 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen the Music Stops: Tip-of-the-Tongue Retrieval for Music
May 23, 2023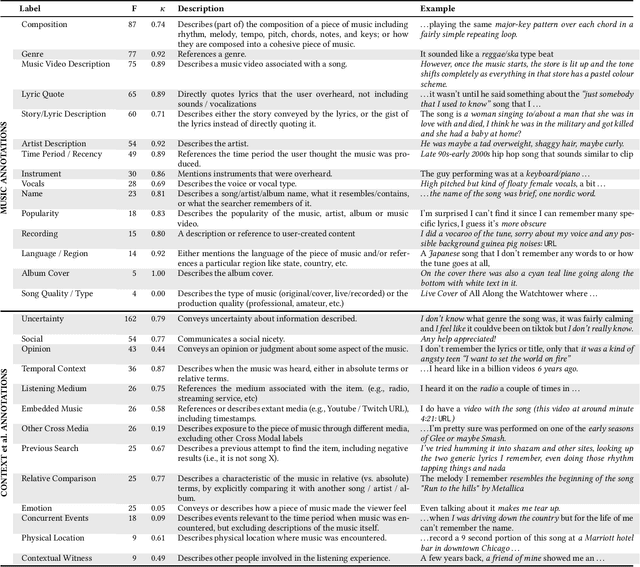
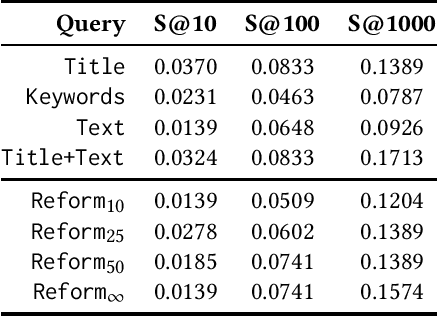
We present a study of Tip-of-the-tongue (ToT) retrieval for music, where a searcher is trying to find an existing music entity, but is unable to succeed as they cannot accurately recall important identifying information. ToT information needs are characterized by complexity, verbosity, uncertainty, and possible false memories. We make four contributions. (1) We collect a dataset - $ToT_{Music}$ - of 2,278 information needs and ground truth answers. (2) We introduce a schema for these information needs and show that they often involve multiple modalities encompassing several Music IR subtasks such as lyric search, audio-based search, audio fingerprinting, and text search. (3) We underscore the difficulty of this task by benchmarking a standard text retrieval approach on this dataset. (4) We investigate the efficacy of query reformulations generated by a large language model (LLM), and show that they are not as effective as simply employing the entire information need as a query - leaving several open questions for future research.
Understanding Multi-Head Attention in Abstractive Summarization
Nov 10, 2019

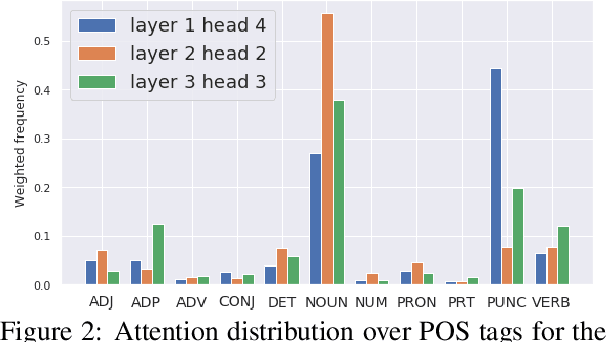
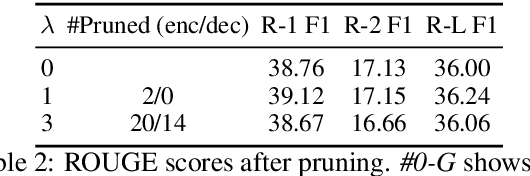
Attention mechanisms in deep learning architectures have often been used as a means of transparency and, as such, to shed light on the inner workings of the architectures. Recently, there has been a growing interest in whether or not this assumption is correct. In this paper we investigate the interpretability of multi-head attention in abstractive summarization, a sequence-to-sequence task for which attention does not have an intuitive alignment role, such as in machine translation. We first introduce three metrics to gain insight in the focus of attention heads and observe that these heads specialize towards relative positions, specific part-of-speech tags, and named entities. However, we also find that ablating and pruning these heads does not lead to a significant drop in performance, indicating redundancy. By replacing the softmax activation functions with sparsemax activation functions, we find that attention heads behave seemingly more transparent: we can ablate fewer heads and heads score higher on our interpretability metrics. However, if we apply pruning to the sparsemax model we find that we can prune even more heads, raising the question whether enforced sparsity actually improves transparency. Finally, we find that relative positions heads seem integral to summarization performance and persistently remain after pruning.
