 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemEval-2026 Task 6: CLARITY -- Unmasking Political Question Evasions
Mar 14, 2026Political speakers often avoid answering questions directly while maintaining the appearance of responsiveness. Despite its importance for public discourse, such strategic evasion remains underexplored in Natural Language Processing. We introduce SemEval-2026 Task 6, CLARITY, a shared task on political question evasion consisting of two subtasks: (i) clarity-level classification into Clear Reply, Ambivalent, and Clear Non-Reply, and (ii) evasion-level classification into nine fine-grained evasion strategies. The benchmark is constructed from U.S. presidential interviews and follows an expert-grounded taxonomy of response clarity and evasion. The task attracted 124 registered teams, who submitted 946 valid runs for clarity-level classification and 539 for evasion-level classification. Results show a substantial gap in difficulty between the two subtasks: the best system achieved 0.89 macro-F1 on clarity classification, surpassing the strongest baseline by a large margin, while the top evasion-level system reached 0.68 macro-F1, matching the best baseline. Overall, large language model prompting and hierarchical exploitation of the taxonomy emerged as the most effective strategies, with top systems consistently outperforming those that treated the two subtasks independently. CLARITY establishes political response evasion as a challenging benchmark for computational discourse analysis and highlights the difficulty of modeling strategic ambiguity in political language.
Reasoning or Pattern Matching? Probing Large Vision-Language Models with Visual Puzzles
Jan 20, 2026Puzzles have long served as compact and revealing probes of human cognition, isolating abstraction, rule discovery, and systematic reasoning with minimal reliance on prior knowledge. Leveraging these properties, visual puzzles have recently emerged as a powerful diagnostic tool for evaluating the reasoning abilities of Large Vision-Language Models (LVLMs), offering controlled, verifiable alternatives to open-ended multimodal benchmarks. This survey provides a unified perspective of visual puzzle reasoning in LVLMs. We frame visual puzzles through a common abstraction and organize existing benchmarks by the reasoning mechanisms they target (inductive, analogical, algorithmic, deductive, and geometric/spatial), thereby linking puzzle design to the cognitive operations required for solving. Synthesizing empirical evidence across these categories, we identify consistent limitations in current models, including brittle generalization, tight entanglement between perception and reasoning, and a persistent gap between fluent explanations and faithful execution. By framing visual puzzles as diagnostic instruments rather than task formats, this survey elaborates on the state of LVLM reasoning and outlines key directions for future benchmarks and reasoning-aware multimodal systems.
Counterfactual Fairness with Graph Uncertainty
Jan 06, 2026Evaluating machine learning (ML) model bias is key to building trustworthy and robust ML systems. Counterfactual Fairness (CF) audits allow the measurement of bias of ML models with a causal framework, yet their conclusions rely on a single causal graph that is rarely known with certainty in real-world scenarios. We propose CF with Graph Uncertainty (CF-GU), a bias evaluation procedure that incorporates the uncertainty of specifying a causal graph into CF. CF-GU (i) bootstraps a Causal Discovery algorithm under domain knowledge constraints to produce a bag of plausible Directed Acyclic Graphs (DAGs), (ii) quantifies graph uncertainty with the normalized Shannon entropy, and (iii) provides confidence bounds on CF metrics. Experiments on synthetic data show how contrasting domain knowledge assumptions support or refute audits of CF, while experiments on real-world data (COMPAS and Adult datasets) pinpoint well-known biases with high confidence, even when supplied with minimal domain knowledge constraints.
