 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Behavior Cloning Improves Causal Reasoning: An Open Model for Real-Time Video Game Playing
Jan 08, 2026Behavior cloning is enjoying a resurgence in popularity as scaling both model and data sizes proves to provide a strong starting point for many tasks of interest. In this work, we introduce an open recipe for training a video game playing foundation model designed for inference in realtime on a consumer GPU. We release all data (8300+ hours of high quality human gameplay), training and inference code, and pretrained checkpoints under an open license. We show that our best model is capable of playing a variety of 3D video games at a level competitive with human play. We use this recipe to systematically examine the scaling laws of behavior cloning to understand how the model's performance and causal reasoning varies with model and data scale. We first show in a simple toy problem that, for some types of causal reasoning, increasing both the amount of training data and the depth of the network results in the model learning a more causal policy. We then systematically study how causality varies with the number of parameters (and depth) and training steps in scaled models of up to 1.2 billion parameters, and we find similar scaling results to what we observe in the toy problem.
Pixels to Play: A Foundation Model for 3D Gameplay
Aug 19, 2025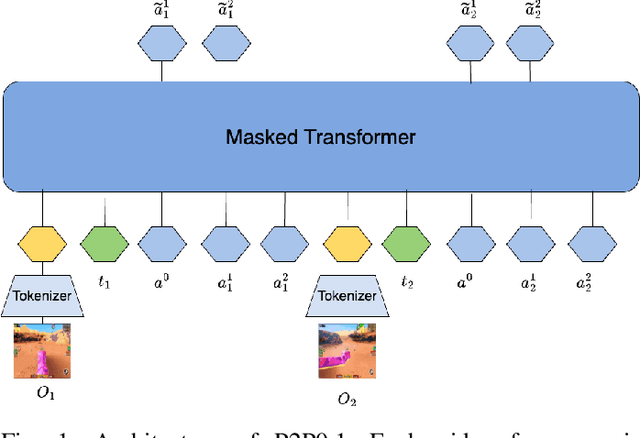
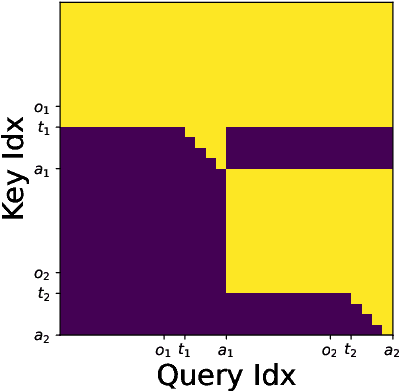

We introduce Pixels2Play-0.1 (P2P0.1), a foundation model that learns to play a wide range of 3D video games with recognizable human-like behavior. Motivated by emerging consumer and developer use cases - AI teammates, controllable NPCs, personalized live-streamers, assistive testers - we argue that an agent must rely on the same pixel stream available to players and generalize to new titles with minimal game-specific engineering. P2P0.1 is trained end-to-end with behavior cloning: labeled demonstrations collected from instrumented human game-play are complemented by unlabeled public videos, to which we impute actions via an inverse-dynamics model. A decoder-only transformer with auto-regressive action output handles the large action space while remaining latency-friendly on a single consumer GPU. We report qualitative results showing competent play across simple Roblox and classic MS-DOS titles, ablations on unlabeled data, and outline the scaling and evaluation steps required to reach expert-level, text-conditioned control.
