 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGo witheFlow: Real-time Emotion Driven Audio Effects Modulation
Oct 02, 2025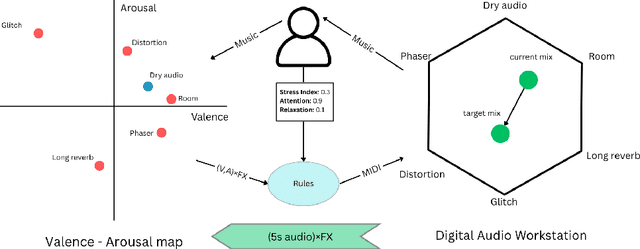

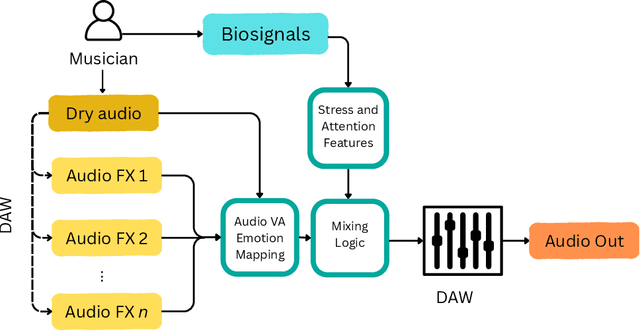
Music performance is a distinctly human activity, intrinsically linked to the performer's ability to convey, evoke, or express emotion. Machines cannot perform music in the human sense; they can produce, reproduce, execute, or synthesize music, but they lack the capacity for affective or emotional experience. As such, music performance is an ideal candidate through which to explore aspects of collaboration between humans and machines. In this paper, we introduce the witheFlow system, designed to enhance real-time music performance by automatically modulating audio effects based on features extracted from both biosignals and the audio itself. The system, currently in a proof-of-concept phase, is designed to be lightweight, able to run locally on a laptop, and is open-source given the availability of a compatible Digital Audio Workstation and sensors.
Exploring How Audio Effects Alter Emotion with Foundation Models
Sep 18, 2025Audio effects (FX) such as reverberation, distortion, modulation, and dynamic range processing play a pivotal role in shaping emotional responses during music listening. While prior studies have examined links between low-level audio features and affective perception, the systematic impact of audio FX on emotion remains underexplored. This work investigates how foundation models - large-scale neural architectures pretrained on multimodal data - can be leveraged to analyze these effects. Such models encode rich associations between musical structure, timbre, and affective meaning, offering a powerful framework for probing the emotional consequences of sound design techniques. By applying various probing methods to embeddings from deep learning models, we examine the complex, nonlinear relationships between audio FX and estimated emotion, uncovering patterns tied to specific effects and evaluating the robustness of foundation audio models. Our findings aim to advance understanding of the perceptual impact of audio production practices, with implications for music cognition, performance, and affective computing.
Semantic-Aware Interpretable Multimodal Music Auto-Tagging
May 26, 2025Music auto-tagging is essential for organizing and discovering music in extensive digital libraries. While foundation models achieve exceptional performance in this domain, their outputs often lack interpretability, limiting trust and usability for researchers and end-users alike. In this work, we present an interpretable framework for music auto-tagging that leverages groups of musically meaningful multimodal features, derived from signal processing, deep learning, ontology engineering, and natural language processing. To enhance interpretability, we cluster features semantically and employ an expectation maximization algorithm, assigning distinct weights to each group based on its contribution to the tagging process. Our method achieves competitive tagging performance while offering a deeper understanding of the decision-making process, paving the way for more transparent and user-centric music tagging systems.
CHORDONOMICON: A Dataset of 666,000 Songs and their Chord Progressions
Oct 29, 2024Chord progressions encapsulate important information about music, pertaining to its structure and conveyed emotions. They serve as the backbone of musical composition, and in many cases, they are the sole information required for a musician to play along and follow the music. Despite their importance, chord progressions as a data domain remain underexplored. There is a lack of large-scale datasets suitable for deep learning applications, and limited research exploring chord progressions as an input modality. In this work, we present Chordonomicon, a dataset of over 666,000 songs and their chord progressions, annotated with structural parts, genre, and release date - created by scraping various sources of user-generated progressions and associated metadata. We demonstrate the practical utility of the Chordonomicon dataset for classification and generation tasks, and discuss its potential to provide valuable insights to the research community. Chord progressions are unique in their ability to be represented in multiple formats (e.g. text, graph) and the wealth of information chords convey in given contexts, such as their harmonic function . These characteristics make the Chordonomicon an ideal testbed for exploring advanced machine learning techniques, including transformers, graph machine learning, and hybrid systems that combine knowledge representation and machine learning.
Semantic Prototypes: Enhancing Transparency Without Black Boxes
Jul 26, 2024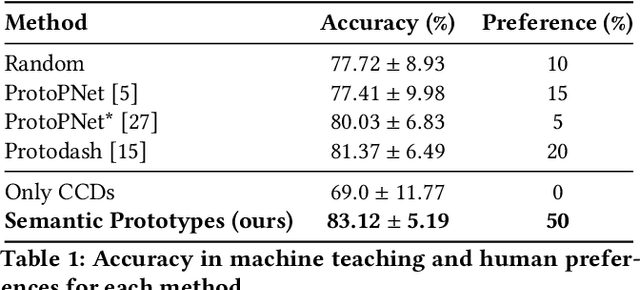



