 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing adversarial robustness in Natural Language Inference using explanations
Paper and Code
Sep 11, 2024
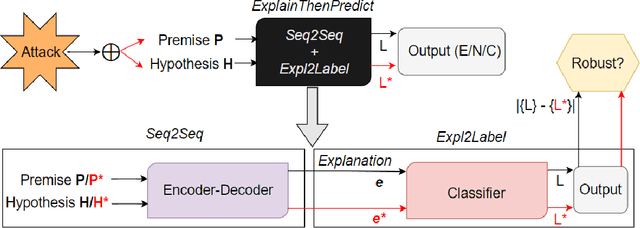


The surge of state-of-the-art Transformer-based models has undoubtedly pushed the limits of NLP model performance, excelling in a variety of tasks. We cast the spotlight on the underexplored task of Natural Language Inference (NLI), since models trained on popular well-suited datasets are susceptible to adversarial attacks, allowing subtle input interventions to mislead the model. In this work, we validate the usage of natural language explanation as a model-agnostic defence strategy through extensive experimentation: only by fine-tuning a classifier on the explanation rather than premise-hypothesis inputs, robustness under various adversarial attacks is achieved in comparison to explanation-free baselines. Moreover, since there is no standard strategy of testing the semantic validity of the generated explanations, we research the correlation of widely used language generation metrics with human perception, in order for them to serve as a proxy towards robust NLI models. Our approach is resource-efficient and reproducible without significant computational limitations.