 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIDF++: Analyzing and Improving Integer Discrete Flows for Lossless Compression
Jun 22, 2020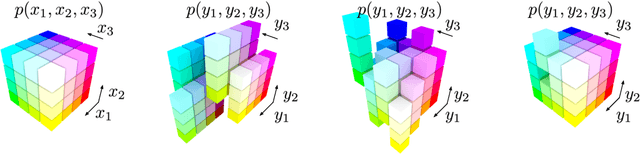
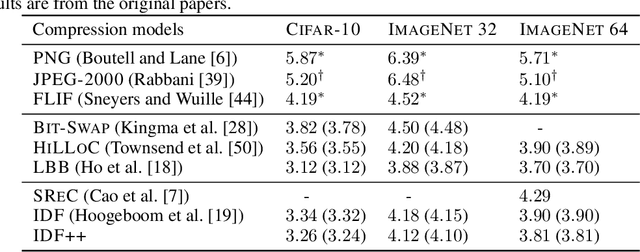


In this paper we analyse and improve integer discrete flows for lossless compression. Integer discrete flows are a recently proposed class of models that learn invertible transformations for integer-valued random variables. Due to its discrete nature, they can be combined in a straightforward manner with entropy coding schemes for lossless compression without the need for bits-back coding. We discuss the potential difference in flexibility between invertible flows for discrete random variables and flows for continuous random variables and show that (integer) discrete flows are more flexible than previously claimed. We furthermore investigate the influence of quantization operators on optimization and gradient bias in integer discrete flows. Finally, we introduce modifications to the architecture to improve the performance of this model class for lossless compression.
MetNet: A Neural Weather Model for Precipitation Forecasting
Mar 30, 2020Weather forecasting is a long standing scientific challenge with direct social and economic impact. The task is suitable for deep neural networks due to vast amounts of continuously collected data and a rich spatial and temporal structure that presents long range dependencies. We introduce MetNet, a neural network that forecasts precipitation up to 8 hours into the future at the high spatial resolution of 1 km$^2$ and at the temporal resolution of 2 minutes with a latency in the order of seconds. MetNet takes as input radar and satellite data and forecast lead time and produces a probabilistic precipitation map. The architecture uses axial self-attention to aggregate the global context from a large input patch corresponding to a million square kilometers. We evaluate the performance of MetNet at various precipitation thresholds and find that MetNet outperforms Numerical Weather Prediction at forecasts of up to 7 to 8 hours on the scale of the continental United States.
Amortised MAP Inference for Image Super-resolution
Feb 21, 2017



Image super-resolution (SR) is an underdetermined inverse problem, where a large number of plausible high-resolution images can explain the same downsampled image. Most current single image SR methods use empirical risk minimisation, often with a pixel-wise mean squared error (MSE) loss. However, the outputs from such methods tend to be blurry, over-smoothed and generally appear implausible. A more desirable approach would employ Maximum a Posteriori (MAP) inference, preferring solutions that always have a high probability under the image prior, and thus appear more plausible. Direct MAP estimation for SR is non-trivial, as it requires us to build a model for the image prior from samples. Furthermore, MAP inference is often performed via optimisation-based iterative algorithms which don't compare well with the efficiency of neural-network-based alternatives. Here we introduce new methods for amortised MAP inference whereby we calculate the MAP estimate directly using a convolutional neural network. We first introduce a novel neural network architecture that performs a projection to the affine subspace of valid SR solutions ensuring that the high resolution output of the network is always consistent with the low resolution input. We show that, using this architecture, the amortised MAP inference problem reduces to minimising the cross-entropy between two distributions, similar to training generative models. We propose three methods to solve this optimisation problem: (1) Generative Adversarial Networks (GAN) (2) denoiser-guided SR which backpropagates gradient-estimates from denoising to train the network, and (3) a baseline method using a maximum-likelihood-trained image prior. Our experiments show that the GAN based approach performs best on real image data. Lastly, we establish a connection between GANs and amortised variational inference as in e.g. variational autoencoders.
