 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccurate and scalable exchange-correlation with deep learning
Jun 18, 2025Density Functional Theory (DFT) is the most widely used electronic structure method for predicting the properties of molecules and materials. Although DFT is, in principle, an exact reformulation of the Schr\"odinger equation, practical applications rely on approximations to the unknown exchange-correlation (XC) functional. Most existing XC functionals are constructed using a limited set of increasingly complex, hand-crafted features that improve accuracy at the expense of computational efficiency. Yet, no current approximation achieves the accuracy and generality for predictive modeling of laboratory experiments at chemical accuracy -- typically defined as errors below 1 kcal/mol. In this work, we present Skala, a modern deep learning-based XC functional that bypasses expensive hand-designed features by learning representations directly from data. Skala achieves chemical accuracy for atomization energies of small molecules while retaining the computational efficiency typical of semi-local DFT. This performance is enabled by training on an unprecedented volume of high-accuracy reference data generated using computationally intensive wavefunction-based methods. Notably, Skala systematically improves with additional training data covering diverse chemistry. By incorporating a modest amount of additional high-accuracy data tailored to chemistry beyond atomization energies, Skala achieves accuracy competitive with the best-performing hybrid functionals across general main group chemistry, at the cost of semi-local DFT. As the training dataset continues to expand, Skala is poised to further enhance the predictive power of first-principles simulations.
Two for One: Diffusion Models and Force Fields for Coarse-Grained Molecular Dynamics
Feb 01, 2023Coarse-grained (CG) molecular dynamics enables the study of biological processes at temporal and spatial scales that would be intractable at an atomistic resolution. However, accurately learning a CG force field remains a challenge. In this work, we leverage connections between score-based generative models, force fields and molecular dynamics to learn a CG force field without requiring any force inputs during training. Specifically, we train a diffusion generative model on protein structures from molecular dynamics simulations, and we show that its score function approximates a force field that can directly be used to simulate CG molecular dynamics. While having a vastly simplified training setup compared to previous work, we demonstrate that our approach leads to improved performance across several small- to medium-sized protein simulations, reproducing the CG equilibrium distribution, and preserving dynamics of all-atom simulations such as protein folding events.
Protein structure generation via folding diffusion
Sep 30, 2022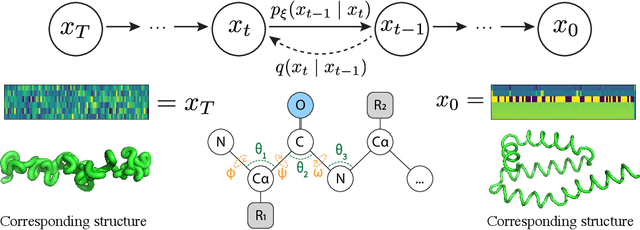

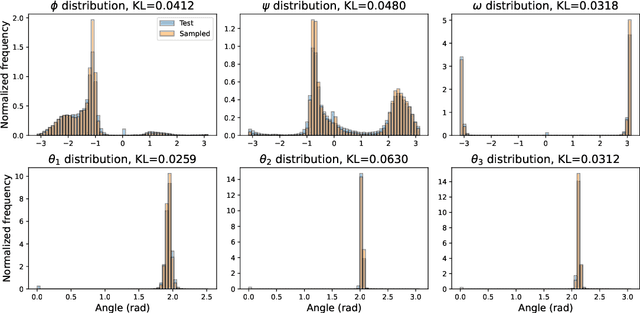
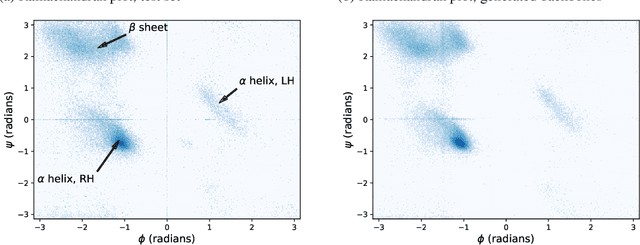
The ability to computationally generate novel yet physically foldable protein structures could lead to new biological discoveries and new treatments targeting yet incurable diseases. Despite recent advances in protein structure prediction, directly generating diverse, novel protein structures from neural networks remains difficult. In this work, we present a new diffusion-based generative model that designs protein backbone structures via a procedure that mirrors the native folding process. We describe protein backbone structure as a series of consecutive angles capturing the relative orientation of the constituent amino acid residues, and generate new structures by denoising from a random, unfolded state towards a stable folded structure. Not only does this mirror how proteins biologically twist into energetically favorable conformations, the inherent shift and rotational invariance of this representation crucially alleviates the need for complex equivariant networks. We train a denoising diffusion probabilistic model with a simple transformer backbone and demonstrate that our resulting model unconditionally generates highly realistic protein structures with complexity and structural patterns akin to those of naturally-occurring proteins. As a useful resource, we release the first open-source codebase and trained models for protein structure diffusion.
