 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGame-Theoretic Safe Multi-Agent Motion Planning with Reachability Analysis for Dynamic and Uncertain Environments (Extended Version)
Nov 15, 2025Ensuring safe, robust, and scalable motion planning for multi-agent systems in dynamic and uncertain environments is a persistent challenge, driven by complex inter-agent interactions, stochastic disturbances, and model uncertainties. To overcome these challenges, particularly the computational complexity of coupled decision-making and the need for proactive safety guarantees, we propose a Reachability-Enhanced Dynamic Potential Game (RE-DPG) framework, which integrates game-theoretic coordination into reachability analysis. This approach formulates multi-agent coordination as a dynamic potential game, where the Nash equilibrium (NE) defines optimal control strategies across agents. To enable scalability and decentralized execution, we develop a Neighborhood-Dominated iterative Best Response (ND-iBR) scheme, built upon an iterated $\varepsilon$-BR (i$\varepsilon$-BR) process that guarantees finite-step convergence to an $\varepsilon$-NE. This allows agents to compute strategies based on local interactions while ensuring theoretical convergence guarantees. Furthermore, to ensure safety under uncertainty, we integrate a Multi-Agent Forward Reachable Set (MA-FRS) mechanism into the cost function, explicitly modeling uncertainty propagation and enforcing collision avoidance constraints. Through both simulations and real-world experiments in 2D and 3D environments, we validate the effectiveness of RE-DPG across diverse operational scenarios.
One-Point Sampling for Distributed Bandit Convex Optimization with Time-Varying Constraints
Apr 24, 2025This paper considers the distributed bandit convex optimization problem with time-varying constraints. In this problem, the global loss function is the average of all the local convex loss functions, which are unknown beforehand. Each agent iteratively makes its own decision subject to time-varying inequality constraints which can be violated but are fulfilled in the long run. For a uniformly jointly strongly connected time-varying directed graph, a distributed bandit online primal-dual projection algorithm with one-point sampling is proposed. We show that sublinear dynamic network regret and network cumulative constraint violation are achieved if the path-length of the benchmark also increases in a sublinear manner. In addition, an $\mathcal{O}({T^{3/4 + g}})$ static network regret bound and an $\mathcal{O}( {{T^{1 - {g}/2}}} )$ network cumulative constraint violation bound are established, where $T$ is the total number of iterations and $g \in ( {0,1/4} )$ is a trade-off parameter. Moreover, a reduced static network regret bound $\mathcal{O}( {{T^{2/3 + 4g /3}}} )$ is established for strongly convex local loss functions. Finally, a numerical example is presented to validate the theoretical results.
Risk-averse Learning with Non-Stationary Distributions
Apr 03, 2024



Considering non-stationary environments in online optimization enables decision-maker to effectively adapt to changes and improve its performance over time. In such cases, it is favorable to adopt a strategy that minimizes the negative impact of change to avoid potentially risky situations. In this paper, we investigate risk-averse online optimization where the distribution of the random cost changes over time. We minimize risk-averse objective function using the Conditional Value at Risk (CVaR) as risk measure. Due to the difficulty in obtaining the exact CVaR gradient, we employ a zeroth-order optimization approach that queries the cost function values multiple times at each iteration and estimates the CVaR gradient using the sampled values. To facilitate the regret analysis, we use a variation metric based on Wasserstein distance to capture time-varying distributions. Given that the distribution variation is sub-linear in the total number of episodes, we show that our designed learning algorithm achieves sub-linear dynamic regret with high probability for both convex and strongly convex functions. Moreover, theoretical results suggest that increasing the number of samples leads to a reduction in the dynamic regret bounds until the sampling number reaches a specific limit. Finally, we provide numerical experiments of dynamic pricing in a parking lot to illustrate the efficacy of the designed algorithm.
Neural optimal controller for stochastic systems via pathwise HJB operator
Feb 23, 2024



The aim of this work is to develop deep learning-based algorithms for high-dimensional stochastic control problems based on physics-informed learning and dynamic programming. Unlike classical deep learning-based methods relying on a probabilistic representation of the solution to the Hamilton--Jacobi--Bellman (HJB) equation, we introduce a pathwise operator associated with the HJB equation so that we can define a problem of physics-informed learning. According to whether the optimal control has an explicit representation, two numerical methods are proposed to solve the physics-informed learning problem. We provide an error analysis on how the truncation, approximation and optimization errors affect the accuracy of these methods. Numerical results on various applications are presented to illustrate the performance of the proposed algorithms.