DpgMedia2019: A Dutch News Dataset for Partisanship Detection
Aug 06, 2019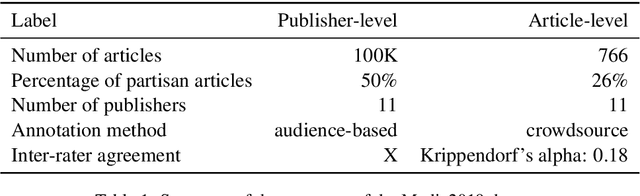
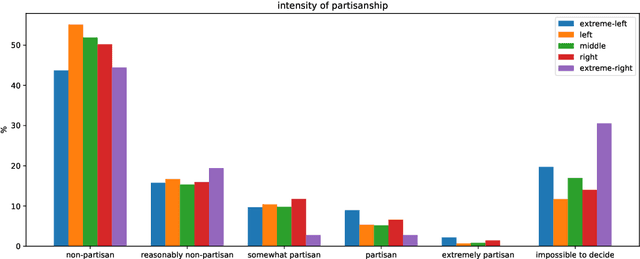
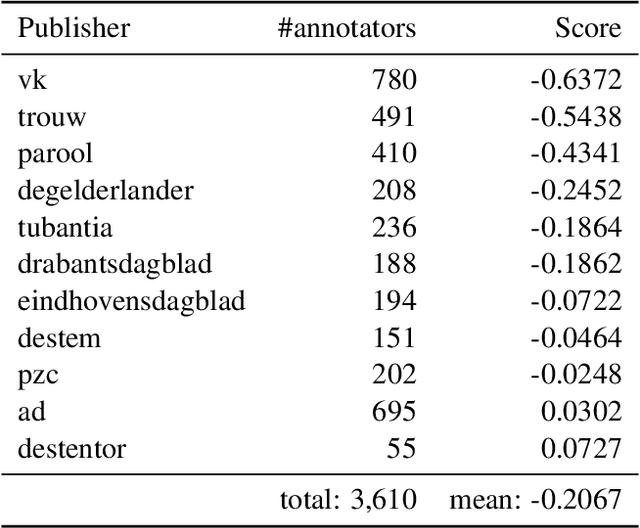
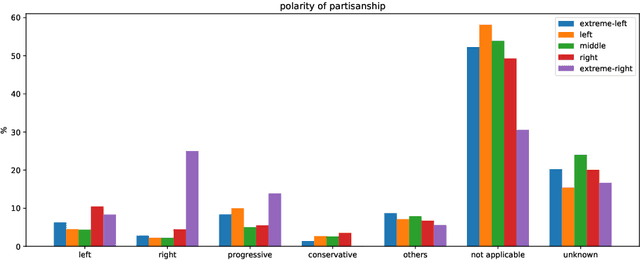
We present a new Dutch news dataset with labeled partisanship. The dataset contains more than 100K articles that are labeled on the publisher level and 776 articles that were crowdsourced using an internal survey platform and labeled on the article level. In this paper, we document our original motivation, the collection and annotation process, limitations, and applications.
Do Transformer Attention Heads Provide Transparency in Abstractive Summarization?
