 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Agentic AI System for Multi-Framework Communication Coding
Dec 09, 2025Clinical communication is central to patient outcomes, yet large-scale human annotation of patient-provider conversation remains labor-intensive, inconsistent, and difficult to scale. Existing approaches based on large language models typically rely on single-task models that lack adaptability, interpretability, and reliability, especially when applied across various communication frameworks and clinical domains. In this study, we developed a Multi-framework Structured Agentic AI system for Clinical Communication (MOSAIC), built on a LangGraph-based architecture that orchestrates four core agents, including a Plan Agent for codebook selection and workflow planning, an Update Agent for maintaining up-to-date retrieval databases, a set of Annotation Agents that applies codebook-guided retrieval-augmented generation (RAG) with dynamic few-shot prompting, and a Verification Agent that provides consistency checks and feedback. To evaluate performance, we compared MOSAIC outputs against gold-standard annotations created by trained human coders. We developed and evaluated MOSAIC using 26 gold standard annotated transcripts for training and 50 transcripts for testing, spanning rheumatology and OB/GYN domains. On the test set, MOSAIC achieved an overall F1 score of 0.928. Performance was highest in the Rheumatology subset (F1 = 0.962) and strongest for Patient Behavior (e.g., patients asking questions, expressing preferences, or showing assertiveness). Ablations revealed that MOSAIC outperforms baseline benchmarking.
Wasserstein Distributionally Robust Nash Equilibrium Seeking with Heterogeneous Data: A Lagrangian Approach
Nov 18, 2025We study a class of distributionally robust games where agents are allowed to heterogeneously choose their risk aversion with respect to distributional shifts of the uncertainty. In our formulation, heterogeneous Wasserstein ball constraints on each distribution are enforced through a penalty function leveraging a Lagrangian formulation. We then formulate the distributionally robust Nash equilibrium problem and show that under certain assumptions it is equivalent to a finite-dimensional variational inequality problem with a strongly monotone mapping. We then design an approximate Nash equilibrium seeking algorithm and prove convergence of the average regret to a quantity that diminishes with the number of iterations, thus learning the desired equilibrium up to an a priori specified accuracy. Numerical simulations corroborate our theoretical findings.
Group Distributionally Robust Machine Learning under Group Level Distributional Uncertainty
Sep 10, 2025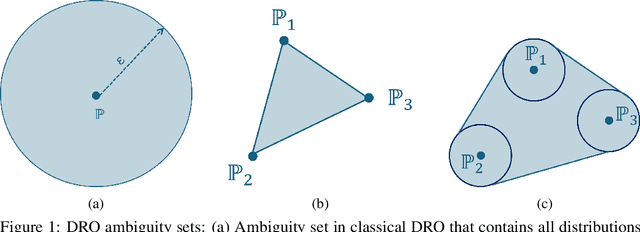

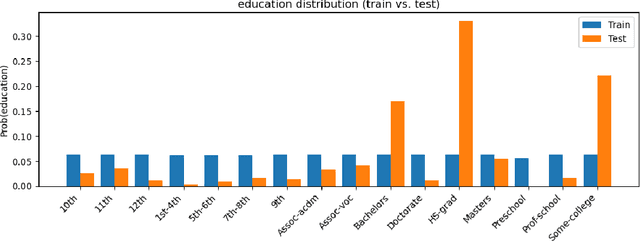
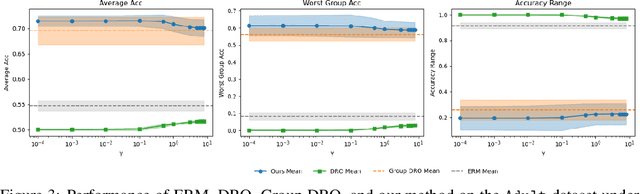
The performance of machine learning (ML) models critically depends on the quality and representativeness of the training data. In applications with multiple heterogeneous data generating sources, standard ML methods often learn spurious correlations that perform well on average but degrade performance for atypical or underrepresented groups. Prior work addresses this issue by optimizing the worst-group performance. However, these approaches typically assume that the underlying data distributions for each group can be accurately estimated using the training data, a condition that is frequently violated in noisy, non-stationary, and evolving environments. In this work, we propose a novel framework that relies on Wasserstein-based distributionally robust optimization (DRO) to account for the distributional uncertainty within each group, while simultaneously preserving the objective of improving the worst-group performance. We develop a gradient descent-ascent algorithm to solve the proposed DRO problem and provide convergence results. Finally, we validate the effectiveness of our method on real-world data.
