 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTerminal-Bench: Benchmarking Agents on Hard, Realistic Tasks in Command Line Interfaces
Jan 17, 2026AI agents may soon become capable of autonomously completing valuable, long-horizon tasks in diverse domains. Current benchmarks either do not measure real-world tasks, or are not sufficiently difficult to meaningfully measure frontier models. To this end, we present Terminal-Bench 2.0: a carefully curated hard benchmark composed of 89 tasks in computer terminal environments inspired by problems from real workflows. Each task features a unique environment, human-written solution, and comprehensive tests for verification. We show that frontier models and agents score less than 65\% on the benchmark and conduct an error analysis to identify areas for model and agent improvement. We publish the dataset and evaluation harness to assist developers and researchers in future work at https://www.tbench.ai/ .
GAMBIT+: A Challenge Set for Evaluating Gender Bias in Machine Translation Quality Estimation Metrics
Oct 08, 2025Gender bias in machine translation (MT) systems has been extensively documented, but bias in automatic quality estimation (QE) metrics remains comparatively underexplored. Existing studies suggest that QE metrics can also exhibit gender bias, yet most analyses are limited by small datasets, narrow occupational coverage, and restricted language variety. To address this gap, we introduce a large-scale challenge set specifically designed to probe the behavior of QE metrics when evaluating translations containing gender-ambiguous occupational terms. Building on the GAMBIT corpus of English texts with gender-ambiguous occupations, we extend coverage to three source languages that are genderless or natural-gendered, and eleven target languages with grammatical gender, resulting in 33 source-target language pairs. Each source text is paired with two target versions differing only in the grammatical gender of the occupational term(s) (masculine vs. feminine), with all dependent grammatical elements adjusted accordingly. An unbiased QE metric should assign equal or near-equal scores to both versions. The dataset's scale, breadth, and fully parallel design, where the same set of texts is aligned across all languages, enables fine-grained bias analysis by occupation and systematic comparisons across languages.
Don't Erase, Inform! Detecting and Contextualizing Harmful Language in Cultural Heritage Collections
May 30, 2025Cultural Heritage (CH) data hold invaluable knowledge, reflecting the history, traditions, and identities of societies, and shaping our understanding of the past and present. However, many CH collections contain outdated or offensive descriptions that reflect historical biases. CH Institutions (CHIs) face significant challenges in curating these data due to the vast scale and complexity of the task. To address this, we develop an AI-powered tool that detects offensive terms in CH metadata and provides contextual insights into their historical background and contemporary perception. We leverage a multilingual vocabulary co-created with marginalized communities, researchers, and CH professionals, along with traditional NLP techniques and Large Language Models (LLMs). Available as a standalone web app and integrated with major CH platforms, the tool has processed over 7.9 million records, contextualizing the contentious terms detected in their metadata. Rather than erasing these terms, our approach seeks to inform, making biases visible and providing actionable insights for creating more inclusive and accessible CH collections.
Assumed Identities: Quantifying Gender Bias in Machine Translation of Ambiguous Occupational Terms
Mar 06, 2025Machine Translation (MT) systems frequently encounter ambiguous scenarios where they must assign gender to certain occupations when translating without explicit guidance or contextual cues. While individual translations in such cases may not be inherently biased, systematic patterns-such as the repeated association of certain professions with specific genders-can emerge, reflecting and perpetuating societal stereotypes. This ambiguity challenges traditional instance-level single-answer evaluation approaches, as no single gold standard translation exists. To address this, we propose an approach that evaluates gender bias through aggregated model responses. Specifically, we introduce a methodology to detect gender imbalances between source texts and translations, a benchmarking dataset with ambiguous English inputs, and probability-based metrics to quantify a model's divergence from normative standards or reference distributions.
AILS-NTUA at SemEval-2025 Task 4: Parameter-Efficient Unlearning for Large Language Models using Data Chunking
Mar 04, 2025



The Unlearning Sensitive Content from Large Language Models task aims to remove targeted datapoints from trained models while minimally affecting their general knowledge. In our work, we leverage parameter-efficient, gradient-based unlearning using low-rank (LoRA) adaptation and layer-focused fine-tuning. To further enhance unlearning effectiveness, we employ data chunking, splitting forget data into disjoint partitions and merging them with cyclically sampled retain samples at a pre-defined ratio. Our task-agnostic method achieves an outstanding forget-retain balance, ranking first on leaderboards and significantly outperforming baselines and competing systems.
GOSt-MT: A Knowledge Graph for Occupation-related Gender Biases in Machine Translation
Sep 17, 2024



