 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Prototypes: Enhancing Transparency Without Black Boxes
Jul 26, 2024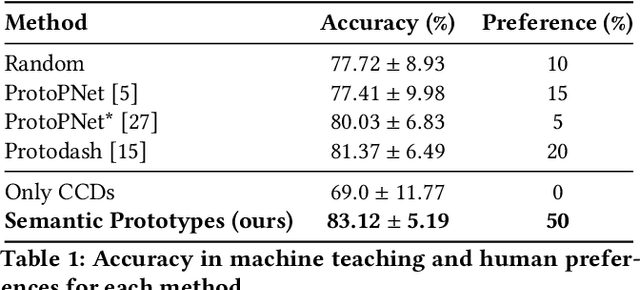



As machine learning (ML) models and datasets increase in complexity, the demand for methods that enhance explainability and interpretability becomes paramount. Prototypes, by encapsulating essential characteristics within data, offer insights that enable tactical decision-making and enhance transparency. Traditional prototype methods often rely on sub-symbolic raw data and opaque latent spaces, reducing explainability and increasing the risk of misinterpretations. This paper presents a novel framework that utilizes semantic descriptions to define prototypes and provide clear explanations, effectively addressing the shortcomings of conventional methods. Our approach leverages concept-based descriptions to cluster data on the semantic level, ensuring that prototypes not only represent underlying properties intuitively but are also straightforward to interpret. Our method simplifies the interpretative process and effectively bridges the gap between complex data structures and human cognitive processes, thereby enhancing transparency and fostering trust. Our approach outperforms existing widely-used prototype methods in facilitating human understanding and informativeness, as validated through a user survey.
Deep Ensemble Art Style Recognition
May 19, 2024

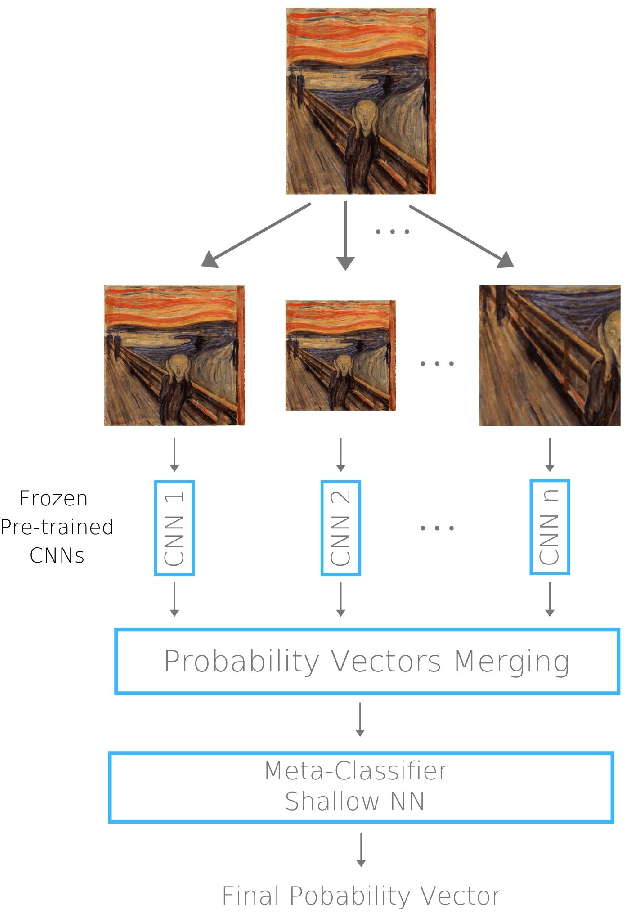

The massive digitization of artworks during the last decades created the need for categorization, analysis, and management of huge amounts of data related to abstract concepts, highlighting a challenging problem in the field of computer science. The rapid progress of artificial intelligence and neural networks has provided tools and technologies that seem worthy of the challenge. Recognition of various art features in artworks has gained attention in the deep learning society. In this paper, we are concerned with the problem of art style recognition using deep networks. We compare the performance of 8 different deep architectures (VGG16, VGG19, ResNet50, ResNet152, Inception-V3, DenseNet121, DenseNet201 and Inception-ResNet-V2), on two different art datasets, including 3 architectures that have never been used on this task before, leading to state-of-the-art performance. We study the effect of data preprocessing prior to applying a deep learning model. We introduce a stacking ensemble method combining the results of first-stage classifiers through a meta-classifier, with the innovation of a versatile approach based on multiple models that extract and recognize different characteristics of the input, creating a more consistent model compared to existing works and achieving state-of-the-art accuracy on the largest art dataset available (WikiArt - 68,55%). We also discuss the impact of the data and art styles themselves on the performance of our models forming a manifold perspective on the problem.
Counterfactuals of Counterfactuals: a back-translation-inspired approach to analyse counterfactual editors
May 26, 2023



In the wake of responsible AI, interpretability methods, which attempt to provide an explanation for the predictions of neural models have seen rapid progress. In this work, we are concerned with explanations that are applicable to natural language processing (NLP) models and tasks, and we focus specifically on the analysis of counterfactual, contrastive explanations. We note that while there have been several explainers proposed to produce counterfactual explanations, their behaviour can vary significantly and the lack of a universal ground truth for the counterfactual edits imposes an insuperable barrier on their evaluation. We propose a new back translation-inspired evaluation methodology that utilises earlier outputs of the explainer as ground truth proxies to investigate the consistency of explainers. We show that by iteratively feeding the counterfactual to the explainer we can obtain valuable insights into the behaviour of both the predictor and the explainer models, and infer patterns that would be otherwise obscured. Using this methodology, we conduct a thorough analysis and propose a novel metric to evaluate the consistency of counterfactual generation approaches with different characteristics across available performance indicators.
Computing Rule-Based Explanations of Machine Learning Classifiers using Knowledge Graphs
Feb 08, 2022
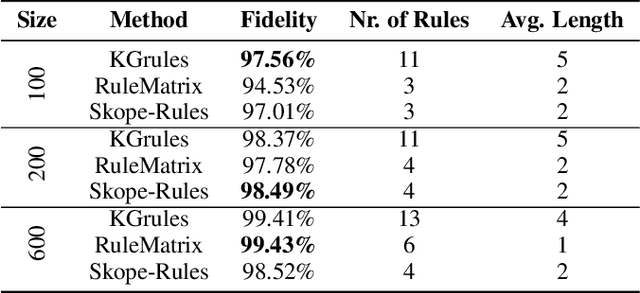
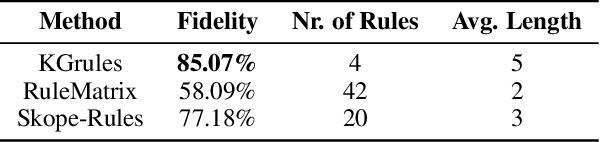

The use of symbolic knowledge representation and reasoning as a way to resolve the lack of transparency of machine learning classifiers is a research area that lately attracts many researchers. In this work, we use knowledge graphs as the underlying framework providing the terminology for representing explanations for the operation of a machine learning classifier. In particular, given a description of the application domain of the classifier in the form of a knowledge graph, we introduce a novel method for extracting and representing black-box explanations of its operation, in the form of first-order logic rules expressed in the terminology of the knowledge graph.