Multi-Objective Recommendation via Multivariate Policy Learning
May 03, 2024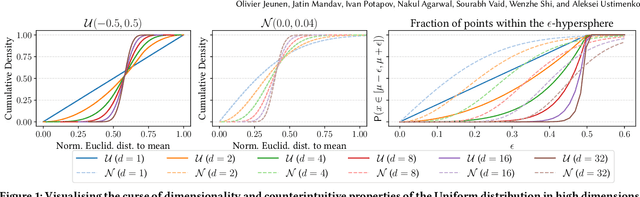

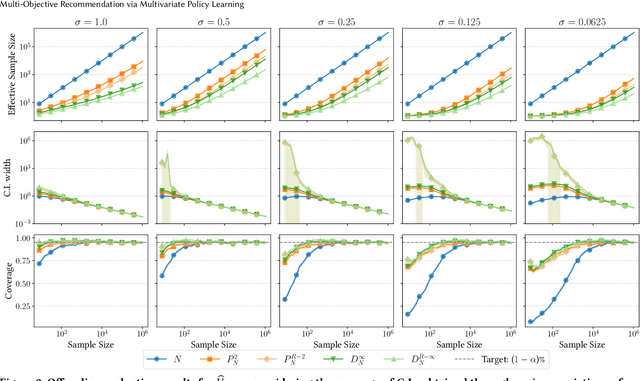
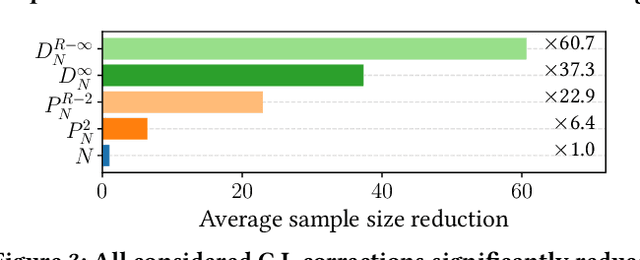
Real-world recommender systems often need to balance multiple objectives when deciding which recommendations to present to users. These include behavioural signals (e.g. clicks, shares, dwell time), as well as broader objectives (e.g. diversity, fairness). Scalarisation methods are commonly used to handle this balancing task, where a weighted average of per-objective reward signals determines the final score used for ranking. Naturally, how these weights are computed exactly, is key to success for any online platform. We frame this as a decision-making task, where the scalarisation weights are actions taken to maximise an overall North Star reward (e.g. long-term user retention or growth). We extend existing policy learning methods to the continuous multivariate action domain, proposing to maximise a pessimistic lower bound on the North Star reward that the learnt policy will yield. Typical lower bounds based on normal approximations suffer from insufficient coverage, and we propose an efficient and effective policy-dependent correction for this. We provide guidance to design stochastic data collection policies, as well as highly sensitive reward signals. Empirical observations from simulations, offline and online experiments highlight the efficacy of our deployed approach.
On Gradient Boosted Decision Trees and Neural Rankers: A Case-Study on Short-Video Recommendations at ShareChat
Dec 04, 2023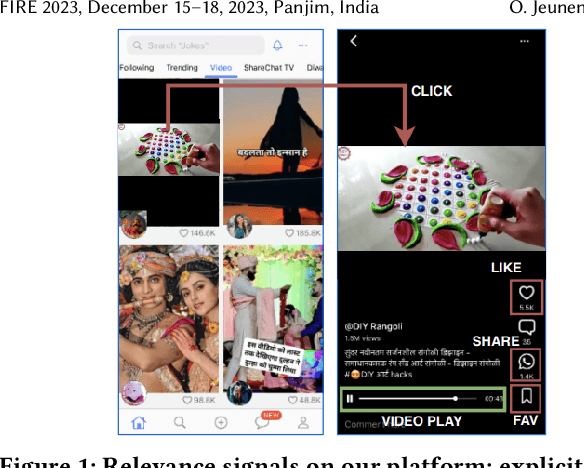
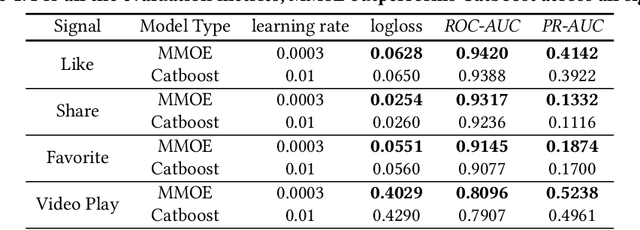
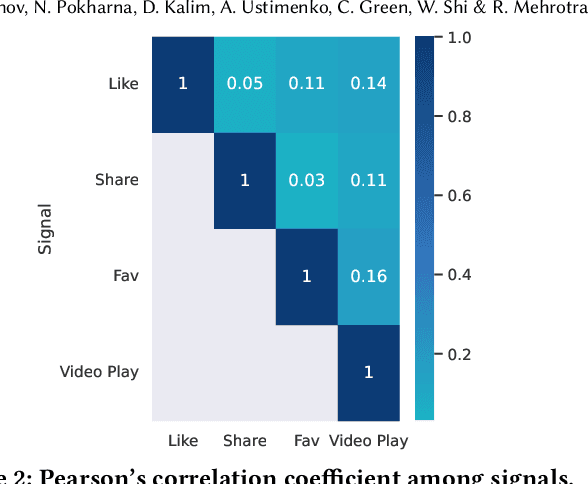
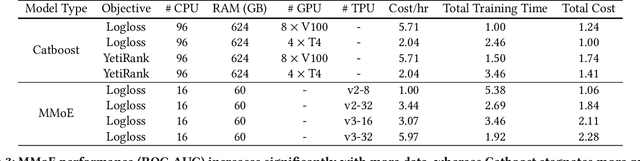
Practitioners who wish to build real-world applications that rely on ranking models, need to decide which modelling paradigm to follow. This is not an easy choice to make, as the research literature on this topic has been shifting in recent years. In particular, whilst Gradient Boosted Decision Trees (GBDTs) have reigned supreme for more than a decade, the flexibility of neural networks has allowed them to catch up, and recent works report accuracy metrics that are on par. Nevertheless, practical systems require considerations beyond mere accuracy metrics to decide on a modelling approach. This work describes our experiences in balancing some of the trade-offs that arise, presenting a case study on a short-video recommendation application. We highlight (1) neural networks' ability to handle large training data size, user- and item-embeddings allows for more accurate models than GBDTs in this setting, and (2) because GBDTs are less reliant on specialised hardware, they can provide an equally accurate model at a lower cost. We believe these findings are of relevance to researchers in both academia and industry, and hope they can inspire practitioners who need to make similar modelling choices in the future.