Source-Guided Flow Matching
Aug 20, 2025Guidance of generative models is typically achieved by modifying the probability flow vector field through the addition of a guidance field. In this paper, we instead propose the Source-Guided Flow Matching (SGFM) framework, which modifies the source distribution directly while keeping the pre-trained vector field intact. This reduces the guidance problem to a well-defined problem of sampling from the source distribution. We theoretically show that SGFM recovers the desired target distribution exactly. Furthermore, we provide bounds on the Wasserstein error for the generated distribution when using an approximate sampler of the source distribution and an approximate vector field. The key benefit of our approach is that it allows the user to flexibly choose the sampling method depending on their specific problem. To illustrate this, we systematically compare different sampling methods and discuss conditions for asymptotically exact guidance. Moreover, our framework integrates well with optimal flow matching models since the straight transport map generated by the vector field is preserved. Experimental results on synthetic 2D benchmarks, image datasets, and physics-informed generative tasks demonstrate the effectiveness and flexibility of the proposed framework.
FairPOT: Balancing AUC Performance and Fairness with Proportional Optimal Transport
Aug 05, 2025Fairness metrics utilizing the area under the receiver operator characteristic curve (AUC) have gained increasing attention in high-stakes domains such as healthcare, finance, and criminal justice. In these domains, fairness is often evaluated over risk scores rather than binary outcomes, and a common challenge is that enforcing strict fairness can significantly degrade AUC performance. To address this challenge, we propose Fair Proportional Optimal Transport (FairPOT), a novel, model-agnostic post-processing framework that strategically aligns risk score distributions across different groups using optimal transport, but does so selectively by transforming a controllable proportion, i.e., the top-lambda quantile, of scores within the disadvantaged group. By varying lambda, our method allows for a tunable trade-off between reducing AUC disparities and maintaining overall AUC performance. Furthermore, we extend FairPOT to the partial AUC setting, enabling fairness interventions to concentrate on the highest-risk regions. Extensive experiments on synthetic, public, and clinical datasets show that FairPOT consistently outperforms existing post-processing techniques in both global and partial AUC scenarios, often achieving improved fairness with slight AUC degradation or even positive gains in utility. The computational efficiency and practical adaptability of FairPOT make it a promising solution for real-world deployment.