Clifford Neural Layers for PDE Modeling
Sep 08, 2022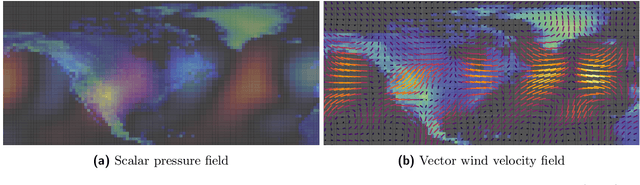
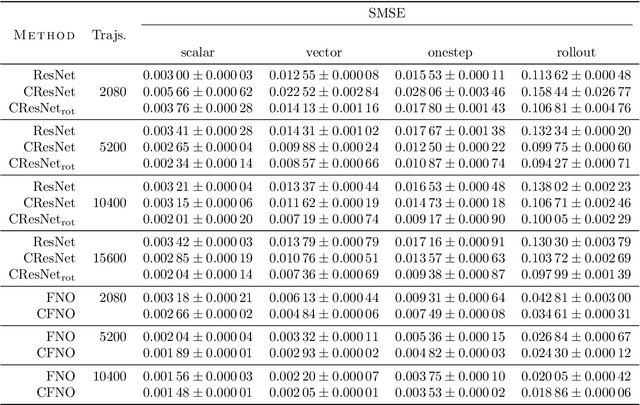
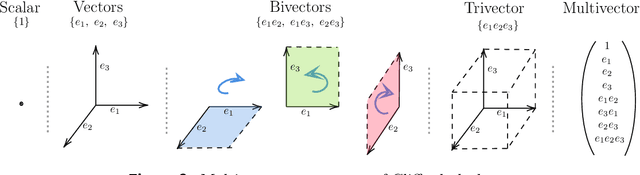
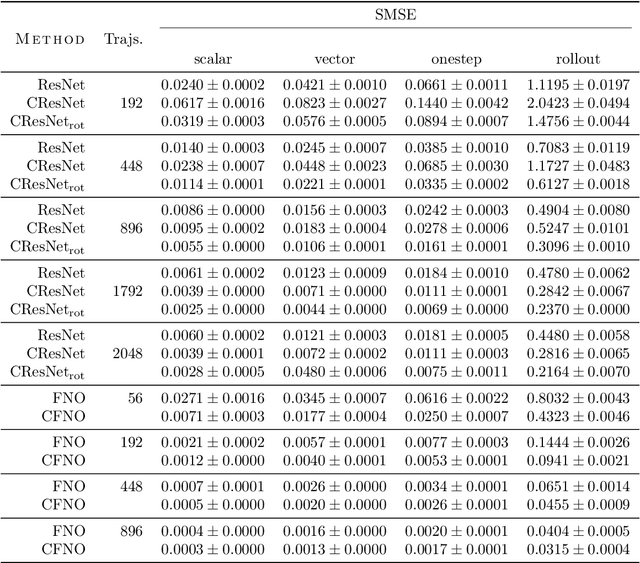
Partial differential equations (PDEs) see widespread use in sciences and engineering to describe simulation of physical processes as scalar and vector fields interacting and coevolving over time. Due to the computationally expensive nature of their standard solution methods, neural PDE surrogates have become an active research topic to accelerate these simulations. However, current methods do not explicitly take into account the relationship between different fields and their internal components, which are often correlated. Viewing the time evolution of such correlated fields through the lens of multivector fields allows us to overcome these limitations. Multivector fields consist of scalar, vector, as well as higher-order components, such as bivectors and trivectors. Their algebraic properties, such as multiplication, addition and other arithmetic operations can be described by Clifford algebras. To our knowledge, this paper presents the first usage of such multivector representations together with Clifford convolutions and Clifford Fourier transforms in the context of deep learning. The resulting Clifford neural layers are universally applicable and will find direct use in the areas of fluid dynamics, weather forecasting, and the modeling of physical systems in general. We empirically evaluate the benefit of Clifford neural layers by replacing convolution and Fourier operations in common neural PDE surrogates by their Clifford counterparts on two-dimensional Navier-Stokes and weather modeling tasks, as well as three-dimensional Maxwell equations. Clifford neural layers consistently improve generalization capabilities of the tested neural PDE surrogates.