Distributed Online Convex Optimization with Adversarial Constraints: Reduced Cumulative Constraint Violation Bounds under Slater's Condition
May 31, 2023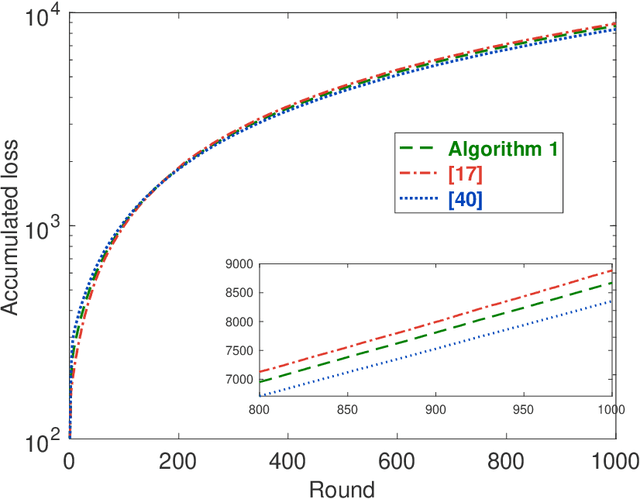
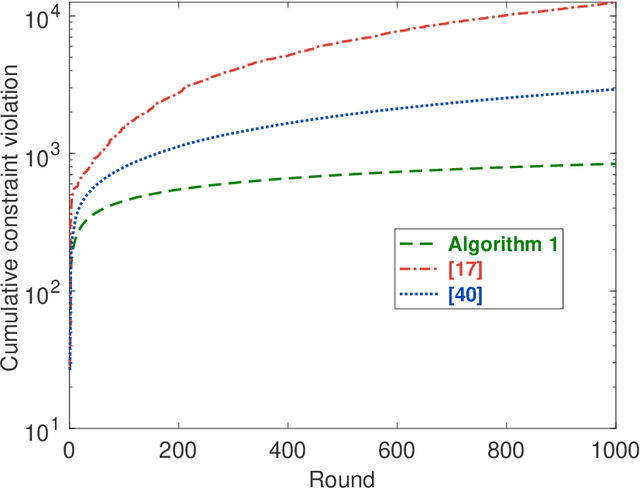
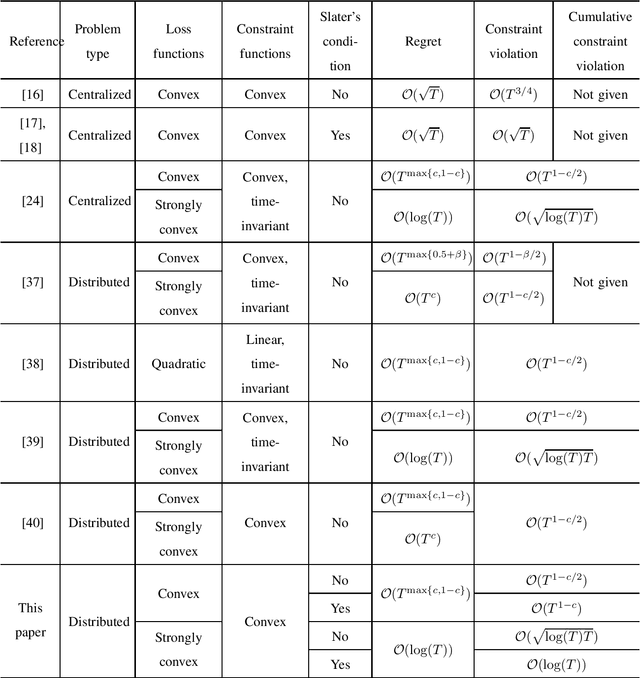

This paper considers distributed online convex optimization with adversarial constraints. In this setting, a network of agents makes decisions at each round, and then only a portion of the loss function and a coordinate block of the constraint function are privately revealed to each agent. The loss and constraint functions are convex and can vary arbitrarily across rounds. The agents collaborate to minimize network regret and cumulative constraint violation. A novel distributed online algorithm is proposed and it achieves an $\mathcal{O}(T^{\max\{c,1-c\}})$ network regret bound and an $\mathcal{O}(T^{1-c/2})$ network cumulative constraint violation bound, where $T$ is the number of rounds and $c\in(0,1)$ is a user-defined trade-off parameter. When Slater's condition holds (i.e, there is a point that strictly satisfies the inequality constraints), the network cumulative constraint violation bound is reduced to $\mathcal{O}(T^{1-c})$. Moreover, if the loss functions are strongly convex, then the network regret bound is reduced to $\mathcal{O}(\log(T))$, and the network cumulative constraint violation bound is reduced to $\mathcal{O}(\sqrt{\log(T)T})$ and $\mathcal{O}(\log(T))$ without and with Slater's condition, respectively. To the best of our knowledge, this paper is the first to achieve reduced (network) cumulative constraint violation bounds for (distributed) online convex optimization with adversarial constraints under Slater's condition. Finally, the theoretical results are verified through numerical simulations.