Neural Machine Translation with Characters and Hierarchical Encoding
Oct 20, 2016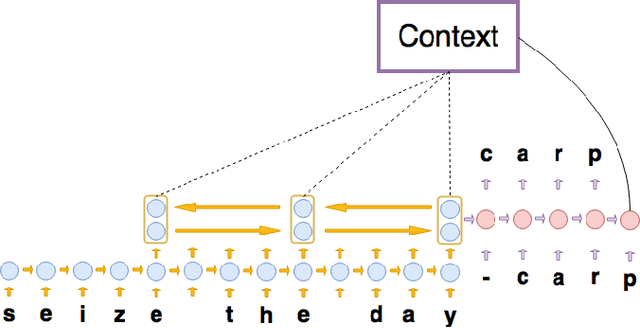
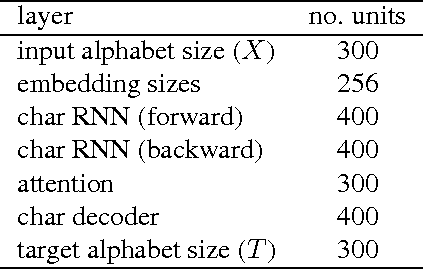
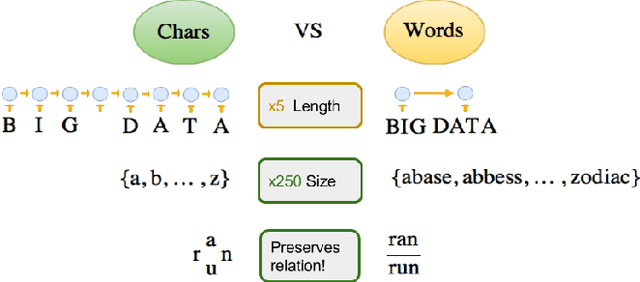
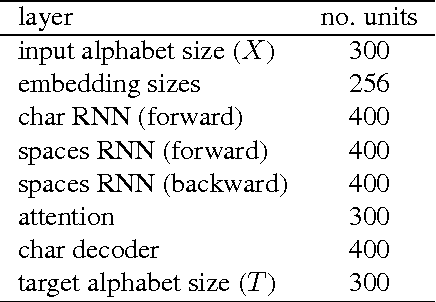
Most existing Neural Machine Translation models use groups of characters or whole words as their unit of input and output. We propose a model with a hierarchical char2word encoder, that takes individual characters both as input and output. We first argue that this hierarchical representation of the character encoder reduces computational complexity, and show that it improves translation performance. Secondly, by qualitatively studying attention plots from the decoder we find that the model learns to compress common words into a single embedding whereas rare words, such as names and places, are represented character by character.
Auxiliary Deep Generative Models
Jun 16, 2016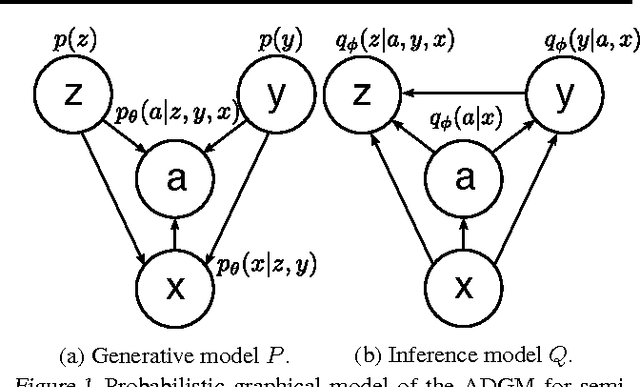
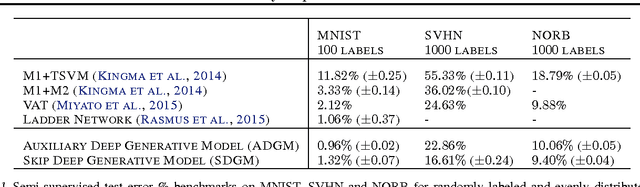
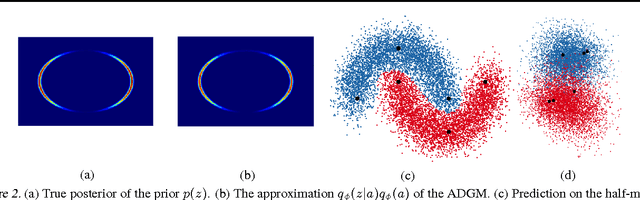

Deep generative models parameterized by neural networks have recently achieved state-of-the-art performance in unsupervised and semi-supervised learning. We extend deep generative models with auxiliary variables which improves the variational approximation. The auxiliary variables leave the generative model unchanged but make the variational distribution more expressive. Inspired by the structure of the auxiliary variable we also propose a model with two stochastic layers and skip connections. Our findings suggest that more expressive and properly specified deep generative models converge faster with better results. We show state-of-the-art performance within semi-supervised learning on MNIST, SVHN and NORB datasets.