As machine learning (ML) models and datasets increase in complexity, the demand for methods that enhance explainability and interpretability becomes paramount. Prototypes, by encapsulating essential characteristics within data, offer insights that enable tactical decision-making and enhance transparency. Traditional prototype methods often rely on sub-symbolic raw data and opaque latent spaces, reducing explainability and increasing the risk of misinterpretations. This paper presents a novel framework that utilizes semantic descriptions to define prototypes and provide clear explanations, effectively addressing the shortcomings of conventional methods. Our approach leverages concept-based descriptions to cluster data on the semantic level, ensuring that prototypes not only represent underlying properties intuitively but are also straightforward to interpret. Our method simplifies the interpretative process and effectively bridges the gap between complex data structures and human cognitive processes, thereby enhancing transparency and fostering trust. Our approach outperforms existing widely-used prototype methods in facilitating human understanding and informativeness, as validated through a user survey.
Perceptual Musical Features for Interpretable Audio Tagging
Jan 04, 2024



In the age of music streaming platforms, the task of automatically tagging music audio has garnered significant attention, driving researchers to devise methods aimed at enhancing performance metrics on standard datasets. Most recent approaches rely on deep neural networks, which, despite their impressive performance, possess opacity, making it challenging to elucidate their output for a given input. While the issue of interpretability has been emphasized in other fields like medicine, it has not received attention in music-related tasks. In this study, we explored the relevance of interpretability in the context of automatic music tagging. We constructed a workflow that incorporates three different information extraction techniques: a) leveraging symbolic knowledge, b) utilizing auxiliary deep neural networks, and c) employing signal processing to extract perceptual features from audio files. These features were subsequently used to train an interpretable machine-learning model for tag prediction. We conducted experiments on two datasets, namely the MTG-Jamendo dataset and the GTZAN dataset. Our method surpassed the performance of baseline models in both tasks and, in certain instances, demonstrated competitiveness with the current state-of-the-art. We conclude that there are use cases where the deterioration in performance is outweighed by the value of interpretability.
The smarty4covid dataset and knowledge base: a framework enabling interpretable analysis of audio signals
Jul 11, 2023
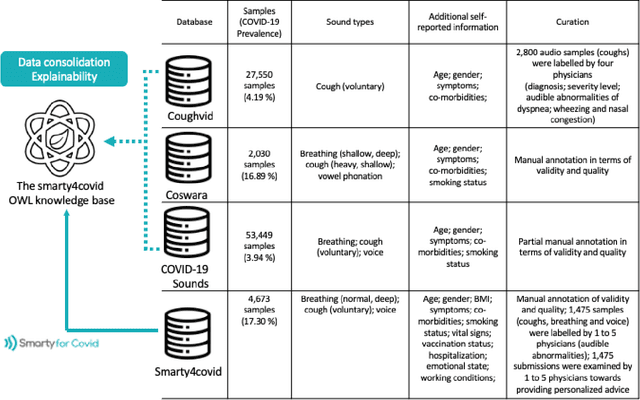

