 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMusicLIME: Explainable Multimodal Music Understanding
Sep 16, 2024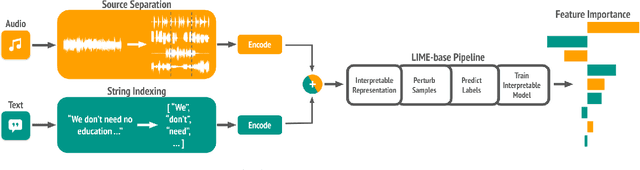

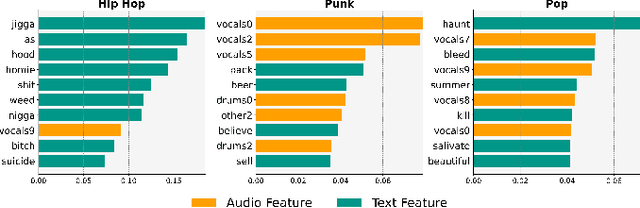
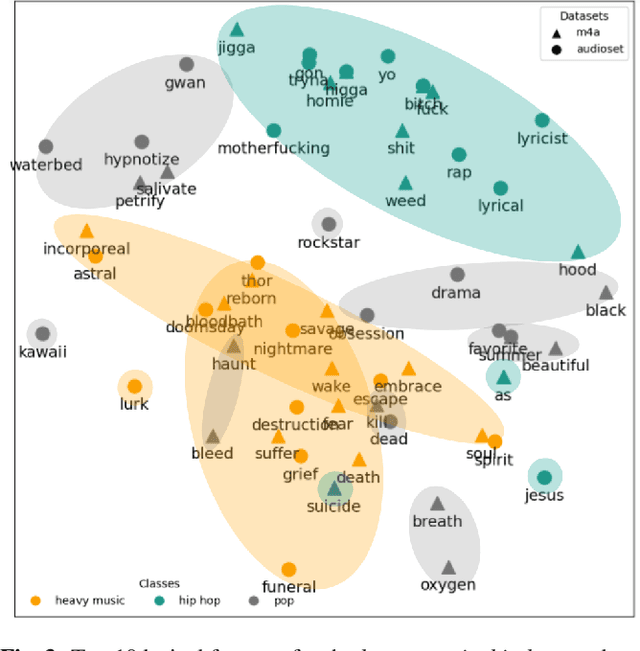
Multimodal models are critical for music understanding tasks, as they capture the complex interplay between audio and lyrics. However, as these models become more prevalent, the need for explainability grows-understanding how these systems make decisions is vital for ensuring fairness, reducing bias, and fostering trust. In this paper, we introduce MusicLIME, a model-agnostic feature importance explanation method designed for multimodal music models. Unlike traditional unimodal methods, which analyze each modality separately without considering the interaction between them, often leading to incomplete or misleading explanations, MusicLIME reveals how audio and lyrical features interact and contribute to predictions, providing a holistic view of the model's decision-making. Additionally, we enhance local explanations by aggregating them into global explanations, giving users a broader perspective of model behavior. Through this work, we contribute to improving the interpretability of multimodal music models, empowering users to make informed choices, and fostering more equitable, fair, and transparent music understanding systems.