 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpreting Predictive Probabilities: Model Confidence or Human Label Variation?
Feb 25, 2024With the rise of increasingly powerful and user-facing NLP systems, there is growing interest in assessing whether they have a good representation of uncertainty by evaluating the quality of their predictive distribution over outcomes. We identify two main perspectives that drive starkly different evaluation protocols. The first treats predictive probability as an indication of model confidence; the second as an indication of human label variation. We discuss their merits and limitations, and take the position that both are crucial for trustworthy and fair NLP systems, but that exploiting a single predictive distribution is limiting. We recommend tools and highlight exciting directions towards models with disentangled representations of uncertainty about predictions and uncertainty about human labels.
Uncertainty in Natural Language Generation: From Theory to Applications
Jul 28, 2023

Recent advances of powerful Language Models have allowed Natural Language Generation (NLG) to emerge as an important technology that can not only perform traditional tasks like summarisation or translation, but also serve as a natural language interface to a variety of applications. As such, it is crucial that NLG systems are trustworthy and reliable, for example by indicating when they are likely to be wrong; and supporting multiple views, backgrounds and writing styles -- reflecting diverse human sub-populations. In this paper, we argue that a principled treatment of uncertainty can assist in creating systems and evaluation protocols better aligned with these goals. We first present the fundamental theory, frameworks and vocabulary required to represent uncertainty. We then characterise the main sources of uncertainty in NLG from a linguistic perspective, and propose a two-dimensional taxonomy that is more informative and faithful than the popular aleatoric/epistemic dichotomy. Finally, we move from theory to applications and highlight exciting research directions that exploit uncertainty to power decoding, controllable generation, self-assessment, selective answering, active learning and more.
What Comes Next? Evaluating Uncertainty in Neural Text Generators Against Human Production Variability
May 19, 2023



In Natural Language Generation (NLG) tasks, for any input, multiple communicative goals are plausible, and any goal can be put into words, or produced, in multiple ways. We characterise the extent to which human production varies lexically, syntactically, and semantically across four NLG tasks, connecting human production variability to aleatoric or data uncertainty. We then inspect the space of output strings shaped by a generation system's predicted probability distribution and decoding algorithm to probe its uncertainty. For each test input, we measure the generator's calibration to human production variability. Following this instance-level approach, we analyse NLG models and decoding strategies, demonstrating that probing a generator with multiple samples and, when possible, multiple references, provides the level of detail necessary to gain understanding of a model's representation of uncertainty.
Stop Measuring Calibration When Humans Disagree
Oct 28, 2022

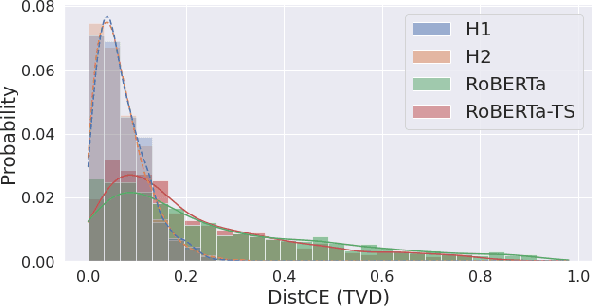

Calibration is a popular framework to evaluate whether a classifier knows when it does not know - i.e., its predictive probabilities are a good indication of how likely a prediction is to be correct. Correctness is commonly estimated against the human majority class. Recently, calibration to human majority has been measured on tasks where humans inherently disagree about which class applies. We show that measuring calibration to human majority given inherent disagreements is theoretically problematic, demonstrate this empirically on the ChaosNLI dataset, and derive several instance-level measures of calibration that capture key statistical properties of human judgements - class frequency, ranking and entropy.
Understanding Multi-Head Attention in Abstractive Summarization
Nov 10, 2019