Autoregressive Diffusion Models
Oct 05, 2021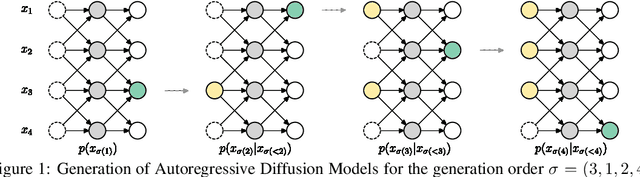

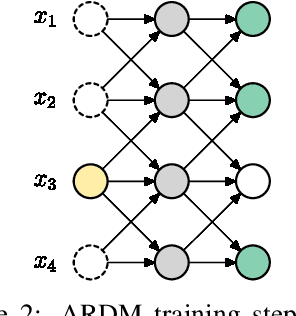

We introduce Autoregressive Diffusion Models (ARDMs), a model class encompassing and generalizing order-agnostic autoregressive models (Uria et al., 2014) and absorbing discrete diffusion (Austin et al., 2021), which we show are special cases of ARDMs under mild assumptions. ARDMs are simple to implement and easy to train. Unlike standard ARMs, they do not require causal masking of model representations, and can be trained using an efficient objective similar to modern probabilistic diffusion models that scales favourably to highly-dimensional data. At test time, ARDMs support parallel generation which can be adapted to fit any given generation budget. We find that ARDMs require significantly fewer steps than discrete diffusion models to attain the same performance. Finally, we apply ARDMs to lossless compression, and show that they are uniquely suited to this task. Contrary to existing approaches based on bits-back coding, ARDMs obtain compelling results not only on complete datasets, but also on compressing single data points. Moreover, this can be done using a modest number of network calls for (de)compression due to the model's adaptable parallel generation.
Beyond In-Place Corruption: Insertion and Deletion In Denoising Probabilistic Models
Jul 16, 2021
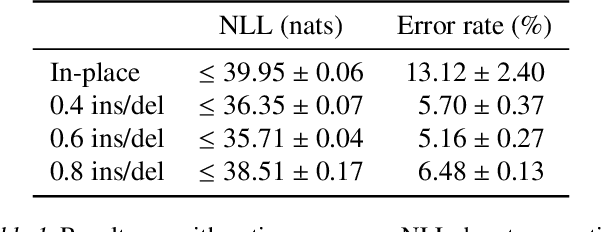
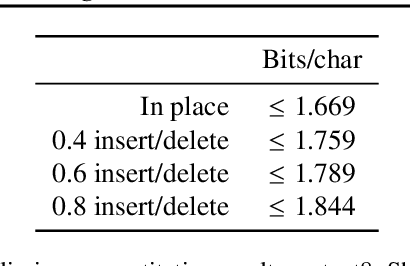
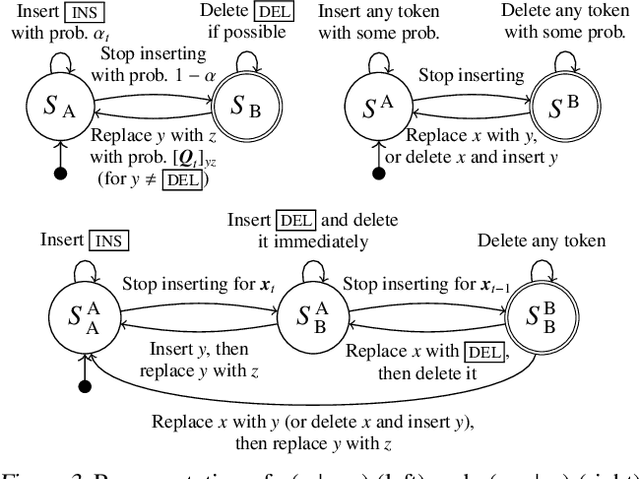
Denoising diffusion probabilistic models (DDPMs) have shown impressive results on sequence generation by iteratively corrupting each example and then learning to map corrupted versions back to the original. However, previous work has largely focused on in-place corruption, adding noise to each pixel or token individually while keeping their locations the