DeFed: A Principled Decentralized and Privacy-Preserving Federated Learning Algorithm
Jul 15, 2021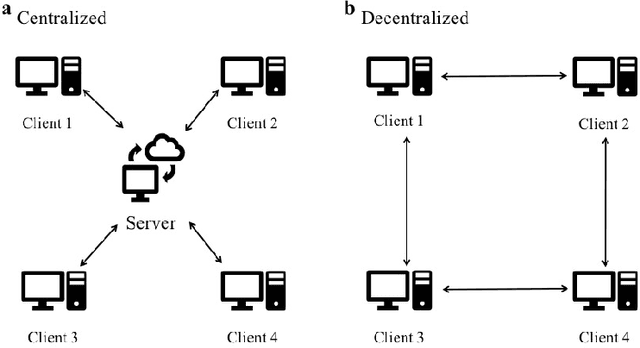
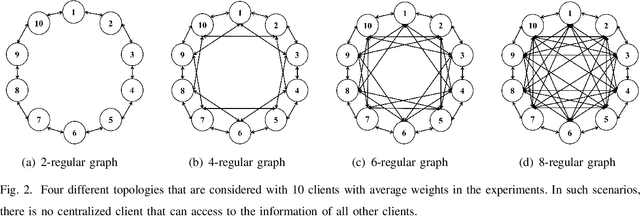
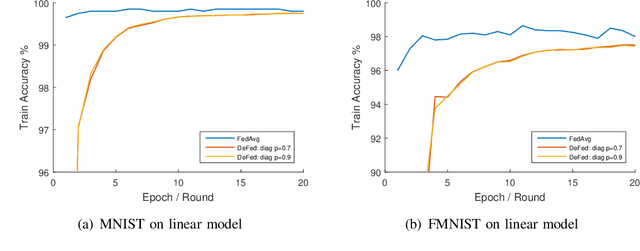
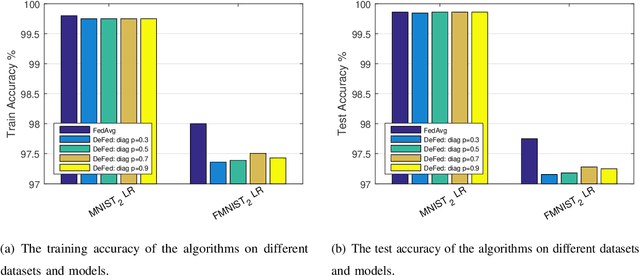
Federated learning enables a large number of clients to participate in learning a shared model while maintaining the training data stored in each client, which protects data privacy and security. Till now, federated learning frameworks are built in a centralized way, in which a central client is needed for collecting and distributing information from every other client. This not only leads to high communication pressure at the central client, but also renders the central client highly vulnerable to failure and attack. Here we propose a principled decentralized federated learning algorithm (DeFed), which removes the central client in the classical Federated Averaging (FedAvg) setting and only relies information transmission between clients and their local neighbors. The proposed DeFed algorithm is proven to reach the global minimum with a convergence rate of $O(1/T)$ when the loss function is smooth and strongly convex, where $T$ is the number of iterations in gradient descent. Finally, the proposed algorithm has been applied to a number of toy examples to demonstrate its effectiveness.
