 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTeaching Language Models to Faithfully Express their Uncertainty
Oct 14, 2025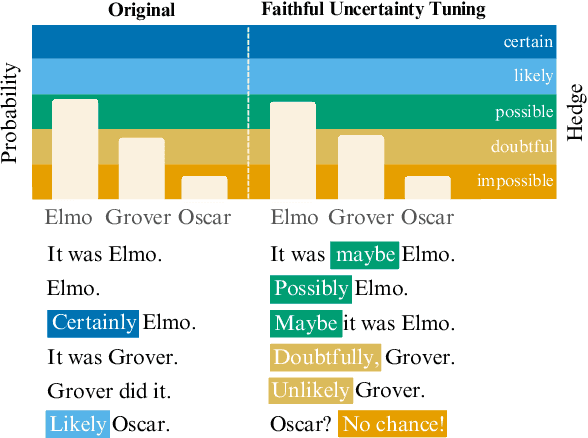
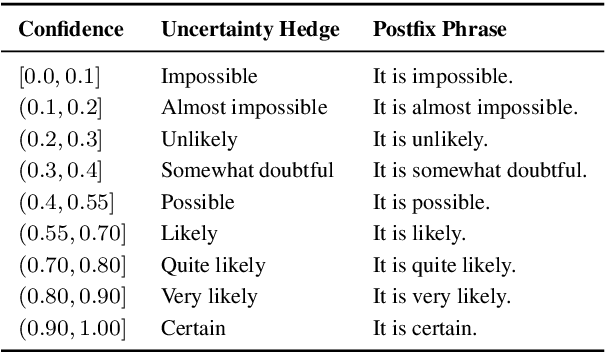
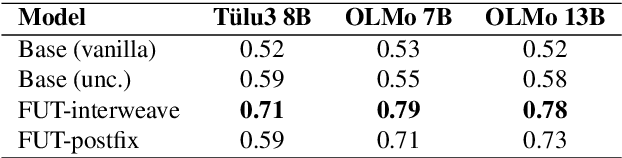
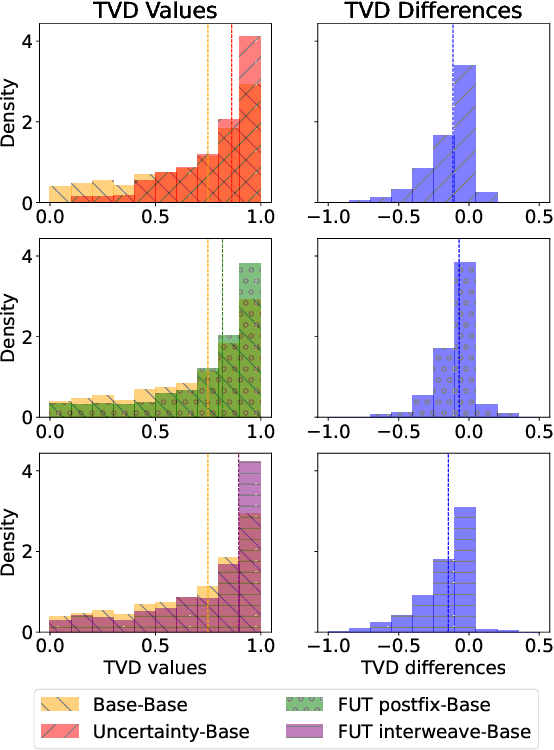
Large language models (LLMs) often miscommunicate their uncertainty: repeated queries can produce divergent answers, yet generated responses are typically unhedged or hedged in ways that do not reflect this variability. This conveys unfaithful information about the uncertain state of the LLMs' knowledge, creating a faithfulness gap that affects even strong LLMs. We introduce Faithful Uncertainty Tuning (FUT): a fine-tuning approach that teaches instruction-tuned LLMs to express uncertainty faithfully without altering their underlying answer distribution. We construct training data by augmenting model samples with uncertainty hedges (i.e. verbal cues such as 'possibly' or 'likely') aligned with sample consistency, requiring no supervision beyond the model and a set of prompts. We evaluate FUT on open-domain question answering (QA) across multiple models and datasets. Our results show that FUT substantially reduces the faithfulness gap, while preserving QA accuracy and introducing minimal semantic distribution shift. Further analyses demonstrate robustness across decoding strategies, choice of hedgers, and other forms of uncertainty expression (i.e. numerical). These findings establish FUT as a simple and effective way to teach LLMs to communicate uncertainty faithfully.
Variability Need Not Imply Error: The Case of Adequate but Semantically Distinct Responses
Dec 20, 2024With the broader use of language models (LMs) comes the need to estimate their ability to respond reliably to prompts (e.g., are generated responses likely to be correct?). Uncertainty quantification tools (notions of confidence and entropy, i.a.) can be used to that end (e.g., to reject a response when the model is `uncertain'). For example, Kuhn et al. (semantic entropy; 2022b) regard semantic variation amongst sampled responses as evidence that the model `struggles' with the prompt and that the LM is likely to err. We argue that semantic variability need not imply error--this being especially intuitive in open-ended settings, where prompts elicit multiple adequate but semantically distinct responses. Hence, we propose to annotate sampled responses for their adequacy to the prompt (e.g., using a classifier) and estimate the Probability the model assigns to Adequate Responses (PROBAR), which we then regard as an indicator of the model's reliability at the instance level. We evaluate PROBAR as a measure of confidence in selective prediction with OPT models (in two QA datasets and in next-word prediction, for English) and find PROBAR to outperform semantic entropy across prompts with varying degrees of ambiguity/open-endedness.
Predict the Next Word: <Humans exhibit uncertainty in this task and language models _____>
Feb 27, 2024Language models (LMs) are statistical models trained to assign probability to human-generated text. As such, it is reasonable to question whether they approximate linguistic variability exhibited by humans well. This form of statistical assessment is difficult to perform at the passage level, for it requires acceptability judgements (i.e., human evaluation) or a robust automated proxy (which is non-trivial). At the word level, however, given some context, samples from an LM can be assessed via exact matching against a prerecorded dataset of alternative single-word continuations of the available context. We exploit this fact and evaluate the LM's ability to reproduce variability that humans (in particular, a population of English speakers) exhibit in the 'next word prediction' task. This can be seen as assessing a form of calibration, which, in the context of text classification, Baan et al. (2022) termed calibration to human uncertainty. We assess GPT2, BLOOM and ChatGPT and find that they exhibit fairly low calibration to human uncertainty. We also verify the failure of expected calibration error (ECE) to reflect this, and as such, advise the community against relying on it in this setting.
Uncertainty in Natural Language Generation: From Theory to Applications
Jul 28, 2023

Recent advances of powerful Language Models have allowed Natural Language Generation (NLG) to emerge as an important technology that can not only perform traditional tasks like summarisation or translation, but also serve as a natural language interface to a variety of applications. As such, it is crucial that NLG systems are trustworthy and reliable, for example by indicating when they are likely to be wrong; and supporting multiple views, backgrounds and writing styles -- reflecting diverse human sub-populations. In this paper, we argue that a principled treatment of uncertainty can assist in creating systems and evaluation protocols better aligned with these goals. We first present the fundamental theory, frameworks and vocabulary required to represent uncertainty. We then characterise the main sources of uncertainty in NLG from a linguistic perspective, and propose a two-dimensional taxonomy that is more informative and faithful than the popular aleatoric/epistemic dichotomy. Finally, we move from theory to applications and highlight exciting research directions that exploit uncertainty to power decoding, controllable generation, self-assessment, selective answering, active learning and more.