Gender bias in machine translation (MT) systems poses significant challenges that often result in the reinforcement of harmful stereotypes. Especially in the labour domain where frequently occupations are inaccurately associated with specific genders, such biases perpetuate traditional gender stereotypes with a significant impact on society. Addressing these issues is crucial for ensuring equitable and accurate MT systems. This paper introduces a novel approach to studying occupation-related gender bias through the creation of the GOSt-MT (Gender and Occupation Statistics for Machine Translation) Knowledge Graph. GOSt-MT integrates comprehensive gender statistics from real-world labour data and textual corpora used in MT training. This Knowledge Graph allows for a detailed analysis of gender bias across English, French, and Greek, facilitating the identification of persistent stereotypes and areas requiring intervention. By providing a structured framework for understanding how occupations are gendered in both labour markets and MT systems, GOSt-MT contributes to efforts aimed at making MT systems more equitable and reducing gender biases in automated translations.
MusicLIME: Explainable Multimodal Music Understanding
Sep 16, 2024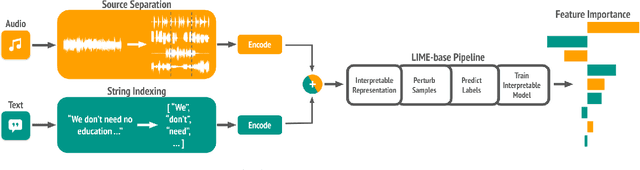

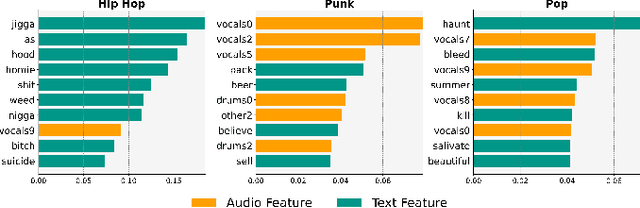
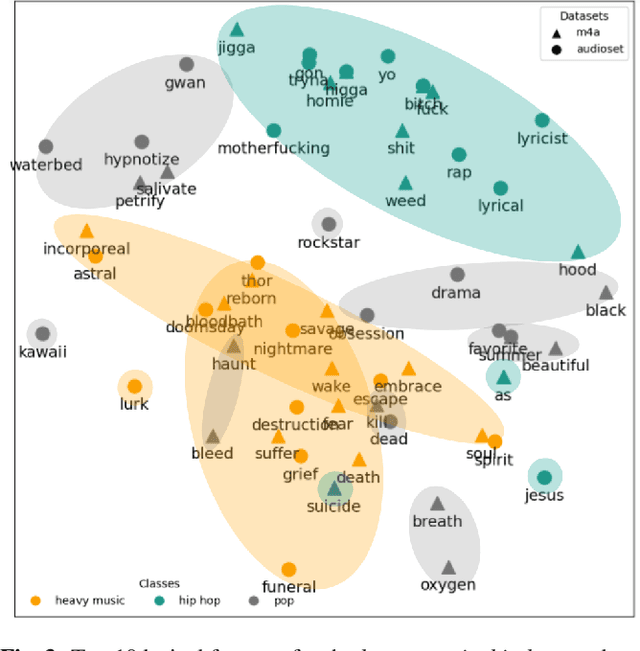
Multimodal models are critical for music understanding tasks, as they capture the complex interplay between audio and lyrics. However, as these models become more prevalent, the need for explainability grows-understanding how these systems make decisions is vital for ensuring fairness, reducing bias, and fostering trust. In this paper, we introduce MusicLIME, a model-agnostic feature importance explanation method designed for multimodal music models. Unlike traditional unimodal methods, which analyze each modality separately without considering the interaction between them, often leading to incomplete or misleading explanations, MusicLIME reveals how audio and lyrical features interact and contribute to predictions, providing a holistic view of the model's decision-making. Additionally, we enhance local explanations by aggregating them into global explanations, giving users a broader perspective of model behavior. Through this work, we contribute to improving the interpretability of multimodal music models, empowering users to make informed choices, and fostering more equitable, fair, and transparent music understanding systems.
Beyond One-Size-Fits-All: Adapting Counterfactual Explanations to User Objectives
Apr 12, 2024Explainable Artificial Intelligence (XAI) has emerged as a critical area of research aimed at enhancing the transparency and interpretability of AI systems. Counterfactual Explanations (CFEs) offer valuable insights into the decision-making processes of machine learning algorithms by exploring alternative scenarios where certain factors differ. Despite the growing popularity of CFEs in the XAI community, existing literature often overlooks the diverse needs and objectives of users across different applications and domains, leading to a lack of tailored explanations that adequately address the different use cases. In this paper, we advocate for a nuanced understanding of CFEs, recognizing the variability in desired properties based on user objectives and target applications. We identify three primary user objectives and explore the desired characteristics of CFEs in each case. By addressing these differences, we aim to design more effective and tailored explanations that meet the specific needs of users, thereby enhancing collaboration with AI systems.
Towards explainable evaluation of language models on the semantic similarity of visual concepts
Sep 08, 2022



Recent breakthroughs in NLP research, such as the advent of Transformer models have indisputably contributed to major advancements in several tasks. However, few works research robustness and explainability issues of their evaluation strategies. In this work, we examine the behavior of high-performing pre-trained language models, focusing on the task of semantic similarity for visual vocabularies. First, we address the need for explainable evaluation metrics, necessary for understanding the conceptual quality of retrieved instances. Our proposed metrics provide valuable insights in local and global level, showcasing the inabilities of widely used approaches. Secondly, adversarial interventions on salient query semantics expose vulnerabilities of opaque metrics and highlight patterns in learned linguistic representations.