Teaching Language Models to Faithfully Express their Uncertainty
Oct 14, 2025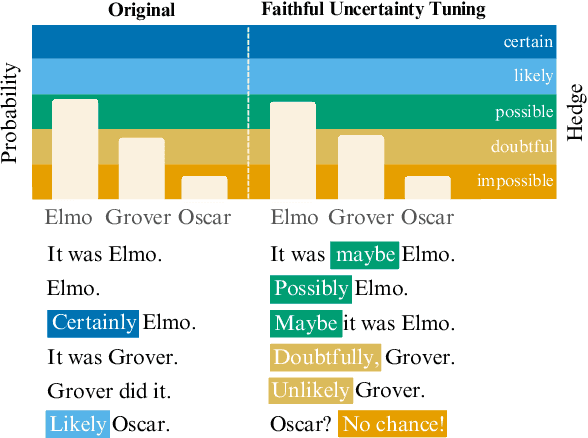
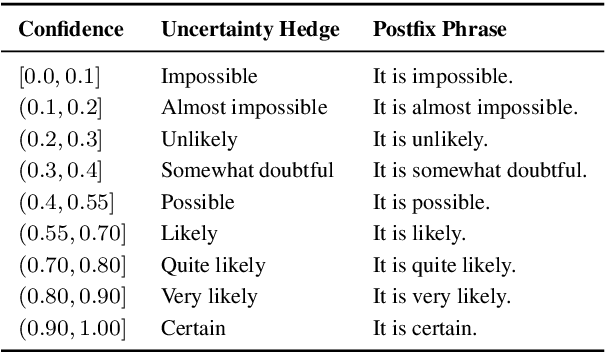
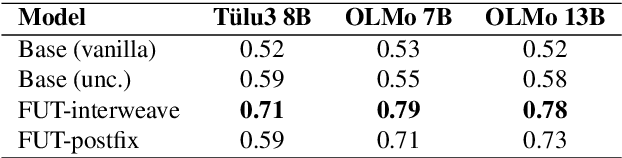
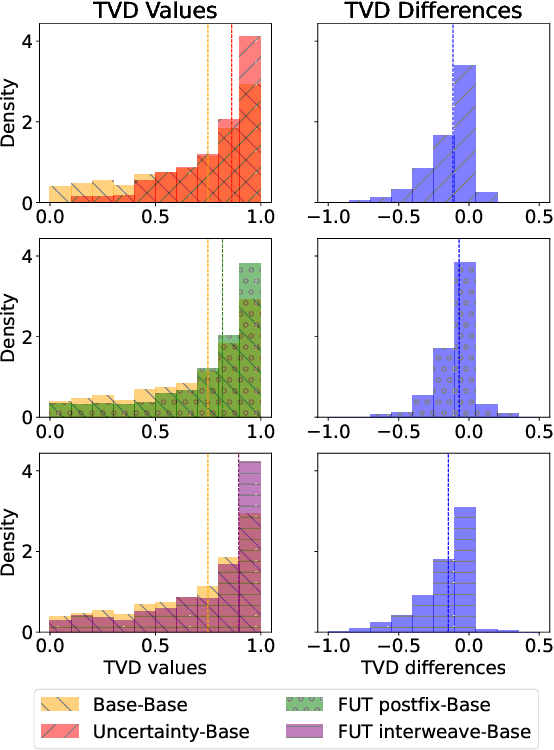
Large language models (LLMs) often miscommunicate their uncertainty: repeated queries can produce divergent answers, yet generated responses are typically unhedged or hedged in ways that do not reflect this variability. This conveys unfaithful information about the uncertain state of the LLMs' knowledge, creating a faithfulness gap that affects even strong LLMs. We introduce Faithful Uncertainty Tuning (FUT): a fine-tuning approach that teaches instruction-tuned LLMs to express uncertainty faithfully without altering their underlying answer distribution. We construct training data by augmenting model samples with uncertainty hedges (i.e. verbal cues such as 'possibly' or 'likely') aligned with sample consistency, requiring no supervision beyond the model and a set of prompts. We evaluate FUT on open-domain question answering (QA) across multiple models and datasets. Our results show that FUT substantially reduces the faithfulness gap, while preserving QA accuracy and introducing minimal semantic distribution shift. Further analyses demonstrate robustness across decoding strategies, choice of hedgers, and other forms of uncertainty expression (i.e. numerical). These findings establish FUT as a simple and effective way to teach LLMs to communicate uncertainty faithfully.
GAMBIT+: A Challenge Set for Evaluating Gender Bias in Machine Translation Quality Estimation Metrics
Oct 08, 2025Gender bias in machine translation (MT) systems has been extensively documented, but bias in automatic quality estimation (QE) metrics remains comparatively underexplored. Existing studies suggest that QE metrics can also exhibit gender bias, yet most analyses are limited by small datasets, narrow occupational coverage, and restricted language variety. To address this gap, we introduce a large-scale challenge set specifically designed to probe the behavior of QE metrics when evaluating translations containing gender-ambiguous occupational terms. Building on the GAMBIT corpus of English texts with gender-ambiguous occupations, we extend coverage to three source languages that are genderless or natural-gendered, and eleven target languages with grammatical gender, resulting in 33 source-target language pairs. Each source text is paired with two target versions differing only in the grammatical gender of the occupational term(s) (masculine vs. feminine), with all dependent grammatical elements adjusted accordingly. An unbiased QE metric should assign equal or near-equal scores to both versions. The dataset's scale, breadth, and fully parallel design, where the same set of texts is aligned across all languages, enables fine-grained bias analysis by occupation and systematic comparisons across languages.