Regret and Cumulative Constraint Violation Analysis for Online Convex Optimization with Long Term Constraints
Jun 09, 2021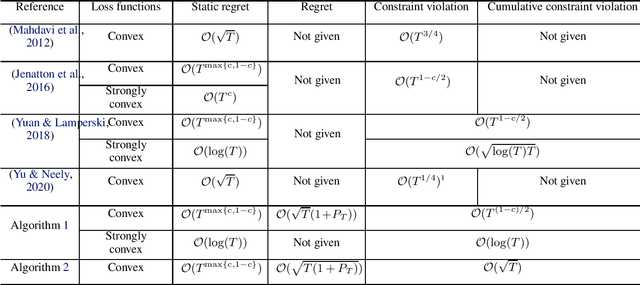
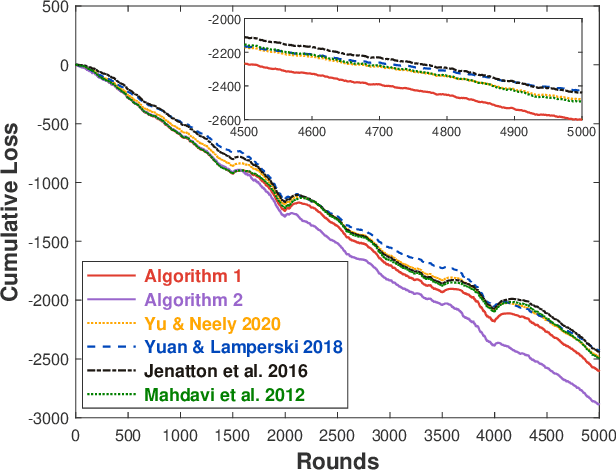
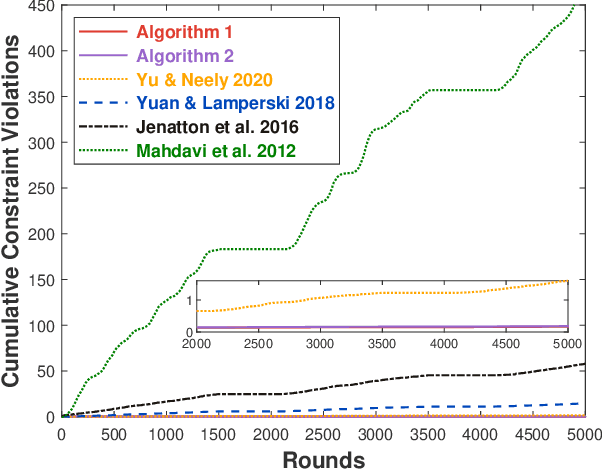
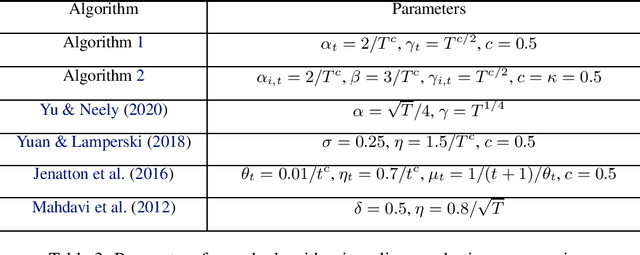
This paper considers online convex optimization with long term constraints, where constraints can be violated in intermediate rounds, but need to be satisfied in the long run. The cumulative constraint violation is used as the metric to measure constraint violations, which excludes the situation that strictly feasible constraints can compensate the effects of violated constraints. A novel algorithm is first proposed and it achieves an $\mathcal{O}(T^{\max\{c,1-c\}})$ bound for static regret and an $\mathcal{O}(T^{(1-c)/2})$ bound for cumulative constraint violation, where $c\in(0,1)$ is a user-defined trade-off parameter, and thus has improved performance compared with existing results. Both static regret and cumulative constraint violation bounds are reduced to $\mathcal{O}(\log(T))$ when the loss functions are strongly convex, which also improves existing results. %In order to bound the regret with respect to any comparator sequence, In order to achieve the optimal regret with respect to any comparator sequence, another algorithm is then proposed and it achieves the optimal $\mathcal{O}(\sqrt{T(1+P_T)})$ regret and an $\mathcal{O}(\sqrt{T})$ cumulative constraint violation, where $P_T$ is the path-length of the comparator sequence. Finally, numerical simulations are provided to illustrate the effectiveness of the theoretical results.