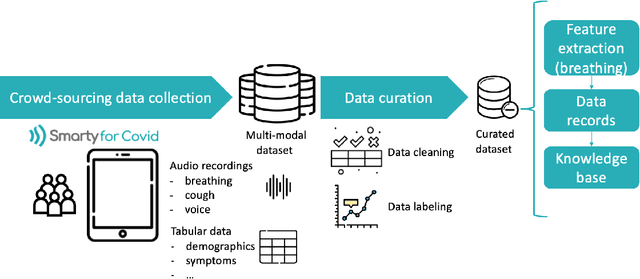
Harnessing the power of Artificial Intelligence (AI) and m-health towards detecting new bio-markers indicative of the onset and progress of respiratory abnormalities/conditions has greatly attracted the scientific and research interest especially during COVID-19 pandemic. The smarty4covid dataset contains audio signals of cough (4,676), regular breathing (4,665), deep breathing (4,695) and voice (4,291) as recorded by means of mobile devices following a crowd-sourcing approach. Other self reported information is also included (e.g. COVID-19 virus tests), thus providing a comprehensive dataset for the development of COVID-19 risk detection models. The smarty4covid dataset is released in the form of a web-ontology language (OWL) knowledge base enabling data consolidation from other relevant datasets, complex queries and reasoning. It has been utilized towards the development of models able to: (i) extract clinically informative respiratory indicators from regular breathing records, and (ii) identify cough, breath and voice segments in crowd-sourced audio recordings. A new framework utilizing the smarty4covid OWL knowledge base towards generating counterfactual explanations in opaque AI-based COVID-19 risk detection models is proposed and validated.
Choose your Data Wisely: A Framework for Semantic Counterfactuals
May 28, 2023


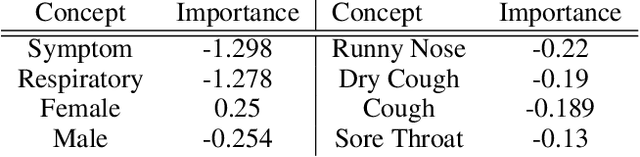
Counterfactual explanations have been argued to be one of the most intuitive forms of explanation. They are typically defined as a minimal set of edits on a given data sample that, when applied, changes the output of a model on that sample. However, a minimal set of edits is not always clear and understandable to an end-user, as it could, for instance, constitute an adversarial example (which is indistinguishable from the original data sample to an end-user). Instead, there are recent ideas that the notion of minimality in the context of counterfactuals should refer to the semantics of the data sample, and not to the feature space. In this work, we build on these ideas, and propose a framework that provides counterfactual explanations in terms of knowledge graphs. We provide an algorithm for computing such explanations (given some assumptions about the underlying knowledge), and quantitatively evaluate the framework with a user study.
Counterfactuals of Counterfactuals: a back-translation-inspired approach to analyse counterfactual editors
May 26, 2023



In the wake of responsible AI, interpretability methods, which attempt to provide an explanation for the predictions of neural models have seen rapid progress. In this work, we are concerned with explanations that are applicable to natural language processing (NLP) models and tasks, and we focus specifically on the analysis of counterfactual, contrastive explanations. We note that while there have been several explainers proposed to produce counterfactual explanations, their behaviour can vary significantly and the lack of a universal ground truth for the counterfactual edits imposes an insuperable barrier on their evaluation. We propose a new back translation-inspired evaluation methodology that utilises earlier outputs of the explainer as ground truth proxies to investigate the consistency of explainers. We show that by iteratively feeding the counterfactual to the explainer we can obtain valuable insights into the behaviour of both the predictor and the explainer models, and infer patterns that would be otherwise obscured. Using this methodology, we conduct a thorough analysis and propose a novel metric to evaluate the consistency of counterfactual generation approaches with different characteristics across available performance indicators.
Computing Rule-Based Explanations of Machine Learning Classifiers using Knowledge Graphs
Feb 08, 2022
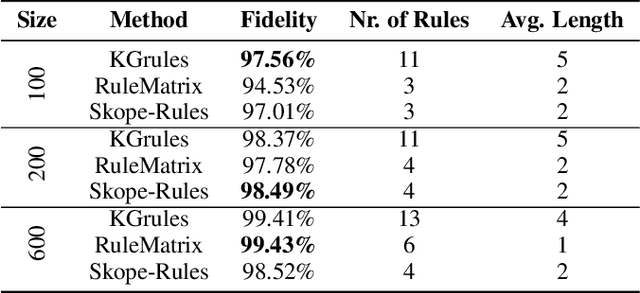
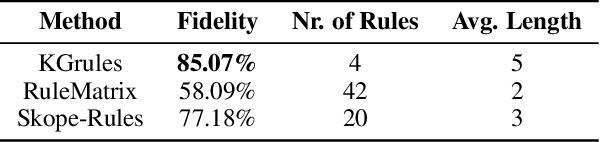

The use of symbolic knowledge representation and reasoning as a way to resolve the lack of transparency of machine learning classifiers is a research area that lately attracts many researchers. In this work, we use knowledge graphs as the underlying framework providing the terminology for representing explanations for the operation of a machine learning classifier. In particular, given a description of the application domain of the classifier in the form of a knowledge graph, we introduce a novel method for extracting and representing black-box explanations of its operation, in the form of first-order logic rules expressed in the terminology of the knowledge graph.