 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGreekMMLU: A Native-Sourced Multitask Benchmark for Evaluating Language Models in Greek
Feb 05, 2026Large Language Models (LLMs) are commonly trained on multilingual corpora that include Greek, yet reliable evaluation benchmarks for Greek-particularly those based on authentic, native-sourced content-remain limited. Existing datasets are often machine-translated from English, failing to capture Greek linguistic and cultural characteristics. We introduce GreekMMLU, a native-sourced benchmark for massive multitask language understanding in Greek, comprising 21,805 multiple-choice questions across 45 subject areas, organized under a newly defined subject taxonomy and annotated with educational difficulty levels spanning primary to professional examinations. All questions are sourced or authored in Greek from academic, professional, and governmental exams. We publicly release 16,857 samples and reserve 4,948 samples for a private leaderboard to enable robust and contamination-resistant evaluation. Evaluations of over 80 open- and closed-source LLMs reveal substantial performance gaps between frontier and open-weight models, as well as between Greek-adapted models and general multilingual ones. Finally, we provide a systematic analysis of factors influencing performance-including model scale, adaptation, and prompting-and derive insights for improving LLM capabilities in Greek.
Through the PRISm: Importance-Aware Scene Graphs for Image Retrieval
Dec 20, 2025Accurately retrieving images that are semantically similar remains a fundamental challenge in computer vision, as traditional methods often fail to capture the relational and contextual nuances of a scene. We introduce PRISm (Pruning-based Image Retrieval via Importance Prediction on Semantic Graphs), a multimodal framework that advances image-to-image retrieval through two novel components. First, the Importance Prediction Module identifies and retains the most critical objects and relational triplets within an image while pruning irrelevant elements. Second, the Edge-Aware Graph Neural Network explicitly encodes relational structure and integrates global visual features to produce semantically informed image embeddings. PRISm achieves image retrieval that closely aligns with human perception by explicitly modeling the semantic importance of objects and their interactions, capabilities largely absent in prior approaches. Its architecture effectively combines relational reasoning with visual representation, enabling semantically grounded retrieval. Extensive experiments on benchmark and real-world datasets demonstrate consistently superior top-ranked performance, while qualitative analyses show that PRISm accurately captures key objects and interactions, producing interpretable and semantically meaningful results.
Go witheFlow: Real-time Emotion Driven Audio Effects Modulation
Oct 02, 2025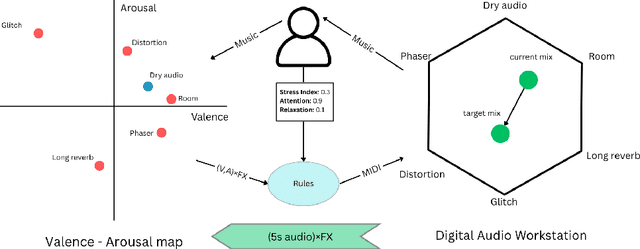

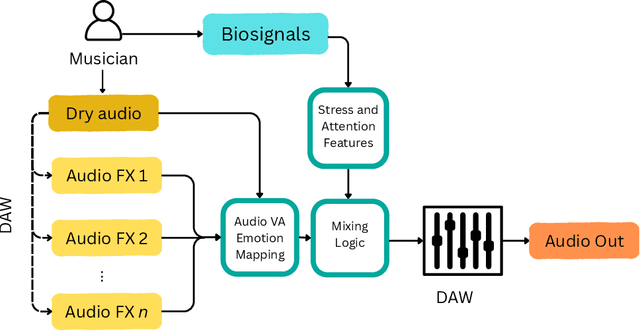
Music performance is a distinctly human activity, intrinsically linked to the performer's ability to convey, evoke, or express emotion. Machines cannot perform music in the human sense; they can produce, reproduce, execute, or synthesize music, but they lack the capacity for affective or emotional experience. As such, music performance is an ideal candidate through which to explore aspects of collaboration between humans and machines. In this paper, we introduce the witheFlow system, designed to enhance real-time music performance by automatically modulating audio effects based on features extracted from both biosignals and the audio itself. The system, currently in a proof-of-concept phase, is designed to be lightweight, able to run locally on a laptop, and is open-source given the availability of a compatible Digital Audio Workstation and sensors.
