 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBias Beware: The Impact of Cognitive Biases on LLM-Driven Product Recommendations
Feb 03, 2025The advent of Large Language Models (LLMs) has revolutionized product recommendation systems, yet their susceptibility to adversarial manipulation poses critical challenges, particularly in real-world commercial applications. Our approach is the first one to tap into human psychological principles, seamlessly modifying product descriptions, making these adversarial manipulations hard to detect. In this work, we investigate cognitive biases as black-box adversarial strategies, drawing parallels between their effects on LLMs and human purchasing behavior. Through extensive experiments on LLMs of varying scales, we reveal significant vulnerabilities in their use as recommenders, providing critical insights into safeguarding these systems.
CHORDONOMICON: A Dataset of 666,000 Songs and their Chord Progressions
Oct 29, 2024Chord progressions encapsulate important information about music, pertaining to its structure and conveyed emotions. They serve as the backbone of musical composition, and in many cases, they are the sole information required for a musician to play along and follow the music. Despite their importance, chord progressions as a data domain remain underexplored. There is a lack of large-scale datasets suitable for deep learning applications, and limited research exploring chord progressions as an input modality. In this work, we present Chordonomicon, a dataset of over 666,000 songs and their chord progressions, annotated with structural parts, genre, and release date - created by scraping various sources of user-generated progressions and associated metadata. We demonstrate the practical utility of the Chordonomicon dataset for classification and generation tasks, and discuss its potential to provide valuable insights to the research community. Chord progressions are unique in their ability to be represented in multiple formats (e.g. text, graph) and the wealth of information chords convey in given contexts, such as their harmonic function . These characteristics make the Chordonomicon an ideal testbed for exploring advanced machine learning techniques, including transformers, graph machine learning, and hybrid systems that combine knowledge representation and machine learning.
"I Never Said That": A dataset, taxonomy and baselines on response clarity classification
Sep 20, 2024



Equivocation and ambiguity in public speech are well-studied discourse phenomena, especially in political science and analysis of political interviews. Inspired by the well-grounded theory on equivocation, we aim to resolve the closely related problem of response clarity in questions extracted from political interviews, leveraging the capabilities of Large Language Models (LLMs) and human expertise. To this end, we introduce a novel taxonomy that frames the task of detecting and classifying response clarity and a corresponding clarity classification dataset which consists of question-answer (QA) pairs drawn from political interviews and annotated accordingly. Our proposed two-level taxonomy addresses the clarity of a response in terms of the information provided for a given question (high-level) and also provides a fine-grained taxonomy of evasion techniques that relate to unclear, ambiguous responses (lower-level). We combine ChatGPT and human annotators to collect, validate and annotate discrete QA pairs from political interviews, to be used for our newly introduced response clarity task. We provide a detailed analysis and conduct several experiments with different model architectures, sizes and adaptation methods to gain insights and establish new baselines over the proposed dataset and task.
Structure Your Data: Towards Semantic Graph Counterfactuals
Mar 11, 2024



Counterfactual explanations (CEs) based on concepts are explanations that consider alternative scenarios to understand which high-level semantic features contributed to particular model predictions. In this work, we propose CEs based on the semantic graphs accompanying input data to achieve more descriptive, accurate, and human-aligned explanations. Building upon state-of-the-art (SoTA) conceptual attempts, we adopt a model-agnostic edit-based approach and introduce leveraging GNNs for efficient Graph Edit Distance (GED) computation. With a focus on the visual domain, we represent images as scene graphs and obtain their GNN embeddings to bypass solving the NP-hard graph similarity problem for all input pairs, an integral part of the CE computation process. We apply our method to benchmark and real-world datasets with varying difficulty and availability of semantic annotations. Testing on diverse classifiers, we find that our CEs outperform previous SoTA explanation models based on semantics, including both white and black-box as well as conceptual and pixel-level approaches. Their superiority is proven quantitatively and qualitatively, as validated by human subjects, highlighting the significance of leveraging semantic edges in the presence of intricate relationships. Our model-agnostic graph-based approach is widely applicable and easily extensible, producing actionable explanations across different contexts.
Choose your Data Wisely: A Framework for Semantic Counterfactuals
May 28, 2023


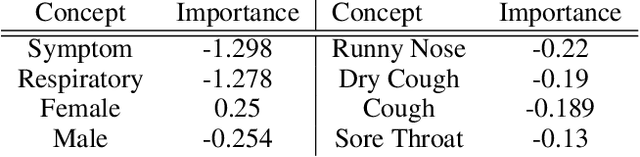
Counterfactual explanations have been argued to be one of the most intuitive forms of explanation. They are typically defined as a minimal set of edits on a given data sample that, when applied, changes the output of a model on that sample. However, a minimal set of edits is not always clear and understandable to an end-user, as it could, for instance, constitute an adversarial example (which is indistinguishable from the original data sample to an end-user). Instead, there are recent ideas that the notion of minimality in the context of counterfactuals should refer to the semantics of the data sample, and not to the feature space. In this work, we build on these ideas, and propose a framework that provides counterfactual explanations in terms of knowledge graphs. We provide an algorithm for computing such explanations (given some assumptions about the underlying knowledge), and quantitatively evaluate the framework with a user study.
Fine-Grained ImageNet Classification in the Wild
Mar 04, 2023



Image classification has been one of the most popular tasks in Deep Learning, seeing an abundance of impressive implementations each year. However, there is a lot of criticism tied to promoting complex architectures that continuously push performance metrics higher and higher. Robustness tests can uncover several vulnerabilities and biases which go unnoticed during the typical model evaluation stage. So far, model robustness under distribution shifts has mainly been examined within carefully curated datasets. Nevertheless, such approaches do not test the real response of classifiers in the wild, e.g. when uncurated web-crawled image data of corresponding classes are provided. In our work, we perform fine-grained classification on closely related categories, which are identified with the help of hierarchical knowledge. Extensive experimentation on a variety of convolutional and transformer-based architectures reveals model robustness in this novel setting. Finally, hierarchical knowledge is again employed to evaluate and explain misclassifications, providing an information-rich evaluation scheme adaptable to any classifier.
Counterfactual Edits for Generative Evaluation
Mar 02, 2023



Evaluation of generative models has been an underrepresented field despite the surge of generative architectures. Most recent models are evaluated upon rather obsolete metrics which suffer from robustness issues, while being unable to assess more aspects of visual quality, such as compositionality and logic of synthesis. At the same time, the explainability of generative models remains a limited, though important, research direction with several current attempts requiring access to the inner functionalities of generative models. Contrary to prior literature, we view generative models as a black box, and we propose a framework for the evaluation and explanation of synthesized results based on concepts instead of pixels. Our framework exploits knowledge-based counterfactual edits that underline which objects or attributes should be inserted, removed, or replaced from generated images to approach their ground truth conditioning. Moreover, global explanations produced by accumulating local edits can also reveal what concepts a model cannot generate in total. The application of our framework on various models designed for the challenging tasks of Story Visualization and Scene Synthesis verifies the power of our approach in the model-agnostic setting.