 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comprehensive Taxonomy of Negation for NLP and Neural Retrievers
Jul 30, 2025Understanding and solving complex reasoning tasks is vital for addressing the information needs of a user. Although dense neural models learn contextualised embeddings, they still underperform on queries containing negation. To understand this phenomenon, we study negation in both traditional neural information retrieval and LLM-based models. We (1) introduce a taxonomy of negation that derives from philosophical, linguistic, and logical definitions; (2) generate two benchmark datasets that can be used to evaluate the performance of neural information retrieval models and to fine-tune models for a more robust performance on negation; and (3) propose a logic-based classification mechanism that can be used to analyze the performance of retrieval models on existing datasets. Our taxonomy produces a balanced data distribution over negation types, providing a better training setup that leads to faster convergence on the NevIR dataset. Moreover, we propose a classification schema that reveals the coverage of negation types in existing datasets, offering insights into the factors that might affect the generalization of fine-tuned models on negation.
Interpreting Affine Recurrence Learning in GPT-style Transformers
Oct 22, 2024Understanding the internal mechanisms of GPT-style transformers, particularly their capacity to perform in-context learning (ICL), is critical for advancing AI alignment and interpretability. In-context learning allows transformers to generalize during inference without modifying their weights, yet the precise operations driving this capability remain largely opaque. This paper presents an investigation into the mechanistic interpretability of these transformers, focusing specifically on their ability to learn and predict affine recurrences as an ICL task. To address this, we trained a custom three-layer transformer to predict affine recurrences and analyzed the model's internal operations using both empirical and theoretical approaches. Our findings reveal that the model forms an initial estimate of the target sequence using a copying mechanism in the zeroth layer, which is subsequently refined through negative similarity heads in the second layer. These insights contribute to a deeper understanding of transformer behaviors in recursive tasks and offer potential avenues for improving AI alignment through mechanistic interpretability. Finally, we discuss the implications of our results for future work, including extensions to higher-dimensional recurrences and the exploration of polynomial sequences.
RecFusion: A Binomial Diffusion Process for 1D Data for Recommendation
Jun 19, 2023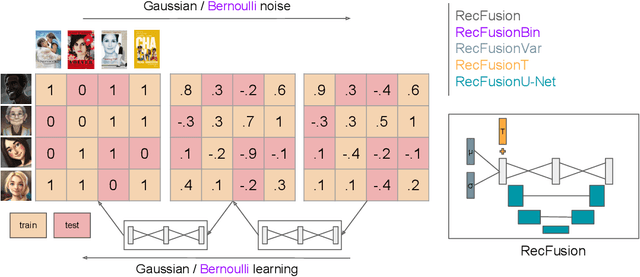
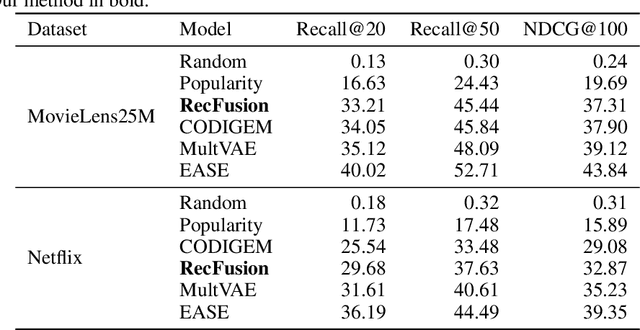
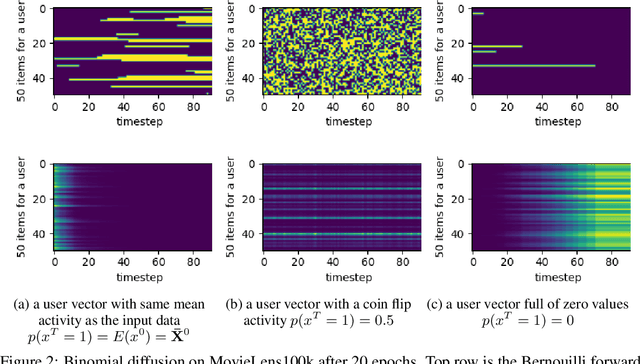
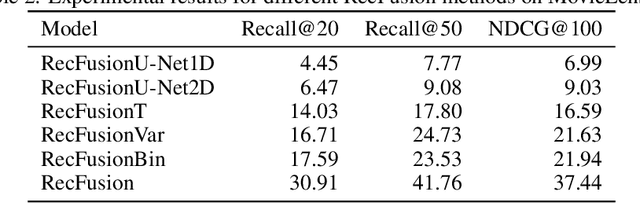
In this paper we propose RecFusion, which comprise a set of diffusion models for recommendation. Unlike image data which contain spatial correlations, a user-item interaction matrix, commonly utilized in recommendation, lacks spatial relationships between users and items. We formulate diffusion on a 1D vector and propose binomial diffusion, which explicitly models binary user-item interactions with a Bernoulli process. We show that RecFusion approaches the performance of complex VAE baselines on the core recommendation setting (top-n recommendation for binary non-sequential feedback) and the most common datasets (MovieLens and Netflix). Our proposed diffusion models that are specialized for 1D and/or binary setups have implications beyond recommendation systems, such as in the medical domain with MRI and CT scans.