same. In this work, we consider a broader class of corruption processes and denoising models over sequence data that can insert and delete elements, while still being efficient to train and sample from. We demonstrate that these models outperform standard in-place models on an arithmetic sequence task, and that when trained on the text8 dataset they can be used to fix spelling errors without any fine-tuning.
Structured Denoising Diffusion Models in Discrete State-Spaces
Jul 13, 2021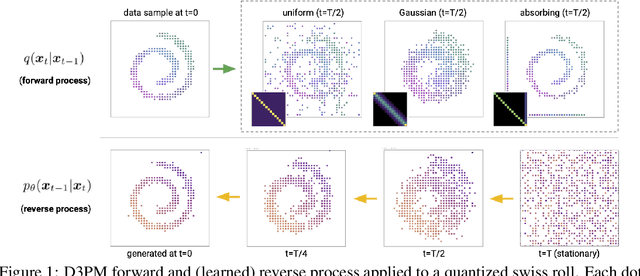
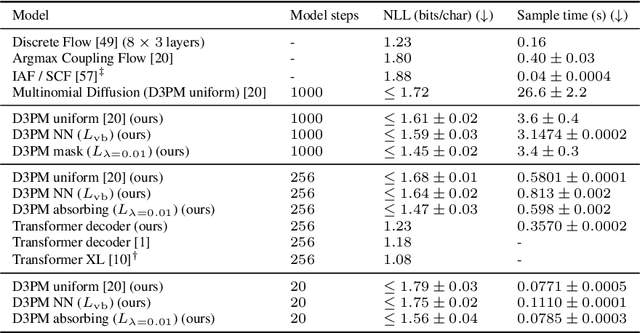

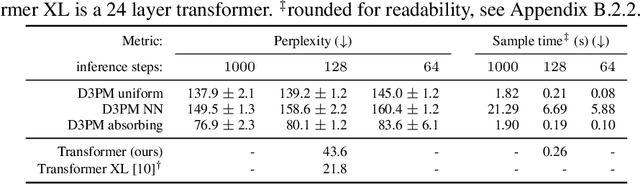
Denoising diffusion probabilistic models (DDPMs) (Ho et al. 2020) have shown impressive results on image and waveform generation in continuous state spaces. Here, we introduce Discrete Denoising Diffusion Probabilistic Models (D3PMs), diffusion-like generative models for discrete data that generalize the multinomial diffusion model of Hoogeboom et al. 2021, by going beyond corruption processes with uniform transition probabilities. This includes corruption with transition matrices that mimic Gaussian kernels in continuous space, matrices based on nearest neighbors in embedding space, and matrices that introduce absorbing states. The third allows us to draw a connection between diffusion models and autoregressive and mask-based generative models. We show that the choice of transition matrix is an important design decision that leads to improved results in image and text domains. We also introduce a new loss function that combines the variational lower bound with an auxiliary cross entropy loss. For text, this model class achieves strong results on character-level text generation while scaling to large vocabularies on LM1B. On the image dataset CIFAR-10, our models approach the sample quality and exceed the log-likelihood of the continuous-space DDPM model.