Regret and Cumulative Constraint Violation Analysis for Distributed Online Constrained Convex Optimization
May 01, 2021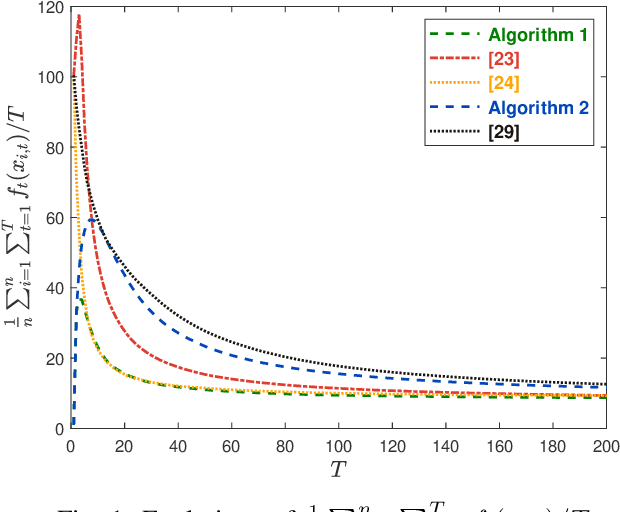
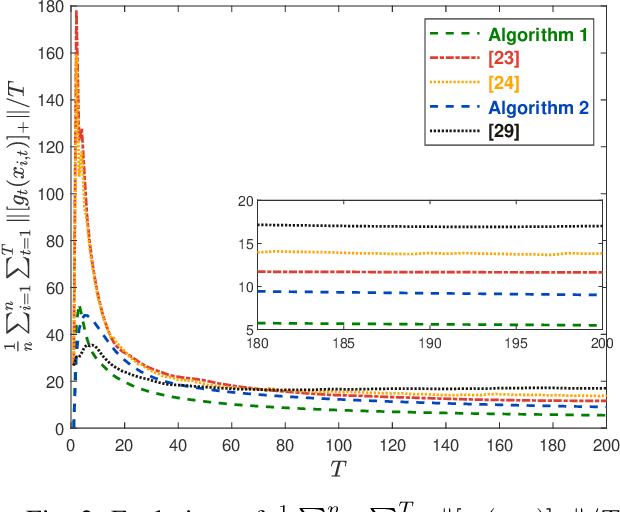
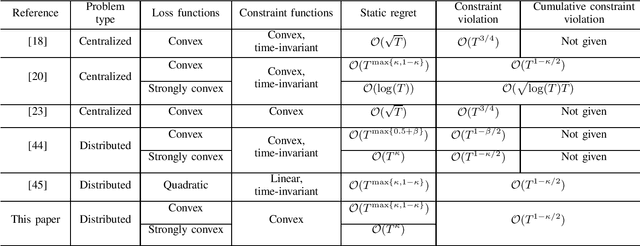
This paper considers the distributed online convex optimization problem with time-varying constraints over a network of agents. This is a sequential decision making problem with two sequences of arbitrarily varying convex loss and constraint functions. At each round, each agent selects a decision from the decision set, and then only a portion of the loss function and a coordinate block of the constraint function at this round are privately revealed to this agent. The goal of the network is to minimize network regret and constraint violation. Two distributed online algorithms with full-information and bandit feedback are proposed. Both dynamic and static network regret bounds are analyzed for the proposed algorithms, and network cumulative constraint violation is used to measure constraint violation, which excludes the situation that strictly feasible constraints can compensate the effects of violated constraints. In particular, we show that the proposed algorithms achieve $\mathcal{O}(T^{\max\{\kappa,1-\kappa\}})$ static network regret and $\mathcal{O}(T^{1-\kappa/2})$ network cumulative constraint violation, where $T$ is the total number of rounds and $\kappa\in(0,1)$ is a user-defined trade-off parameter. Moreover, if the loss functions are strongly convex, then the static network regret bound can be reduced to $\mathcal{O}(T^{\kappa})$. Finally, numerical simulations are provided to illustrate the effectiveness of the theoretical results.