Exploring How Audio Effects Alter Emotion with Foundation Models
Sep 18, 2025Audio effects (FX) such as reverberation, distortion, modulation, and dynamic range processing play a pivotal role in shaping emotional responses during music listening. While prior studies have examined links between low-level audio features and affective perception, the systematic impact of audio FX on emotion remains underexplored. This work investigates how foundation models - large-scale neural architectures pretrained on multimodal data - can be leveraged to analyze these effects. Such models encode rich associations between musical structure, timbre, and affective meaning, offering a powerful framework for probing the emotional consequences of sound design techniques. By applying various probing methods to embeddings from deep learning models, we examine the complex, nonlinear relationships between audio FX and estimated emotion, uncovering patterns tied to specific effects and evaluating the robustness of foundation audio models. Our findings aim to advance understanding of the perceptual impact of audio production practices, with implications for music cognition, performance, and affective computing.
Don't Erase, Inform! Detecting and Contextualizing Harmful Language in Cultural Heritage Collections
May 30, 2025Cultural Heritage (CH) data hold invaluable knowledge, reflecting the history, traditions, and identities of societies, and shaping our understanding of the past and present. However, many CH collections contain outdated or offensive descriptions that reflect historical biases. CH Institutions (CHIs) face significant challenges in curating these data due to the vast scale and complexity of the task. To address this, we develop an AI-powered tool that detects offensive terms in CH metadata and provides contextual insights into their historical background and contemporary perception. We leverage a multilingual vocabulary co-created with marginalized communities, researchers, and CH professionals, along with traditional NLP techniques and Large Language Models (LLMs). Available as a standalone web app and integrated with major CH platforms, the tool has processed over 7.9 million records, contextualizing the contentious terms detected in their metadata. Rather than erasing these terms, our approach seeks to inform, making biases visible and providing actionable insights for creating more inclusive and accessible CH collections.
Semantic-Aware Interpretable Multimodal Music Auto-Tagging
May 26, 2025Music auto-tagging is essential for organizing and discovering music in extensive digital libraries. While foundation models achieve exceptional performance in this domain, their outputs often lack interpretability, limiting trust and usability for researchers and end-users alike. In this work, we present an interpretable framework for music auto-tagging that leverages groups of musically meaningful multimodal features, derived from signal processing, deep learning, ontology engineering, and natural language processing. To enhance interpretability, we cluster features semantically and employ an expectation maximization algorithm, assigning distinct weights to each group based on its contribution to the tagging process. Our method achieves competitive tagging performance while offering a deeper understanding of the decision-making process, paving the way for more transparent and user-centric music tagging systems.
SCENIR: Visual Semantic Clarity through Unsupervised Scene Graph Retrieval
May 21, 2025Despite the dominance of convolutional and transformer-based architectures in image-to-image retrieval, these models are prone to biases arising from low-level visual features, such as color. Recognizing the lack of semantic understanding as a key limitation, we propose a novel scene graph-based retrieval framework that emphasizes semantic content over superficial image characteristics. Prior approaches to scene graph retrieval predominantly rely on supervised Graph Neural Networks (GNNs), which require ground truth graph pairs driven from image captions. However, the inconsistency of caption-based supervision stemming from variable text encodings undermine retrieval reliability. To address these, we present SCENIR, a Graph Autoencoder-based unsupervised retrieval framework, which eliminates the dependence on labeled training data. Our model demonstrates superior performance across metrics and runtime efficiency, outperforming existing vision-based, multimodal, and supervised GNN approaches. We further advocate for Graph Edit Distance (GED) as a deterministic and robust ground truth measure for scene graph similarity, replacing the inconsistent caption-based alternatives for the first time in image-to-image retrieval evaluation. Finally, we validate the generalizability of our method by applying it to unannotated datasets via automated scene graph generation, while substantially contributing in advancing state-of-the-art in counterfactual image retrieval.