When the Music Stops: Tip-of-the-Tongue Retrieval for Music
May 23, 2023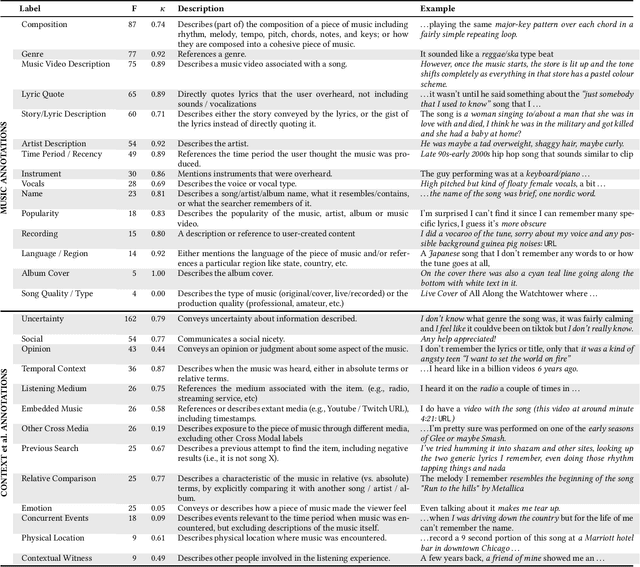
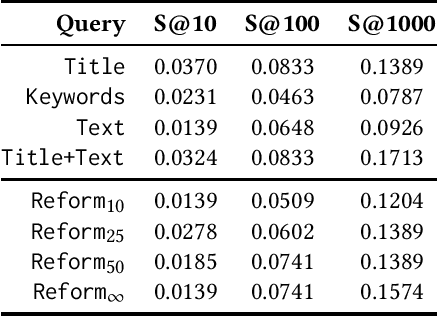
We present a study of Tip-of-the-tongue (ToT) retrieval for music, where a searcher is trying to find an existing music entity, but is unable to succeed as they cannot accurately recall important identifying information. ToT information needs are characterized by complexity, verbosity, uncertainty, and possible false memories. We make four contributions. (1) We collect a dataset - $ToT_{Music}$ - of 2,278 information needs and ground truth answers. (2) We introduce a schema for these information needs and show that they often involve multiple modalities encompassing several Music IR subtasks such as lyric search, audio-based search, audio fingerprinting, and text search. (3) We underscore the difficulty of this task by benchmarking a standard text retrieval approach on this dataset. (4) We investigate the efficacy of query reformulations generated by a large language model (LLM), and show that they are not as effective as simply employing the entire information need as a query - leaving several open questions for future research.
Market-Aware Models for Efficient Cross-Market Recommendation
Feb 14, 2023We consider the cross-market recommendation (CMR) task, which involves recommendation in a low-resource target market using data from a richer, auxiliary source market. Prior work in CMR utilised meta-learning to improve recommendation performance in target markets; meta-learning however can be complex and resource intensive. In this paper, we propose market-aware (MA) models, which directly model a market via market embeddings instead of meta-learning across markets. These embeddings transform item representations into market-specific representations. Our experiments highlight the effectiveness and efficiency of MA models both in a pairwise setting with a single target-source market, as well as a global model trained on all markets in unison. In the former pairwise setting, MA models on average outperform market-unaware models in 85% of cases on nDCG@10, while being time-efficient - compared to meta-learning models, MA models require only 15% of the training time. In the global setting, MA models outperform market-unaware models consistently for some markets, while outperforming meta-learning-based methods for all but one market. We conclude that MA models are an efficient and effective alternative to meta-learning, especially in the global setting.