Jul 08, 2019
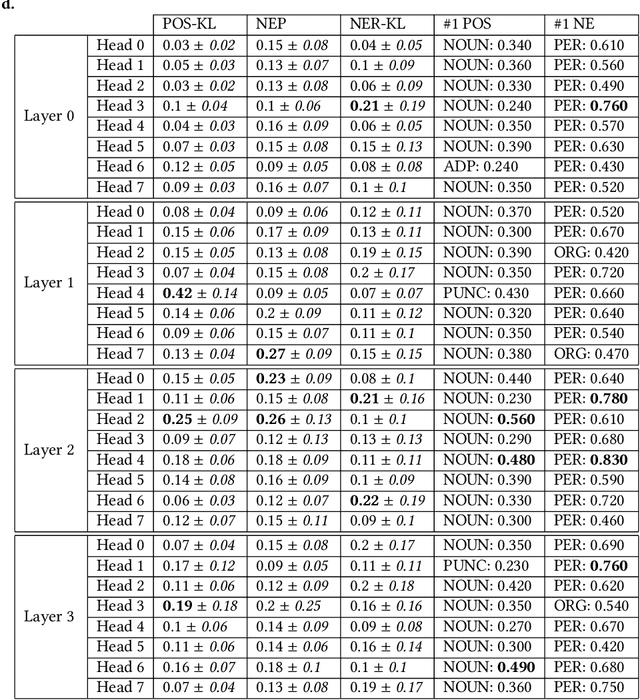

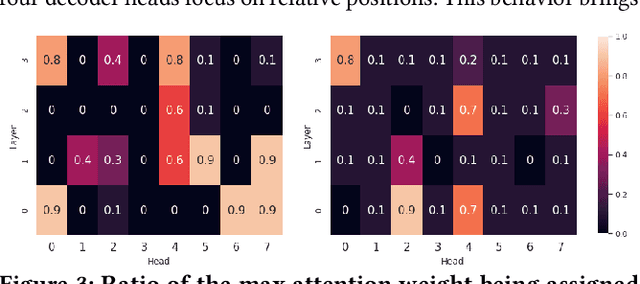
Learning algorithms become more powerful, often at the cost of increased complexity. In response, the demand for algorithms to be transparent is growing. In NLP tasks, attention distributions learned by attention-based deep learning models are used to gain insights in the models' behavior. To which extent is this perspective valid for all NLP tasks? We investigate whether distributions calculated by different attention heads in a transformer architecture can be used to improve transparency in the task of abstractive summarization. To this end, we present both a qualitative and quantitative analysis to investigate the behavior of the attention heads. We show that some attention heads indeed specialize towards syntactically and semantically distinct input. We propose an approach to evaluate to which extent the Transformer model relies on specifically learned attention distributions. We also discuss what this implies for using attention distributions as a means of transparency.
Faithfully Explaining Rankings in a News Recommender System
May 14, 2018
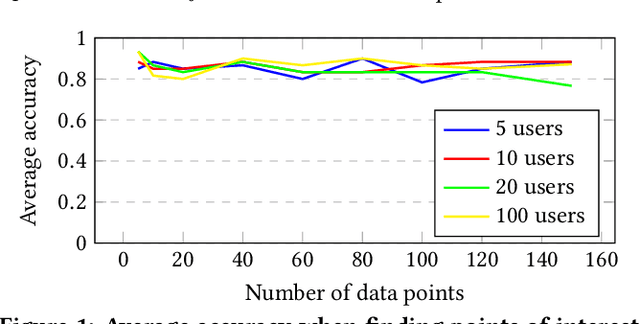

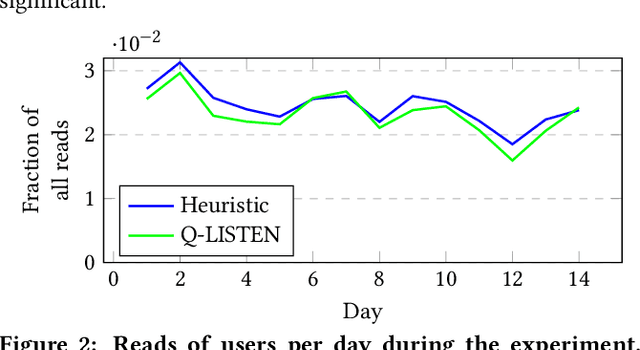
There is an increasing demand for algorithms to explain their outcomes. So far, there is no method that explains the rankings produced by a ranking algorithm. To address this gap we propose LISTEN, a LISTwise ExplaiNer, to explain rankings produced by a ranking algorithm. To efficiently use LISTEN in production, we train a neural network to learn the underlying explanation space created by LISTEN; we call this model Q-LISTEN. We show that LISTEN produces faithful explanations and that Q-LISTEN is able to learn these explanations. Moreover, we show that LISTEN is safe to use in a real world environment: users of a news recommendation system do not behave significantly differently when they are exposed to explanations generated by LISTEN instead of manually generated explanations.