 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGo witheFlow: Real-time Emotion Driven Audio Effects Modulation
Oct 02, 2025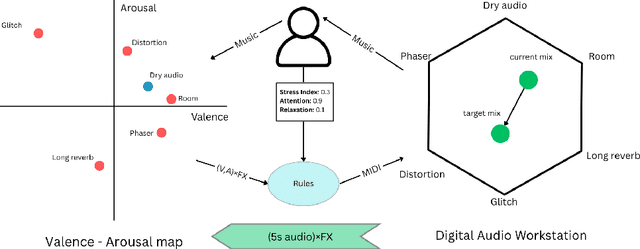

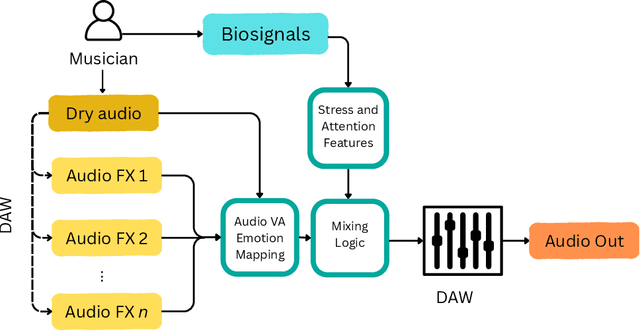
Music performance is a distinctly human activity, intrinsically linked to the performer's ability to convey, evoke, or express emotion. Machines cannot perform music in the human sense; they can produce, reproduce, execute, or synthesize music, but they lack the capacity for affective or emotional experience. As such, music performance is an ideal candidate through which to explore aspects of collaboration between humans and machines. In this paper, we introduce the witheFlow system, designed to enhance real-time music performance by automatically modulating audio effects based on features extracted from both biosignals and the audio itself. The system, currently in a proof-of-concept phase, is designed to be lightweight, able to run locally on a laptop, and is open-source given the availability of a compatible Digital Audio Workstation and sensors.
Don't Erase, Inform! Detecting and Contextualizing Harmful Language in Cultural Heritage Collections
May 30, 2025Cultural Heritage (CH) data hold invaluable knowledge, reflecting the history, traditions, and identities of societies, and shaping our understanding of the past and present. However, many CH collections contain outdated or offensive descriptions that reflect historical biases. CH Institutions (CHIs) face significant challenges in curating these data due to the vast scale and complexity of the task. To address this, we develop an AI-powered tool that detects offensive terms in CH metadata and provides contextual insights into their historical background and contemporary perception. We leverage a multilingual vocabulary co-created with marginalized communities, researchers, and CH professionals, along with traditional NLP techniques and Large Language Models (LLMs). Available as a standalone web app and integrated with major CH platforms, the tool has processed over 7.9 million records, contextualizing the contentious terms detected in their metadata. Rather than erasing these terms, our approach seeks to inform, making biases visible and providing actionable insights for creating more inclusive and accessible CH collections.
Semantic Prototypes: Enhancing Transparency Without Black Boxes
Jul 26, 2024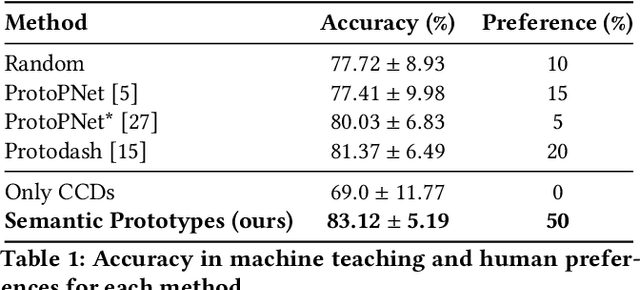



As machine learning (ML) models and datasets increase in complexity, the demand for methods that enhance explainability and interpretability becomes paramount. Prototypes, by encapsulating essential characteristics within data, offer insights that enable tactical decision-making and enhance transparency. Traditional prototype methods often rely on sub-symbolic raw data and opaque latent spaces, reducing explainability and increasing the risk of misinterpretations. This paper presents a novel framework that utilizes semantic descriptions to define prototypes and provide clear explanations, effectively addressing the shortcomings of conventional methods. Our approach leverages concept-based descriptions to cluster data on the semantic level, ensuring that prototypes not only represent underlying properties intuitively but are also straightforward to interpret. Our method simplifies the interpretative process and effectively bridges the gap between complex data structures and human cognitive processes, thereby enhancing transparency and fostering trust. Our approach outperforms existing widely-used prototype methods in facilitating human understanding and informativeness, as validated through a user survey.
Beyond One-Size-Fits-All: Adapting Counterfactual Explanations to User Objectives
Apr 12, 2024Explainable Artificial Intelligence (XAI) has emerged as a critical area of research aimed at enhancing the transparency and interpretability of AI systems. Counterfactual Explanations (CFEs) offer valuable insights into the decision-making processes of machine learning algorithms by exploring alternative scenarios where certain factors differ. Despite the growing popularity of CFEs in the XAI community, existing literature often overlooks the diverse needs and objectives of users across different applications and domains, leading to a lack of tailored explanations that adequately address the different use cases. In this paper, we advocate for a nuanced understanding of CFEs, recognizing the variability in desired properties based on user objectives and target applications. We identify three primary user objectives and explore the desired characteristics of CFEs in each case. By addressing these differences, we aim to design more effective and tailored explanations that meet the specific needs of users, thereby enhancing collaboration with AI systems.
Synergy of Machine and Deep Learning Models for Multi-Painter Recognition
Apr 28, 2023The growing availability of digitized art collections has created the need to manage, analyze and categorize large amounts of data related to abstract concepts, highlighting a demanding problem of computer science and leading to new research perspectives. Advances in artificial intelligence and neural networks provide the right tools for this challenge. The analysis of artworks to extract features useful in certain works is at the heart of the era. In the present work, we approach the problem of painter recognition in a set of digitized paintings, derived from the WikiArt repository, using transfer learning to extract the appropriate features and classical machine learning methods to evaluate the result. Through the testing of various models and their fine tuning we came to the conclusion that RegNet performs better in exporting features, while SVM makes the best classification of images based on the painter with a performance of up to 85%. Also, we introduced a new large dataset for painting recognition task including 62 artists achieving good results.