Enhancing Cooperative Multi-Agent Reinforcement Learning with State Modelling and Adversarial Exploration
May 08, 2025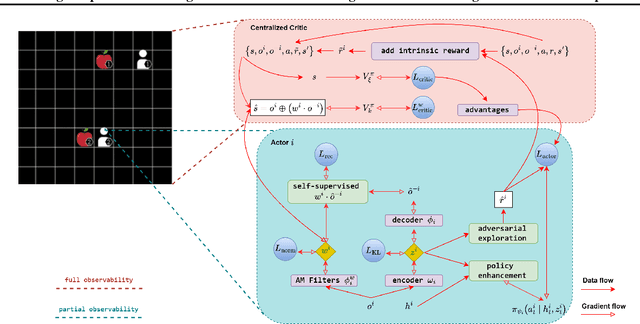


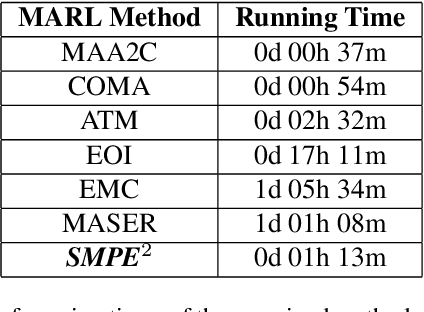
Learning to cooperate in distributed partially observable environments with no communication abilities poses significant challenges for multi-agent deep reinforcement learning (MARL). This paper addresses key concerns in this domain, focusing on inferring state representations from individual agent observations and leveraging these representations to enhance agents' exploration and collaborative task execution policies. To this end, we propose a novel state modelling framework for cooperative MARL, where agents infer meaningful belief representations of the non-observable state, with respect to optimizing their own policies, while filtering redundant and less informative joint state information. Building upon this framework, we propose the MARL SMPE algorithm. In SMPE, agents enhance their own policy's discriminative abilities under partial observability, explicitly by incorporating their beliefs into the policy network, and implicitly by adopting an adversarial type of exploration policies which encourages agents to discover novel, high-value states while improving the discriminative abilities of others. Experimentally, we show that SMPE outperforms state-of-the-art MARL algorithms in complex fully cooperative tasks from the MPE, LBF, and RWARE benchmarks.
LAPP: Large Language Model Feedback for Preference-Driven Reinforcement Learning
Apr 21, 2025We introduce Large Language Model-Assisted Preference Prediction (LAPP), a novel framework for robot learning that enables efficient, customizable, and expressive behavior acquisition with minimum human effort. Unlike prior approaches that rely heavily on reward engineering, human demonstrations, motion capture, or expensive pairwise preference labels, LAPP leverages large language models (LLMs) to automatically generate preference labels from raw state-action trajectories collected during reinforcement learning (RL). These labels are used to train an online preference predictor, which in turn guides the policy optimization process toward satisfying high-level behavioral specifications provided by humans. Our key technical contribution is the integration of LLMs into the RL feedback loop through trajectory-level preference prediction, enabling robots to acquire complex skills including subtle control over gait patterns and rhythmic timing. We evaluate LAPP on a diverse set of quadruped locomotion and dexterous manipulation tasks and show that it achieves efficient learning, higher final performance, faster adaptation, and precise control of high-level behaviors. Notably, LAPP enables robots to master highly dynamic and expressive tasks such as quadruped backflips, which remain out of reach for standard LLM-generated or handcrafted rewards. Our results highlight LAPP as a promising direction for scalable preference-driven robot learning.
Distributionally Robust Multi-Agent Reinforcement Learning for Dynamic Chute Mapping
Mar 12, 2025In Amazon robotic warehouses, the destination-to-chute mapping problem is crucial for efficient package sorting. Often, however, this problem is complicated by uncertain and dynamic package induction rates, which can lead to increased package recirculation. To tackle this challenge, we introduce a Distributionally Robust Multi-Agent Reinforcement Learning (DRMARL) framework that learns a destination-to-chute mapping policy that is resilient to adversarial variations in induction rates. Specifically, DRMARL relies on group distributionally robust optimization (DRO) to learn a policy that performs well not only on average but also on each individual subpopulation of induction rates within the group that capture, for example, different seasonality or operation modes of the system. This approach is then combined with a novel contextual bandit-based predictor of the worst-case induction distribution for each state-action pair, significantly reducing the cost of exploration and thereby increasing the learning efficiency and scalability of our framework. Extensive simulations demonstrate that DRMARL achieves robust chute mapping in the presence of varying induction distributions, reducing package recirculation by an average of 80\% in the simulation scenario.
