 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReasoning or Pattern Matching? Probing Large Vision-Language Models with Visual Puzzles
Jan 20, 2026Puzzles have long served as compact and revealing probes of human cognition, isolating abstraction, rule discovery, and systematic reasoning with minimal reliance on prior knowledge. Leveraging these properties, visual puzzles have recently emerged as a powerful diagnostic tool for evaluating the reasoning abilities of Large Vision-Language Models (LVLMs), offering controlled, verifiable alternatives to open-ended multimodal benchmarks. This survey provides a unified perspective of visual puzzle reasoning in LVLMs. We frame visual puzzles through a common abstraction and organize existing benchmarks by the reasoning mechanisms they target (inductive, analogical, algorithmic, deductive, and geometric/spatial), thereby linking puzzle design to the cognitive operations required for solving. Synthesizing empirical evidence across these categories, we identify consistent limitations in current models, including brittle generalization, tight entanglement between perception and reasoning, and a persistent gap between fluent explanations and faithful execution. By framing visual puzzles as diagnostic instruments rather than task formats, this survey elaborates on the state of LVLM reasoning and outlines key directions for future benchmarks and reasoning-aware multimodal systems.
GAMBIT+: A Challenge Set for Evaluating Gender Bias in Machine Translation Quality Estimation Metrics
Oct 08, 2025Gender bias in machine translation (MT) systems has been extensively documented, but bias in automatic quality estimation (QE) metrics remains comparatively underexplored. Existing studies suggest that QE metrics can also exhibit gender bias, yet most analyses are limited by small datasets, narrow occupational coverage, and restricted language variety. To address this gap, we introduce a large-scale challenge set specifically designed to probe the behavior of QE metrics when evaluating translations containing gender-ambiguous occupational terms. Building on the GAMBIT corpus of English texts with gender-ambiguous occupations, we extend coverage to three source languages that are genderless or natural-gendered, and eleven target languages with grammatical gender, resulting in 33 source-target language pairs. Each source text is paired with two target versions differing only in the grammatical gender of the occupational term(s) (masculine vs. feminine), with all dependent grammatical elements adjusted accordingly. An unbiased QE metric should assign equal or near-equal scores to both versions. The dataset's scale, breadth, and fully parallel design, where the same set of texts is aligned across all languages, enables fine-grained bias analysis by occupation and systematic comparisons across languages.
Analyze-Prompt-Reason: A Collaborative Agent-Based Framework for Multi-Image Vision-Language Reasoning
Aug 01, 2025We present a Collaborative Agent-Based Framework for Multi-Image Reasoning. Our approach tackles the challenge of interleaved multimodal reasoning across diverse datasets and task formats by employing a dual-agent system: a language-based PromptEngineer, which generates context-aware, task-specific prompts, and a VisionReasoner, a large vision-language model (LVLM) responsible for final inference. The framework is fully automated, modular, and training-free, enabling generalization across classification, question answering, and free-form generation tasks involving one or multiple input images. We evaluate our method on 18 diverse datasets from the 2025 MIRAGE Challenge (Track A), covering a broad spectrum of visual reasoning tasks including document QA, visual comparison, dialogue-based understanding, and scene-level inference. Our results demonstrate that LVLMs can effectively reason over multiple images when guided by informative prompts. Notably, Claude 3.7 achieves near-ceiling performance on challenging tasks such as TQA (99.13% accuracy), DocVQA (96.87%), and MMCoQA (75.28 ROUGE-L). We also explore how design choices-such as model selection, shot count, and input length-influence the reasoning performance of different LVLMs.
Assumed Identities: Quantifying Gender Bias in Machine Translation of Ambiguous Occupational Terms
Mar 06, 2025Machine Translation (MT) systems frequently encounter ambiguous scenarios where they must assign gender to certain occupations when translating without explicit guidance or contextual cues. While individual translations in such cases may not be inherently biased, systematic patterns-such as the repeated association of certain professions with specific genders-can emerge, reflecting and perpetuating societal stereotypes. This ambiguity challenges traditional instance-level single-answer evaluation approaches, as no single gold standard translation exists. To address this, we propose an approach that evaluates gender bias through aggregated model responses. Specifically, we introduce a methodology to detect gender imbalances between source texts and translations, a benchmarking dataset with ambiguous English inputs, and probability-based metrics to quantify a model's divergence from normative standards or reference distributions.
AILS-NTUA at SemEval-2025 Task 3: Leveraging Large Language Models and Translation Strategies for Multilingual Hallucination Detection
Mar 04, 2025