Distributed Online Convex Optimization with Time-Varying Coupled Inequality Constraints
Mar 06, 2019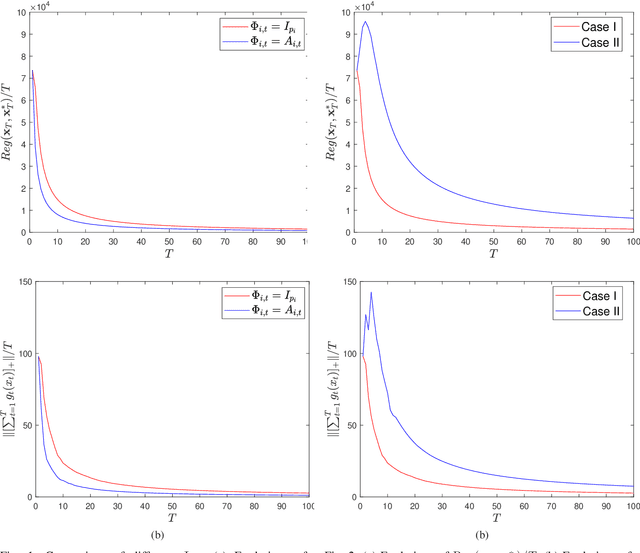
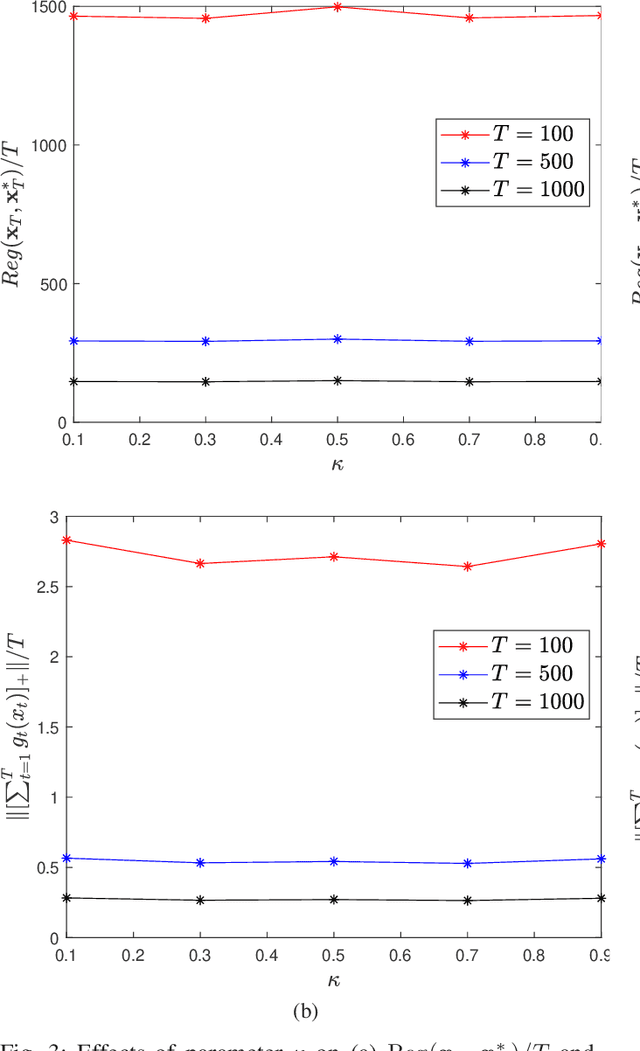
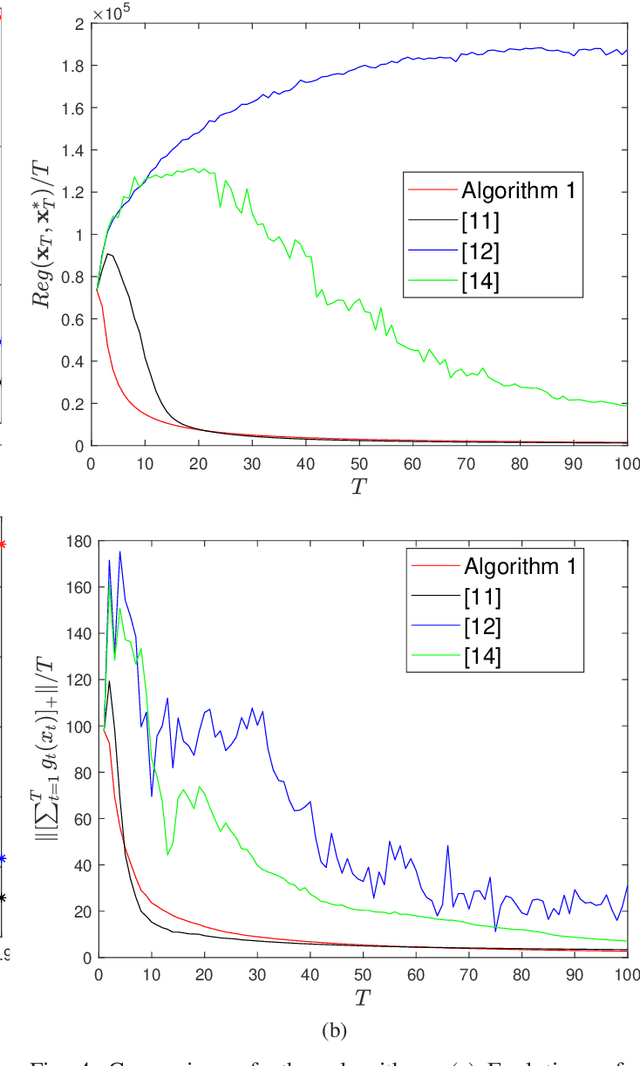

This paper considers distributed online optimization with time-varying coupled inequality constraints. The global objective function is composed of local convex cost and regularization functions and the coupled constraint function is the sum of local convex constraint functions. A distributed online primal-dual dynamic mirror descent algorithm is proposed to solve this problem, where the local cost, regularization, and constraint functions are held privately and revealed only after each time slot. We first derive regret and cumulative constraint violation bounds for the algorithm and show how they depend on the stepsize sequences, the accumulated dynamic variation of the comparator sequence, the number of agents, and the network