Inverse Reinforcement Learning from Non-Stationary Learning Agents
Oct 18, 2024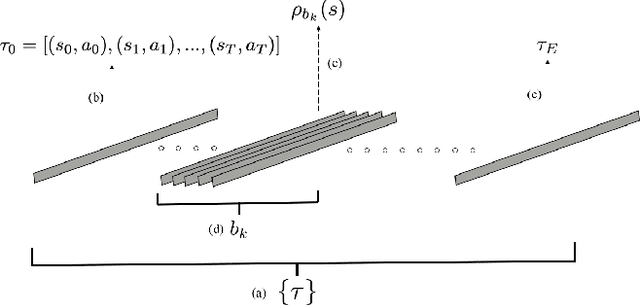

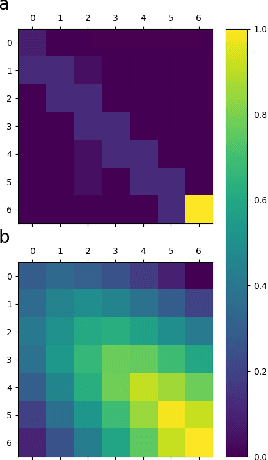
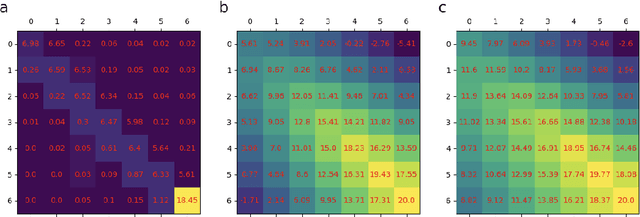
In this paper, we study an inverse reinforcement learning problem that involves learning the reward function of a learning agent using trajectory data collected while this agent is learning its optimal policy. To address this problem, we propose an inverse reinforcement learning method that allows us to estimate the policy parameters of the learning agent which can then be used to estimate its reward function. Our method relies on a new variant of the behavior cloning algorithm, which we call bundle behavior cloning, and uses a small number of trajectories generated by the learning agent's policy at different points in time to learn a set of policies that match the distribution of actions observed in the sampled trajectories. We then use the cloned policies to train a neural network model that estimates the reward function of the learning agent. We provide a theoretical analysis to show a complexity result on bound guarantees for our method that beats standard behavior cloning as well as numerical experiments for a reinforcement learning problem that validate the proposed method.
Transfer Reinforcement Learning in Heterogeneous Action Spaces using Subgoal Mapping
Oct 18, 2024

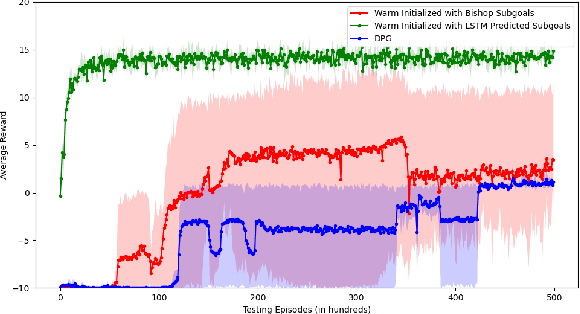
In this paper, we consider a transfer reinforcement learning problem involving agents with different action spaces. Specifically, for any new unseen task, the goal is to use a successful demonstration of this task by an expert agent in its action space to enable a learner agent learn an optimal policy in its own different action space with fewer samples than those required if the learner was learning on its own. Existing transfer learning methods across different action spaces either require handcrafted mappings between those action spaces provided by human experts, which can induce bias in the learning procedure, or require the expert agent to share its policy parameters with the learner agent, which does not generalize well to unseen tasks. In this work, we propose a method that learns a subgoal mapping between the expert agent policy and the learner agent policy. Since the expert agent and the learner agent have different action spaces, their optimal policies can have different subgoal trajectories. We learn this subgoal mapping by training a Long Short Term Memory (LSTM) network for a distribution of tasks and then use this mapping to predict the learner subgoal sequence for unseen tasks, thereby improving the speed of learning by biasing the agent's policy towards the predicted learner subgoal sequence. Through numerical experiments, we demonstrate that the proposed learning scheme can effectively find the subgoal mapping underlying the given distribution of tasks. Moreover, letting the learner agent imitate the expert agent's policy with the learnt subgoal mapping can significantly improve the sample efficiency and training time of the learner agent in unseen new tasks.