Teaching Fairness, Accountability, Confidentiality, and Transparency in Artificial Intelligence through the Lens of Reproducibility
Nov 09, 2021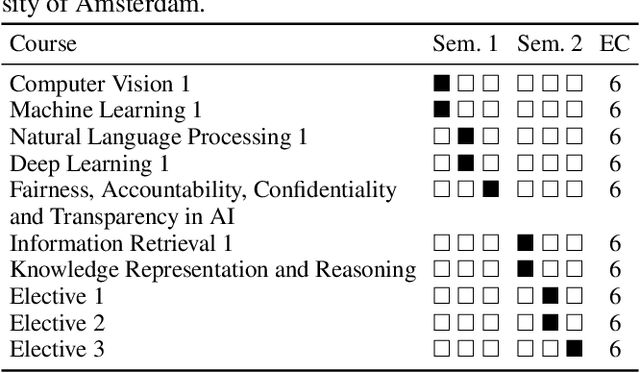
In this work we explain the setup for a technical, graduate-level course on Fairness, Accountability, Confidentiality and Transparency in Artificial Intelligence (FACT-AI) at the University of Amsterdam, which teaches FACT-AI concepts through the lens of reproducibility. The focal point of the course is a group project based on reproducing existing FACT-AI algorithms from top AI conferences, and writing a report about their experiences. In the first iteration of the course, we created an open source repository with the code implementations from the group projects. In the second iteration, we encouraged students to submit their group projects to the Machine Learning Reproducibility Challenge, which resulted in 9 reports from our course being accepted to the challenge. We reflect on our experience teaching the course over two academic years, where one year coincided with a global pandemic, and propose guidelines for teaching FACT-AI through reproducibility in graduate-level AI programs. We hope this can be a useful resource for instructors to set up similar courses at their universities in the future.
Controllable Recommenders using Deep Generative Models and Disentanglement
Oct 11, 2021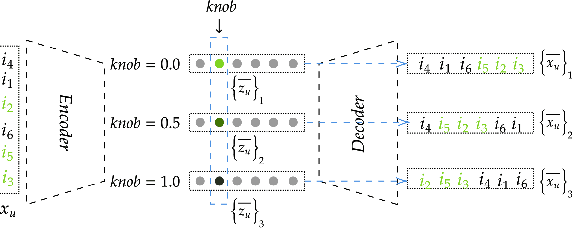
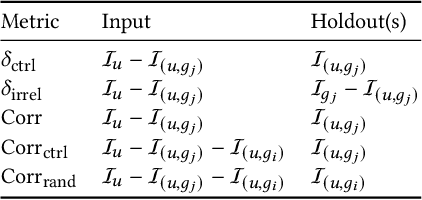

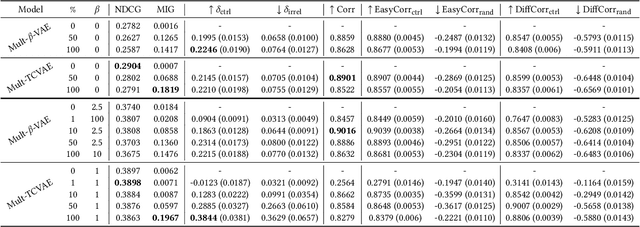
In this paper, we consider controllability as a means to satisfy dynamic preferences of users, enabling them to control recommendations such that their current preference is met. While deep models have shown improved performance for collaborative filtering, they are generally not amenable to fine grained control by a user, leading to the development of methods like deep language critiquing. We propose an alternate view, where instead of keyphrase based critiques, a user is provided 'knobs' in a disentangled latent space, with each knob corresponding to an item aspect. Disentanglement here refers to a latent space where generative factors (here, a preference towards an item category like genre) are captured independently in their respective dimensions, thereby enabling predictable manipulations, otherwise not possible in an entangled space. We propose using a (semi-)supervised disentanglement objective for this purpose, as well as multiple metrics to evaluate the controllability and the degree of personalization of controlled recommendations. We show that by updating the disentangled latent space based on user feedback, and by exploiting the generative nature of the recommender, controlled and personalized recommendations can be produced. Through experiments on two widely used collaborative filtering datasets, we demonstrate that a controllable recommender can be trained with a slight reduction in recommender performance, provided enough supervision is provided. The recommendations produced by these models appear to both conform to a user's current preference and remain personalized.