connectivity. As a result, under some natural decreasing stepsize sequences, we prove that the algorithm achieves sublinear dynamic regret and cumulative constraint violation if the accumulated dynamic variation of the optimal sequence also grows sublinearly. We also prove that the algorithm achieves sublinear static regret and cumulative constraint violation under mild conditions. In addition, smaller bounds on the static regret are achieved when the objective functions are strongly convex. Finally, numerical simulations are provided to illustrate the effectiveness of the theoretical results.
Stability of Analytic Neural Networks with Event-triggered Synaptic Feedbacks
Apr 02, 2016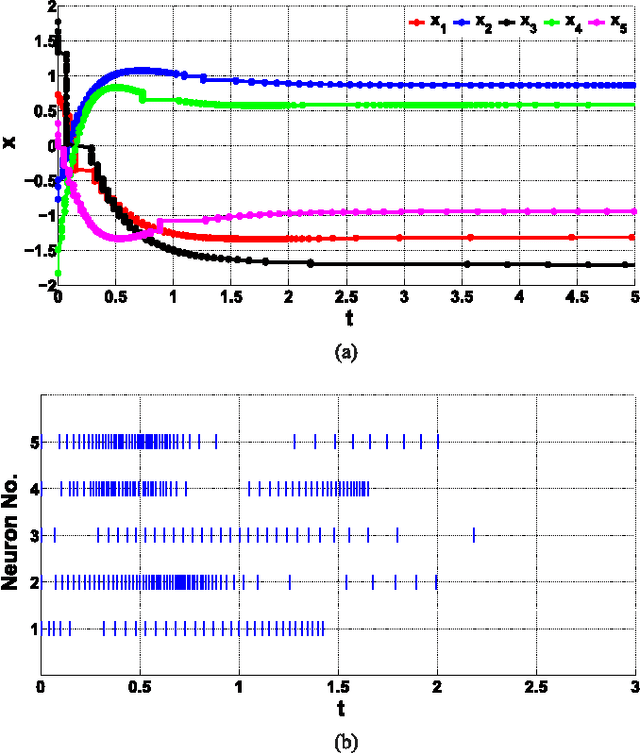
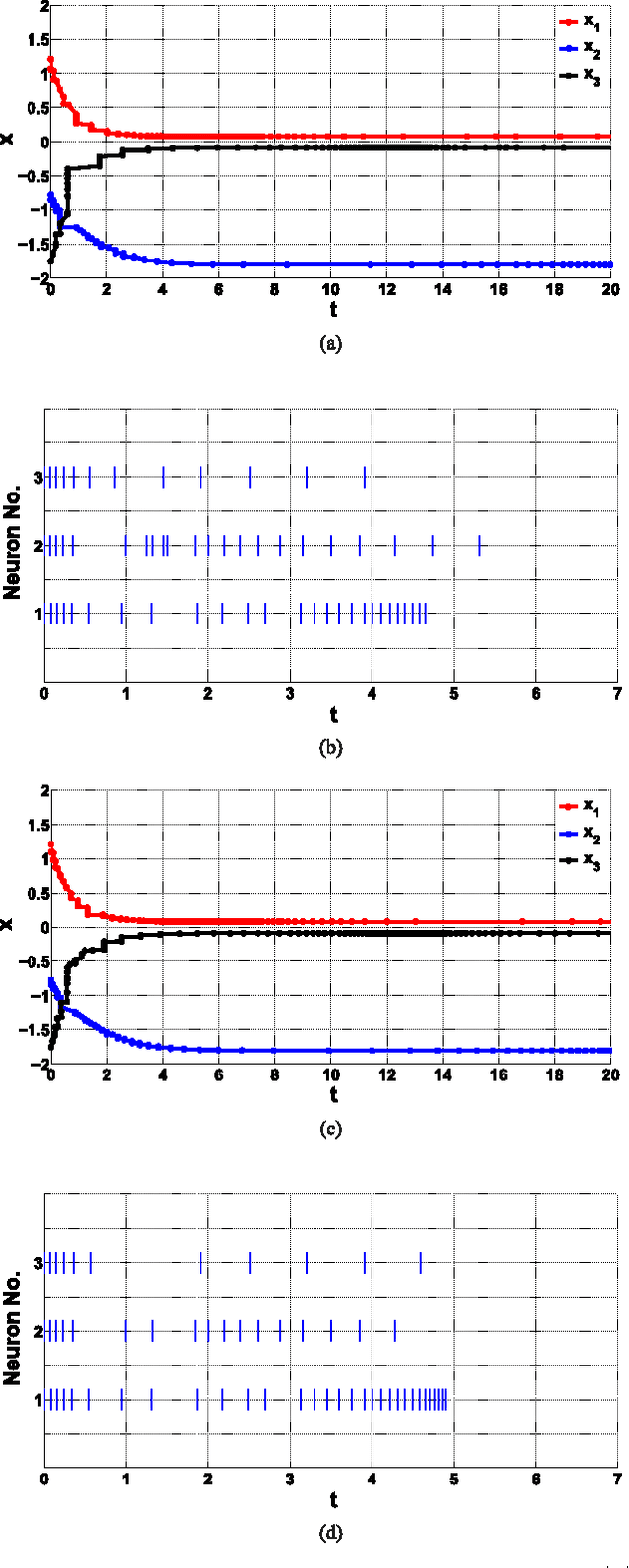
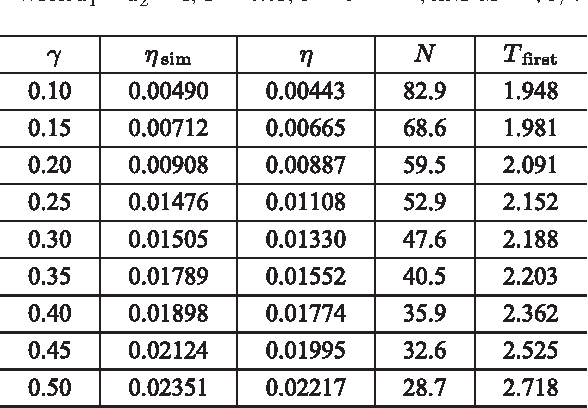
In this paper, we investigate stability of a class of analytic neural networks with the synaptic feedback via event-triggered rules. This model is general and include Hopfield neural network as a special case. These event-trigger rules can efficiently reduces loads of computation and information transmission at synapses of the neurons. The synaptic feedback of each neuron keeps a constant value based on the outputs of the other neurons at its latest triggering time but changes at its next triggering time, which is determined by certain criterion. It is proved that every trajectory of the analytic neural network converges to certain equilibrium under this event-triggered rule for all initial values except a set of zero measure. The main technique of the proof is the Lojasiewicz inequality to prove the finiteness of trajectory length. The realization of this event-triggered rule is verified by the exclusion of Zeno behaviors. Numerical examples are provided to illustrate the efficiency of the theoretical results.
* 12 pages, 3 figures. arXiv admin note: substantial text overlap with arXiv:1504.08081