Multilingual hallucination detection stands as an underexplored challenge, which the Mu-SHROOM shared task seeks to address. In this work, we propose an efficient, training-free LLM prompting strategy that enhances detection by translating multilingual text spans into English. Our approach achieves competitive rankings across multiple languages, securing two first positions in low-resource languages. The consistency of our results highlights the effectiveness of our translation strategy for hallucination detection, demonstrating its applicability regardless of the source language.
AILS-NTUA at SemEval-2025 Task 4: Parameter-Efficient Unlearning for Large Language Models using Data Chunking
Mar 04, 2025



The Unlearning Sensitive Content from Large Language Models task aims to remove targeted datapoints from trained models while minimally affecting their general knowledge. In our work, we leverage parameter-efficient, gradient-based unlearning using low-rank (LoRA) adaptation and layer-focused fine-tuning. To further enhance unlearning effectiveness, we employ data chunking, splitting forget data into disjoint partitions and merging them with cyclically sampled retain samples at a pre-defined ratio. Our task-agnostic method achieves an outstanding forget-retain balance, ranking first on leaderboards and significantly outperforming baselines and competing systems.
Pitfalls of Scale: Investigating the Inverse Task of Redefinition in Large Language Models
Feb 18, 2025



Inverse tasks can uncover potential reasoning gaps as Large Language Models (LLMs) scale up. In this work, we explore the redefinition task, in which we assign alternative values to well-known physical constants and units of measure, prompting LLMs to respond accordingly. Our findings show that not only does model performance degrade with scale, but its false confidence also rises. Moreover, while factors such as prompting strategies or response formatting are influential, they do not preclude LLMs from anchoring to memorized values.
Bias Beware: The Impact of Cognitive Biases on LLM-Driven Product Recommendations
Feb 03, 2025The advent of Large Language Models (LLMs) has revolutionized product recommendation systems, yet their susceptibility to adversarial manipulation poses critical challenges, particularly in real-world commercial applications. Our approach is the first one to tap into human psychological principles, seamlessly modifying product descriptions, making these adversarial manipulations hard to detect. In this work, we investigate cognitive biases as black-box adversarial strategies, drawing parallels between their effects on LLMs and human purchasing behavior. Through extensive experiments on LLMs of varying scales, we reveal significant vulnerabilities in their use as recommenders, providing critical insights into safeguarding these systems.
BERTtime Stories: Investigating the Role of Synthetic Story Data in Language pre-training
Oct 20, 2024

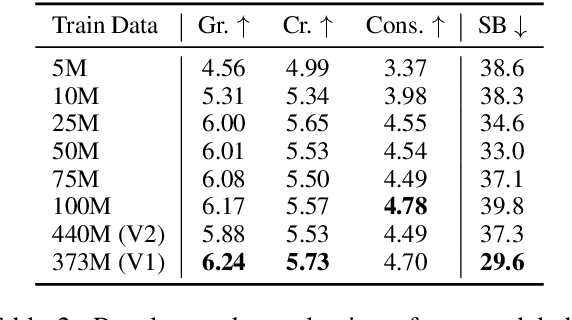

We describe our contribution to the Strict and Strict-Small tracks of the 2nd iteration of the BabyLM Challenge. The shared task is centered around efficient pre-training given data constraints motivated by human development. In response, we study the effect of synthetic story data in language pre-training using TinyStories: a recently introduced dataset of short stories. Initially, we train GPT-Neo models on subsets of TinyStories, while varying the amount of available data. We find that, even with access to less than 100M words, the models are able to generate high-quality, original completions to a given story, and acquire substantial linguistic knowledge. To measure the effect of synthetic story data, we train LTG-BERT encoder models on a combined dataset of: a subset of TinyStories, story completions generated by GPT-Neo, and a subset of the BabyLM dataset. Our experimentation reveals that synthetic data can occasionally offer modest gains, but overall have a negative influence on linguistic understanding. Our work offers an initial study on synthesizing story data in low resource settings and underscores their potential for augmentation in data-constrained language modeling. We publicly release our models and implementation on our GitHub.
RISCORE: Enhancing In-Context Riddle Solving in Language Models through Context-Reconstructed Example Augmentation
Sep 24, 2024



Riddle-solving requires advanced reasoning skills, pushing LLMs to engage in abstract thinking and creative problem-solving, often revealing limitations in their cognitive abilities. In this paper, we examine the riddle-solving capabilities of LLMs using a multiple-choice format, exploring how different prompting techniques impact performance on riddles that demand diverse reasoning skills. To enhance results, we introduce RISCORE (RIddle Solving with COntext REcontruciton) a novel fully automated prompting method that generates and utilizes contextually reconstructed sentence-based puzzles in conjunction with the original examples to create few-shot exemplars. Our experiments demonstrate that RISCORE significantly improves the performance of language models in both vertical and lateral thinking tasks, surpassing traditional exemplar selection strategies across a variety of few-shot settings.