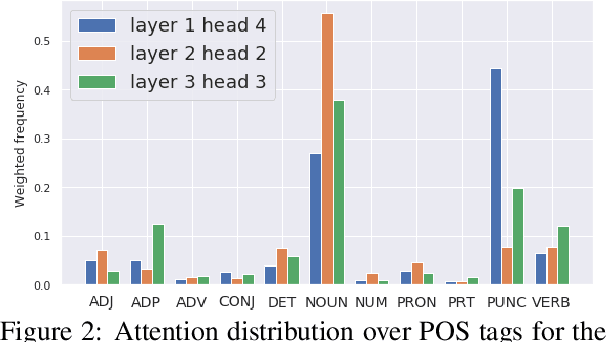
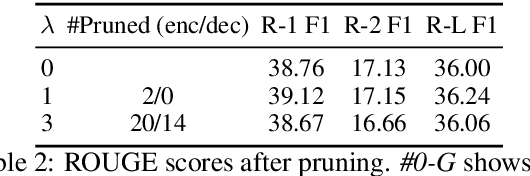
Attention mechanisms in deep learning architectures have often been used as a means of transparency and, as such, to shed light on the inner workings of the architectures. Recently, there has been a growing interest in whether or not this assumption is correct. In this paper we investigate the interpretability of multi-head attention in abstractive summarization, a sequence-to-sequence task for which attention does not have an intuitive alignment role, such as in machine translation. We first introduce three metrics to gain insight in the focus of attention heads and observe that these heads specialize towards relative positions, specific part-of-speech tags, and named entities. However, we also find that ablating and pruning these heads does not lead to a significant drop in performance, indicating redundancy. By replacing the softmax activation functions with sparsemax activation functions, we find that attention heads behave seemingly more transparent: we can ablate fewer heads and heads score higher on our interpretability metrics. However, if we apply pruning to the sparsemax model we find that we can prune even more heads, raising the question whether enforced sparsity actually improves transparency. Finally, we find that relative positions heads seem integral to summarization performance and persistently remain after pruning.
Do Transformer Attention Heads Provide Transparency in Abstractive Summarization?
Jul 08, 2019
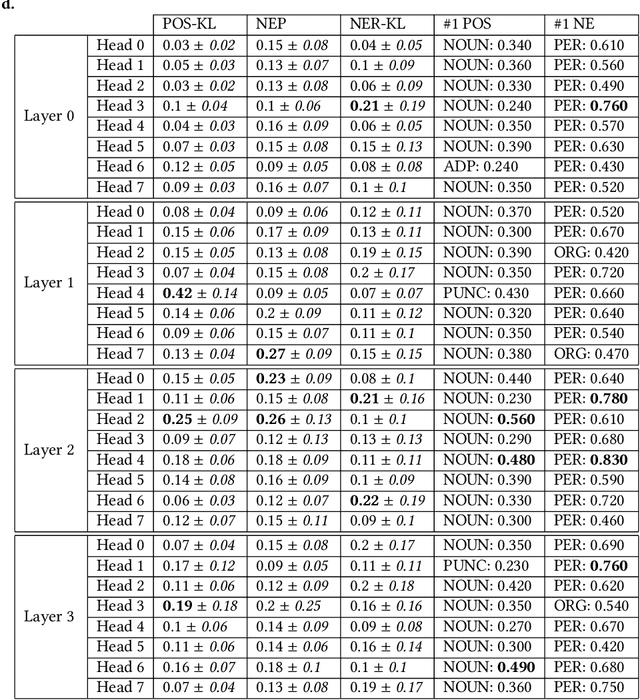