Gradual Domain Adaptation in the Wild:When Intermediate Distributions are Absent
Jun 10, 2021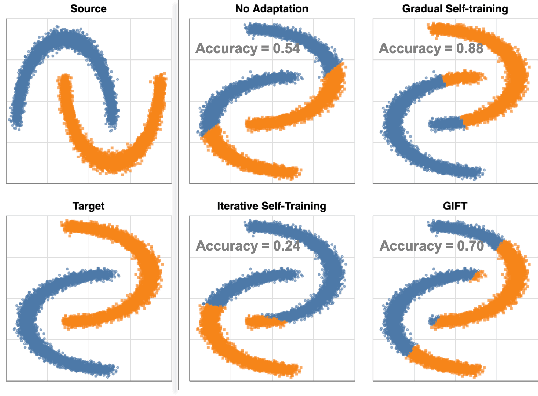
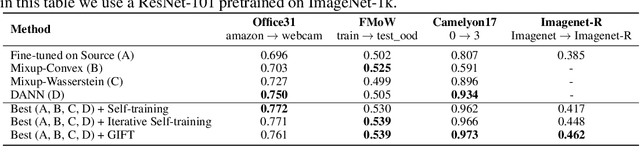

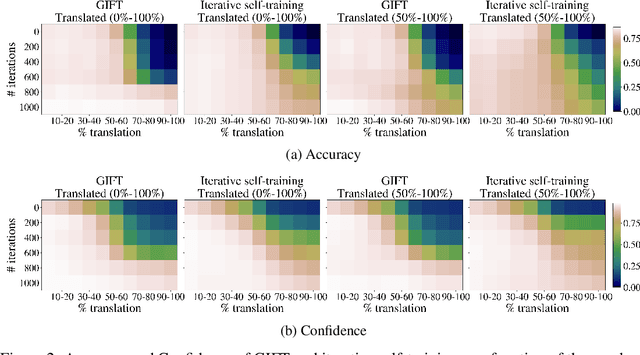
We focus on the problem of domain adaptation when the goal is shifting the model towards the target distribution, rather than learning domain invariant representations. It has been shown that under the following two assumptions: (a) access to samples from intermediate distributions, and (b) samples being annotated with the amount of change from the source distribution, self-training can be successfully applied on gradually shifted samples to adapt the model toward the target distribution. We hypothesize having (a) is enough to enable iterative self-training to slowly adapt the model to the target distribution, by making use of an implicit curriculum. In the case where (a) does not hold, we observe that iterative self-training falls short. We propose GIFT, a method that creates virtual samples from intermediate distributions by interpolating representations of examples from source and target domains. We evaluate an iterative-self-training method on datasets with natural distribution shifts, and show that when applied on top of other domain adaptation methods, it improves the performance of the model on the target dataset. We run an analysis on a synthetic dataset to show that in the presence of (a) iterative-self-training naturally forms a curriculum of samples. Furthermore, we show that when (a) does not hold, GIFT performs better than iterative self-training.