Ladder Variational Autoencoders
May 27, 2016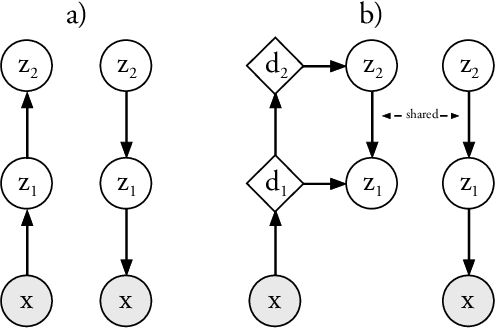

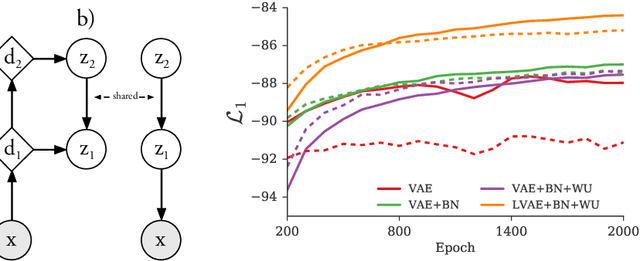
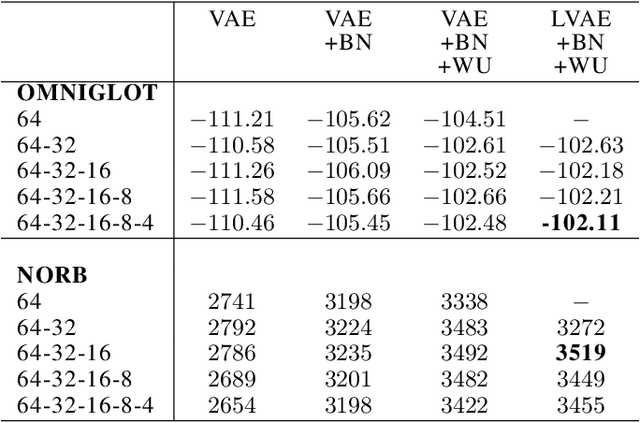
Variational Autoencoders are powerful models for unsupervised learning. However deep models with several layers of dependent stochastic variables are difficult to train which limits the improvements obtained using these highly expressive models. We propose a new inference model, the Ladder Variational Autoencoder, that recursively corrects the generative distribution by a data dependent approximate likelihood in a process resembling the recently proposed Ladder Network. We show that this model provides state of the art predictive log-likelihood and tighter log-likelihood lower bound compared to the purely bottom-up inference in layered Variational Autoencoders and other generative models. We provide a detailed analysis of the learned hierarchical latent representation and show that our new inference model is qualitatively different and utilizes a deeper more distributed hierarchy of latent variables. Finally, we observe that batch normalization and deterministic warm-up (gradually turning on the KL-term) are crucial for training variational models with many stochastic layers.