Enhancing Cooperative Multi-Agent Reinforcement Learning with State Modelling and Adversarial Exploration
May 08, 2025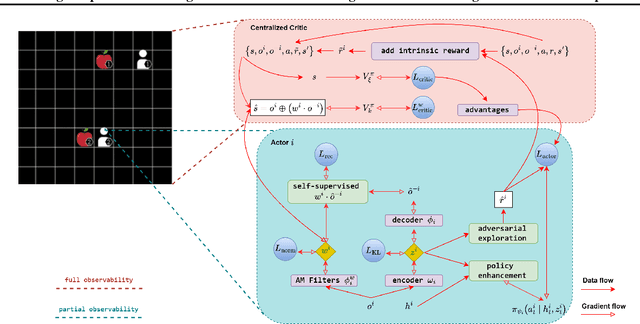


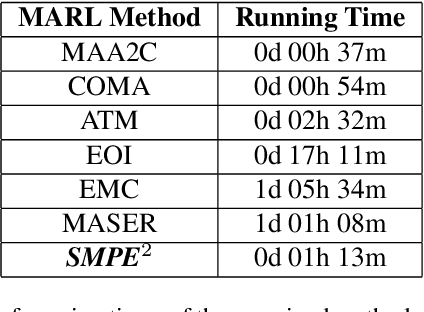
Learning to cooperate in distributed partially observable environments with no communication abilities poses significant challenges for multi-agent deep reinforcement learning (MARL). This paper addresses key concerns in this domain, focusing on inferring state representations from individual agent observations and leveraging these representations to enhance agents' exploration and collaborative task execution policies. To this end, we propose a novel state modelling framework for cooperative MARL, where agents infer meaningful belief representations of the non-observable state, with respect to optimizing their own policies, while filtering redundant and less informative joint state information. Building upon this framework, we propose the MARL SMPE algorithm. In SMPE, agents enhance their own policy's discriminative abilities under partial observability, explicitly by incorporating their beliefs into the policy network, and implicitly by adopting an adversarial type of exploration policies which encourages agents to discover novel, high-value states while improving the discriminative abilities of others. Experimentally, we show that SMPE outperforms state-of-the-art MARL algorithms in complex fully cooperative tasks from the MPE, LBF, and RWARE benchmarks.
Explaining Vision GNNs: A Semantic and Visual Analysis of Graph-based Image Classification
Apr 28, 2025Graph Neural Networks (GNNs) have emerged as an efficient alternative to convolutional approaches for vision tasks such as image classification, leveraging patch-based representations instead of raw pixels. These methods construct graphs where image patches serve as nodes, and edges are established based on patch similarity or classification relevance. Despite their efficiency, the explainability of GNN-based vision models remains underexplored, even though graphs are naturally interpretable. In this work, we analyze the semantic consistency of the graphs formed at different layers of GNN-based image classifiers, focusing on how well they preserve object structures and meaningful relationships. A comprehensive analysis is presented by quantifying the extent to which inter-layer graph connections reflect semantic similarity and spatial coherence. Explanations from standard and adversarial settings are also compared to assess whether they reflect the classifiers' robustness. Additionally, we visualize the flow of information across layers through heatmap-based visualization techniques, thereby highlighting the models' explainability. Our findings demonstrate that the decision-making processes of these models can be effectively explained, while also revealing that their reasoning does not necessarily align with human perception, especially in deeper layers.
Assumed Identities: Quantifying Gender Bias in Machine Translation of Ambiguous Occupational Terms
Mar 06, 2025Machine Translation (MT) systems frequently encounter ambiguous scenarios where they must assign gender to certain occupations when translating without explicit guidance or contextual cues. While individual translations in such cases may not be inherently biased, systematic patterns-such as the repeated association of certain professions with specific genders-can emerge, reflecting and perpetuating societal stereotypes. This ambiguity challenges traditional instance-level single-answer evaluation approaches, as no single gold standard translation exists. To address this, we propose an approach that evaluates gender bias through aggregated model responses. Specifically, we introduce a methodology to detect gender imbalances between source texts and translations, a benchmarking dataset with ambiguous English inputs, and probability-based metrics to quantify a model's divergence from normative standards or reference distributions.