Unlocking Latent Discourse Translation in LLMs Through Quality-Aware Decoding
Oct 08, 2025Large language models (LLMs) have emerged as strong contenders in machine translation.Yet, they still struggle to adequately handle discourse phenomena, such as pronoun resolution and lexical cohesion at the document level. In this study, we thoroughly investigate the discourse phenomena performance of LLMs in context-aware translation. We demonstrate that discourse knowledge is encoded within LLMs and propose the use of quality-aware decoding (QAD) to effectively extract this knowledge, showcasing its superiority over other decoding approaches through comprehensive analysis. Furthermore, we illustrate that QAD enhances the semantic richness of translations and aligns them more closely with human preferences.
Movie Facts and Fibs (MF$^2$): A Benchmark for Long Movie Understanding
Jun 06, 2025Despite recent progress in vision-language models (VLMs), holistic understanding of long-form video content remains a significant challenge, partly due to limitations in current benchmarks. Many focus on peripheral, ``needle-in-a-haystack'' details, encouraging context-insensitive retrieval over deep comprehension. Others rely on large-scale, semi-automatically generated questions (often produced by language models themselves) that are easier for models to answer but fail to reflect genuine understanding. In this paper, we introduce MF$^2$, a new benchmark for evaluating whether models can comprehend, consolidate, and recall key narrative information from full-length movies (50-170 minutes long). MF$^2$ includes over 50 full-length, open-licensed movies, each paired with manually constructed sets of claim pairs -- one true (fact) and one plausible but false (fib), totalling over 850 pairs. These claims target core narrative elements such as character motivations and emotions, causal chains, and event order, and refer to memorable moments that humans can recall without rewatching the movie. Instead of multiple-choice formats, we adopt a binary claim evaluation protocol: for each pair, models must correctly identify both the true and false claims. This reduces biases like answer ordering and enables a more precise assessment of reasoning. Our experiments demonstrate that both open-weight and closed state-of-the-art models fall well short of human performance, underscoring the relative ease of the task for humans and their superior ability to retain and reason over critical narrative information -- an ability current VLMs lack.
A Conformal Risk Control Framework for Granular Word Assessment and Uncertainty Calibration of CLIPScore Quality Estimates
Apr 01, 2025This study explores current limitations of learned image captioning evaluation metrics, specifically the lack of granular assessment for individual word misalignments within captions, and the reliance on single-point quality estimates without considering uncertainty. To address these limitations, we propose a simple yet effective strategy for generating and calibrating CLIPScore distributions. Leveraging a model-agnostic conformal risk control framework, we calibrate CLIPScore values for task-specific control variables, to tackle the aforementioned two limitations. Experimental results demonstrate that using conformal risk control, over the distributions produced with simple methods such as input masking, can achieve competitive performance compared to more complex approaches. Our method effectively detects misaligned words, while providing formal guarantees aligned with desired risk levels, and improving the correlation between uncertainty estimations and prediction errors, thus enhancing the overall reliability of caption evaluation metrics.
Rejected Dialects: Biases Against African American Language in Reward Models
Feb 18, 2025Preference alignment via reward models helps build safe, helpful, and reliable large language models (LLMs). However, subjectivity in preference judgments and the lack of representative sampling in preference data collection can introduce new biases, hindering reward models' fairness and equity. In this work, we introduce a framework for evaluating dialect biases in reward models and conduct a case study on biases against African American Language (AAL) through several experiments comparing reward model preferences and behavior on paired White Mainstream English (WME) and both machine-translated and human-written AAL corpora. We show that reward models are less aligned with human preferences when processing AAL texts vs. WME ones (-4\% accuracy on average), frequently disprefer AAL-aligned texts vs. WME-aligned ones, and steer conversations toward WME, even when prompted with AAL texts. Our findings provide a targeted analysis of anti-AAL biases at a relatively understudied stage in LLM development, highlighting representational harms and ethical questions about the desired behavior of LLMs concerning AAL.
Evaluation of Multilingual Image Captioning: How far can we get with CLIP models?
Feb 10, 2025



The evaluation of image captions, looking at both linguistic fluency and semantic correspondence to visual contents, has witnessed a significant effort. Still, despite advancements such as the CLIPScore metric, multilingual captioning evaluation has remained relatively unexplored. This work presents several strategies, and extensive experiments, related to evaluating CLIPScore variants in multilingual settings. To address the lack of multilingual test data, we consider two different strategies: (1) using quality aware machine-translated datasets with human judgements, and (2) re-purposing multilingual datasets that target semantic inference and reasoning. Our results highlight the potential of finetuned multilingual models to generalize across languages and to handle complex linguistic challenges. Tests with machine-translated data show that multilingual CLIPScore models can maintain a high correlation with human judgements across different languages, and additional tests with natively multilingual and multicultural data further attest to the high-quality assessments.