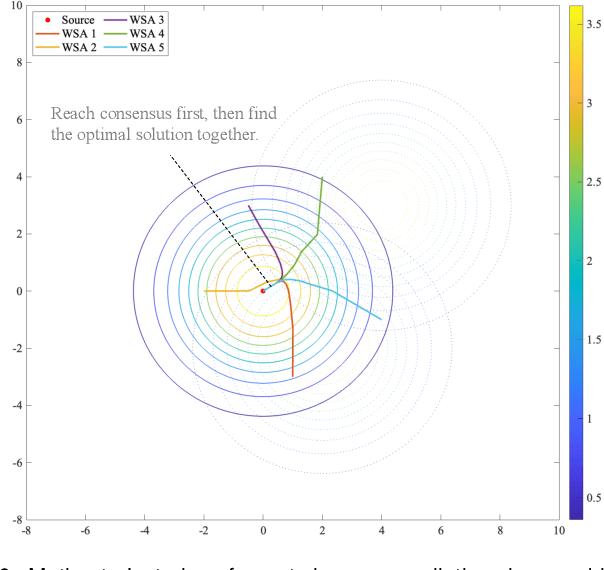
This paper considers a distributed adaptive optimization problem, where all agents only have access to their local cost functions with a common unknown parameter, whereas they mean to collaboratively estimate the true parameter and find the optimal solution over a connected network. A general mathematical framework for such a problem has not been studied yet. We aim to provide valuable insights for addressing parameter uncertainty in distributed optimization problems and simultaneously find the optimal solution. Thus, we propose a novel Prediction while Optimization scheme, which utilizes distributed fractional Bayesian learning through weighted averaging on the log-beliefs to update the beliefs of unknown parameters, and distributed gradient descent for renewing the estimation of the optimal solution. Then under suitable assumptions, we prove that all agents' beliefs and decision variables converge almost surely to the true parameter and the optimal solution under the true parameter, respectively. We further establish a sublinear convergence rate for the belief sequence. Finally, numerical experiments are implemented to corroborate the theoretical analysis.
Data-Driven Deep Learning Based Hybrid Beamforming for Aerial Massive MIMO-OFDM Systems with Implicit CSI
Feb 10, 2022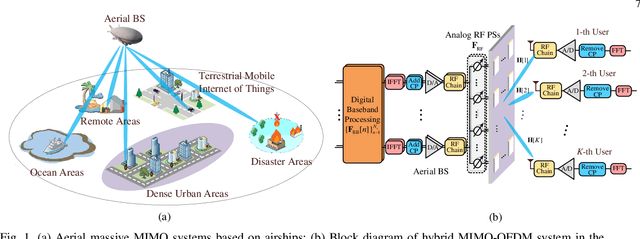
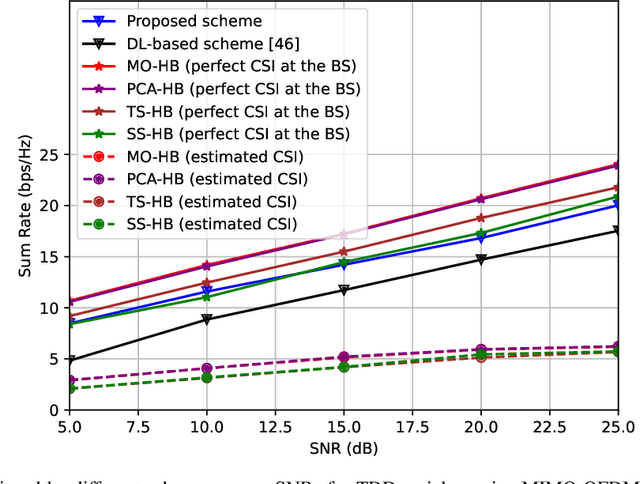
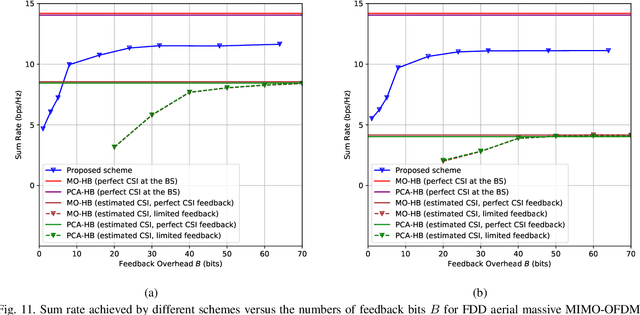
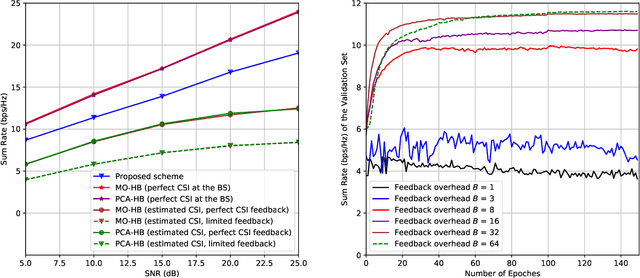
In an aerial hybrid massive multiple-input multiple-output (MIMO) and orthogonal frequency division multiplexing (OFDM) system, how to design a spectral-efficient broadband multi-user hybrid beamforming with a limited pilot and feedback overhead is challenging. To this end, by modeling the key transmission modules as an end-to-end (E2E) neural network, this paper proposes a data-driven deep learning (DL)-based unified hybrid beamforming framework for both the time division duplex (TDD) and frequency division duplex (FDD) systems with implicit channel state information (CSI). For TDD systems, the proposed DL-based approach jointly models the uplink pilot combining and downlink hybrid beamforming modules as an E2E neural network. While for FDD systems, we jointly model the downlink pilot transmission, uplink CSI feedback, and downlink hybrid beamforming modules as an E2E neural network. Different from conventional approaches separately processing different modules, the proposed solution simultaneously optimizes all modules with the sum rate as the optimization object. Therefore, by perceiving the inherent property of air-to-ground massive MIMO-OFDM channel samples, the DL-based E2E neural network can establish the mapping function from the channel to the beamformer, so that the explicit channel reconstruction can be avoided with reduced pilot and feedback overhead. Besides, practical low-resolution phase shifters (PSs) introduce the quantization constraint, leading to the intractable gradient backpropagation when training the neural network. To mitigate the performance loss caused by the phase quantization error, we adopt the transfer learning strategy to further fine-tune the E2E neural network based on a pre-trained network that assumes the ideal infinite-resolution PSs. Numerical results show that our DL-based schemes have considerable advantages over state-of-the-art schemes.