Robustness Evaluation of Entity Disambiguation Using Prior Probes:the Case of Entity Overshadowing
Aug 24, 2021
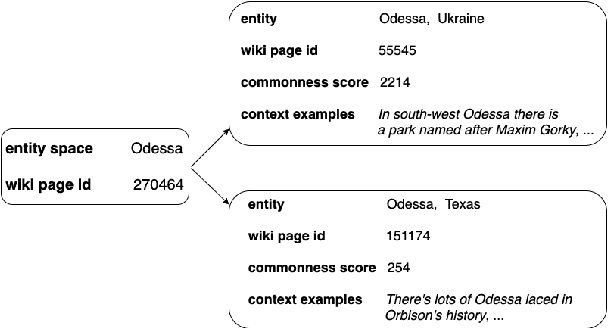
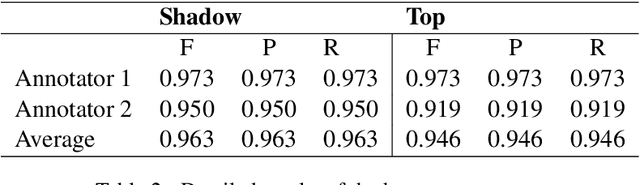
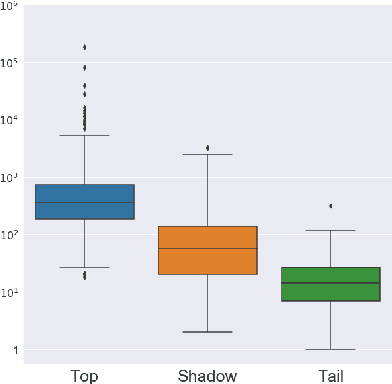
Entity disambiguation (ED) is the last step of entity linking (EL), when candidate entities are reranked according to the context they appear in. All datasets for training and evaluating models for EL consist of convenience samples, such as news articles and tweets, that propagate the prior probability bias of the entity distribution towards more frequently occurring entities. It was previously shown that the performance of the EL systems on such datasets is overestimated since it is possible to obtain higher accuracy scores by merely learning the prior. To provide a more adequate evaluation benchmark, we introduce the ShadowLink dataset, which includes 16K short text snippets annotated with entity mentions. We evaluate and report the performance of popular EL systems on the ShadowLink benchmark. The results show a considerable difference in accuracy between more and less common entities for all of the EL systems under evaluation, demonstrating the effects of prior probability bias and entity overshadowing.
Sinkhorn AutoEncoders
Oct 03, 2018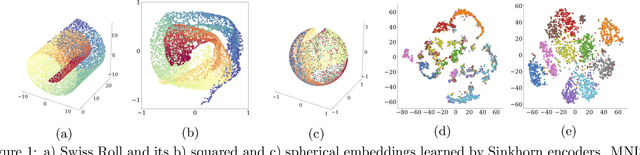
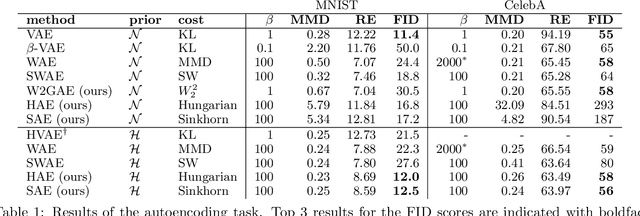

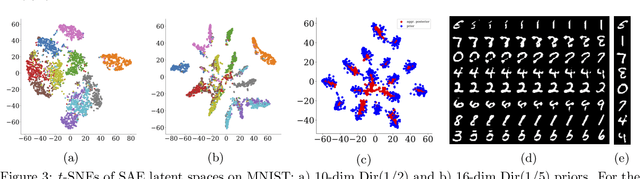
Optimal Transport offers an alternative to maximum likelihood for learning generative autoencoding models. We show how this principle dictates the minimization of the Wasserstein distance between the encoder aggregated posterior and the prior, plus a reconstruction error. We prove that in the non-parametric limit the autoencoder generates the data distribution if and only if the two distributions match exactly, and that the optimum can be obtained by deterministic autoencoders. We then introduce the Sinkhorn AutoEncoder (SAE), which casts the problem into Optimal Transport on the latent space. The resulting Wasserstein distance is minimized by backpropagating through the Sinkhorn algorithm. SAE models the aggregated posterior as an implicit distribution and therefore does not need a reparameterization trick for gradients estimation. Moreover, it requires virtually no adaptation to different prior distributions. We demonstrate its flexibility by considering models with hyperspherical and Dirichlet priors, as well as a simple case of probabilistic programming. SAE matches or outperforms other autoencoding models in visual quality and FID scores.