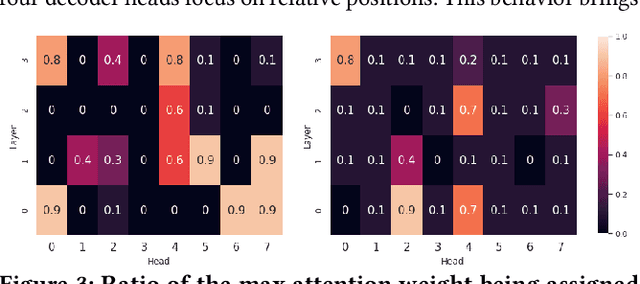
Learning algorithms become more powerful, often at the cost of increased complexity. In response, the demand for algorithms to be transparent is growing. In NLP tasks, attention distributions learned by attention-based deep learning models are used to gain insights in the models' behavior. To which extent is this perspective valid for all NLP tasks? We investigate whether distributions calculated by different attention heads in a transformer architecture can be used to improve transparency in the task of abstractive summarization. To this end, we present both a qualitative and quantitative analysis to investigate the behavior of the attention heads. We show that some attention heads indeed specialize towards syntactically and semantically distinct input. We propose an approach to evaluate to which extent the Transformer model relies on specifically learned attention distributions. We also discuss what this implies for using attention distributions as a means of transparency.
On the Realization of Compositionality in Neural Networks
Jun 06, 2019
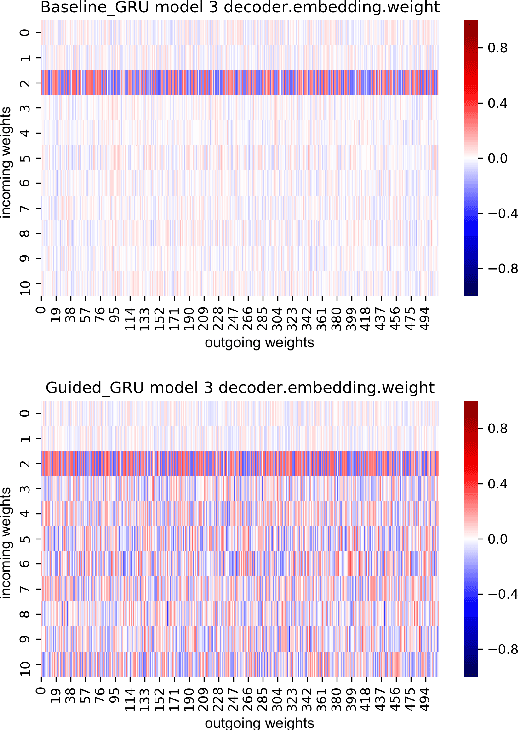
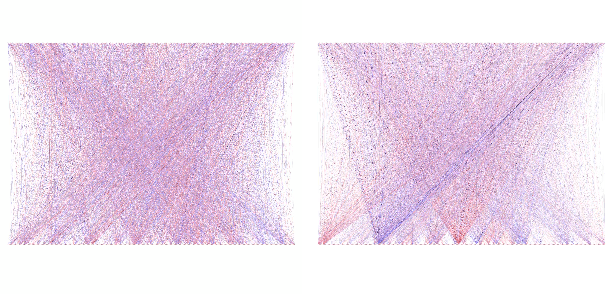
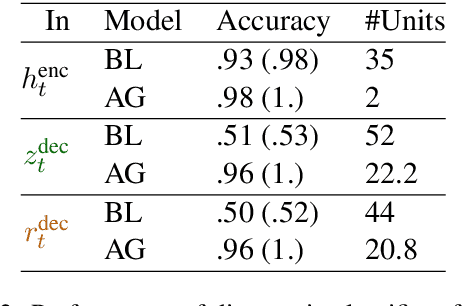
We present a detailed comparison of two types of sequence to sequence models trained to conduct a compositional task. The models are architecturally identical at inference time, but differ in the way that they are trained: our baseline model is trained with a task-success signal only, while the other model receives additional supervision on its attention mechanism (Attentive Guidance), which has shown to be an effective method for encouraging more compositional solutions (Hupkes et al.,2019). We first confirm that the models with attentive guidance indeed infer more compositional solutions than the baseline, by training them on the lookup table task presented by Li\v{s}ka et al. (2019). We then do an in-depth analysis of the structural differences between the two model types, focusing in particular on the organisation of the parameter space and the hidden layer activations and find noticeable differences in both these aspects. Guided networks focus more on the components of the input rather than the sequence as a whole and develop small functional groups of neurons with specific purposes that use their gates more selectively. Results from parameter heat maps, component swapping and graph analysis also indicate that guided networks exhibit a more modular structure with a small number of specialized, strongly connected neurons.