A Spectral Energy Distance for Parallel Speech Synthesis
Aug 03, 2020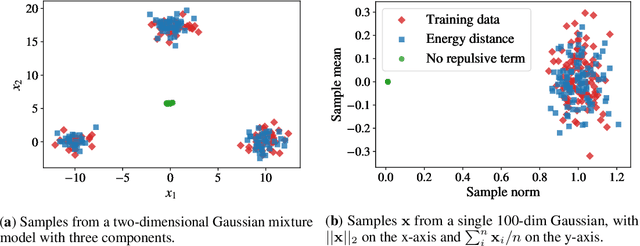
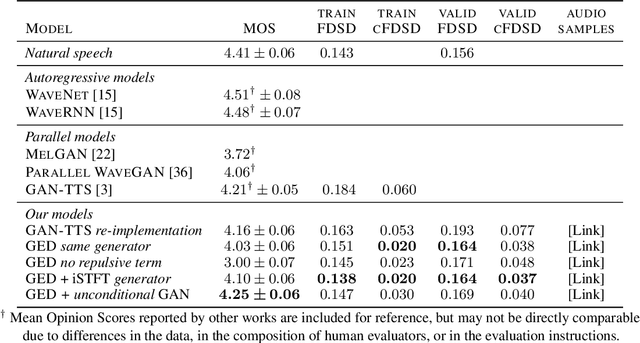
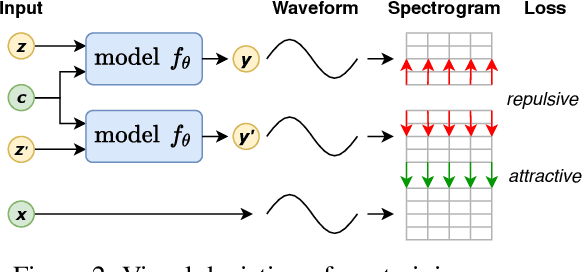
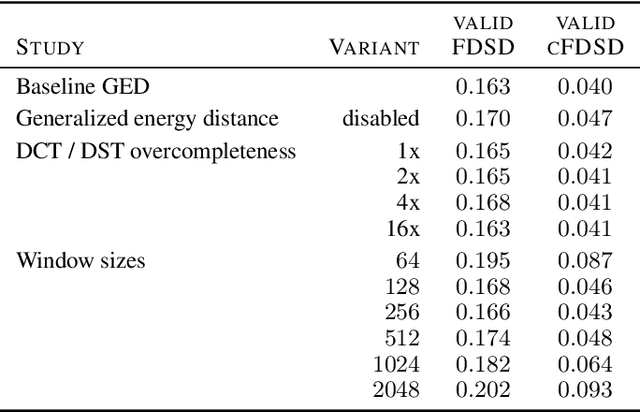
Speech synthesis is an important practical generative modeling problem that has seen great progress over the last few years, with likelihood-based autoregressive neural models now outperforming traditional concatenative systems. A downside of such autoregressive models is that they require executing tens of thousands of sequential operations per second of generated audio, making them ill-suited for deployment on specialized deep learning hardware. Here, we propose a new learning method that allows us to train highly parallel models of speech, without requiring access to an analytical likelihood function. Our approach is based on a generalized energy distance between the distributions of the generated and real audio. This spectral energy distance is a proper scoring rule with respect to the distribution over magnitude-spectrograms of the generated waveform audio and offers statistical consistency guarantees. The distance can be calculated from minibatches without bias, and does not involve adversarial learning, yielding a stable and consistent method for training implicit generative models. Empirically, we achieve state-of-the-art generation quality among implicit generative models, as judged by the recently-proposed cFDSD metric. When combining our method with adversarial techniques, we also improve upon the recently-proposed GAN-TTS model in terms of Mean Opinion Score as judged by trained human evaluators.
IDF++: Analyzing and Improving Integer Discrete Flows for Lossless Compression
Jun 22, 2020
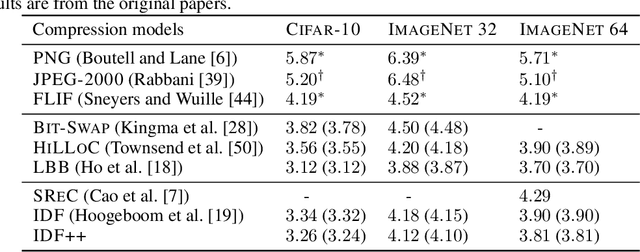


In this paper we analyse and improve integer discrete flows for lossless compression. Integer discrete flows are a recently proposed class of models that learn invertible transformations for integer-valued random variables. Due to its discrete nature, they can be combined in a straightforward manner with entropy coding schemes for lossless compression without the need for bits-back coding. We discuss the potential difference in flexibility between invertible flows for discrete random variables and flows for continuous random variables and show that (integer) discrete flows are more flexible than previously claimed. We furthermore investigate the influence of quantization operators on optimization and gradient bias in integer discrete flows. Finally, we introduce modifications to the architecture to improve the performance of this model class for lossless compression.