Recurrent Spatial Transformer Networks
Sep 17, 2015
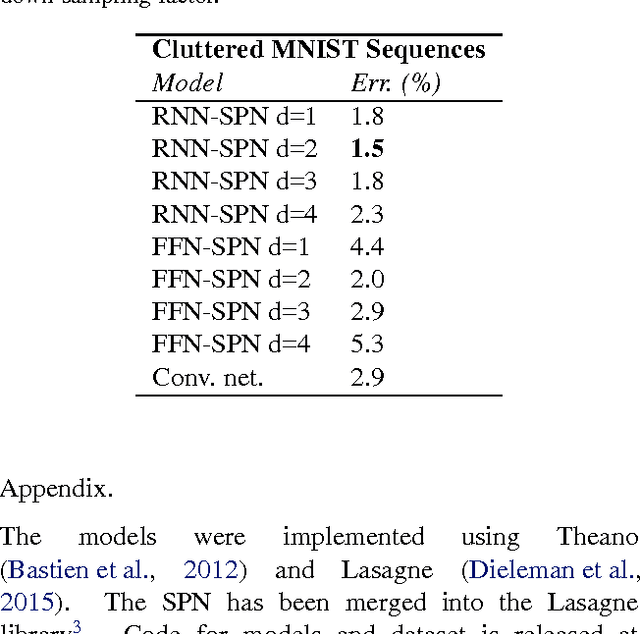
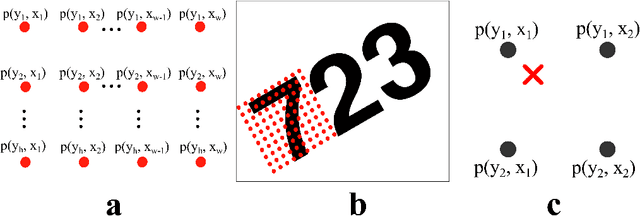

We integrate the recently proposed spatial transformer network (SPN) [Jaderberg et. al 2015] into a recurrent neural network (RNN) to form an RNN-SPN model. We use the RNN-SPN to classify digits in cluttered MNIST sequences. The proposed model achieves a single digit error of 1.5% compared to 2.9% for a convolutional networks and 2.0% for convolutional networks with SPN layers. The SPN outputs a zoomed, rotated and skewed version of the input image. We investigate different down-sampling factors (ratio of pixel in input and output) for the SPN and show that the RNN-SPN model is able to down-sample the input images without deteriorating performance. The down-sampling in RNN-SPN can be thought of as adaptive down-sampling that minimizes the information loss in the regions of interest. We attribute the superior performance of the RNN-SPN to the fact that it can attend to a sequence of regions of interest.
Convolutional LSTM Networks for Subcellular Localization of Proteins
Mar 06, 2015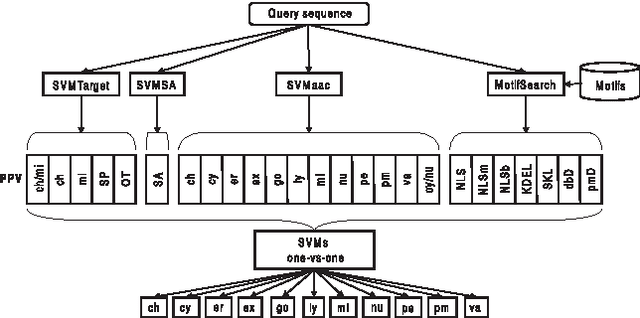
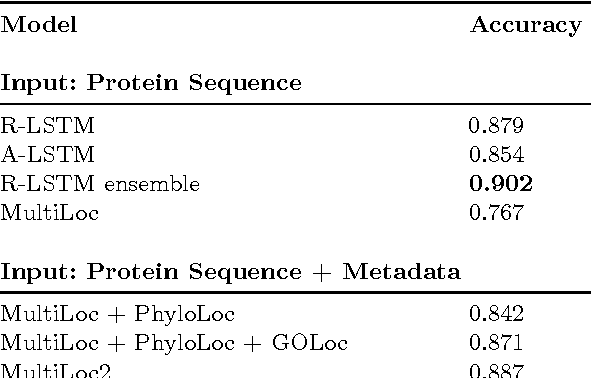

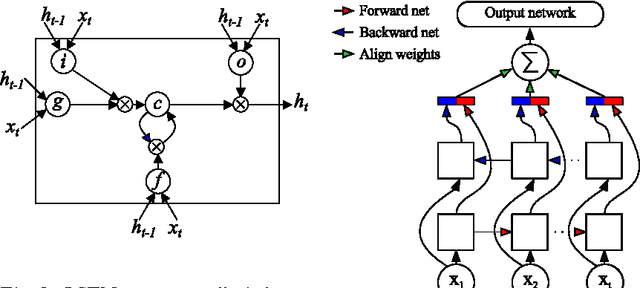
Machine learning is widely used to analyze biological sequence data. Non-sequential models such as SVMs or feed-forward neural networks are often used although they have no natural way of handling sequences of varying length. Recurrent neural networks such as the long short term memory (LSTM) model on the other hand are designed to handle sequences. In this study we demonstrate that LSTM networks predict the subcellular location of proteins given only the protein sequence with high accuracy (0.902) outperforming current state of the art algorithms. We further improve the performance by introducing convolutional filters and experiment with an attention mechanism which lets the LSTM focus on specific parts of the protein. Lastly we introduce new visualizations of both the convolutional filters and the attention mechanisms and show how they can be used to extract biological relevant knowledge from the LSTM networks.