Should I send this notification? Optimizing push notifications decision making by modeling the future
Feb 17, 2022Most recommender systems are myopic, that is they optimize based on the immediate response of the user. This may be misaligned with the true objective, such as creating long term user satisfaction. In this work we focus on mobile push notifications, where the long term effects of recommender system decisions can be particularly strong. For example, sending too many or irrelevant notifications may annoy a user and cause them to disable notifications. However, a myopic system will always choose to send a notification since negative effects occur in the future. This is typically mitigated using heuristics. However, heuristics can be hard to reason about or improve, require retuning each time the system is changed, and may be suboptimal. To counter these drawbacks, there is significant interest in recommender systems that optimize directly for long-term value (LTV). Here, we describe a method for maximising LTV by using model-based reinforcement learning (RL) to make decisions about whether to send push notifications. We model the effects of sending a notification on the user's future behavior. Much of the prior work applying RL to maximise LTV in recommender systems has focused on session-based optimization, while the time horizon for notification decision making in this work extends over several days. We test this approach in an A/B test on a major social network. We show that by optimizing decisions about push notifications we are able to send less notifications and obtain a higher open rate than the baseline system, while generating the same level of user engagement on the platform as the existing, heuristic-based, system.
Learning to Rank For Push Notifications Using Pairwise Expected Regret
Jan 19, 2022

Listwise ranking losses have been widely studied in recommender systems. However, new paradigms of content consumption present new challenges for ranking methods. In this work we contribute an analysis of learning to rank for personalized mobile push notifications and discuss the unique challenges this presents compared to traditional ranking problems. To address these challenges, we introduce a novel ranking loss based on weighting the pairwise loss between candidates by the expected regret incurred for misordering the pair. We demonstrate that the proposed method can outperform prior methods both in a simulated environment and in a production experiment on a major social network.
Deep Bayesian Bandits: Exploring in Online Personalized Recommendations
Aug 03, 2020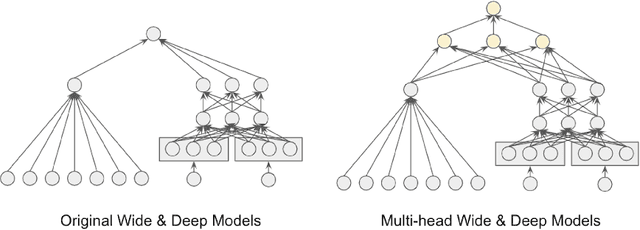
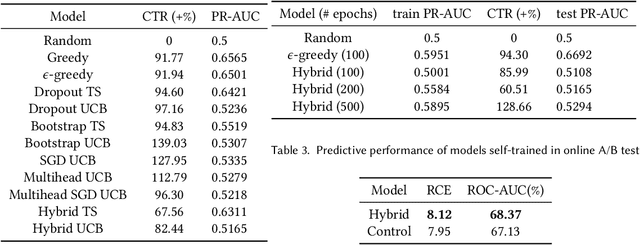
Recommender systems trained in a continuous learning fashion are plagued by the feedback loop problem, also known as algorithmic bias. This causes a newly trained model to act greedily and favor items that have already been engaged by users. This behavior is particularly harmful in personalised ads recommendations, as it can also cause new campaigns to remain unexplored. Exploration aims to address this limitation by providing new information about the environment, which encompasses user preference, and can lead to higher long-term reward. In this work, we formulate a display advertising recommender as a contextual bandit and implement exploration techniques that require sampling from the posterior distribution of click-through-rates in a computationally tractable manner. Traditional large-scale deep learning models do not provide uncertainty estimates by default. We approximate these uncertainty measurements of the predictions by employing a bootstrapped model with multiple heads and dropout units. We benchmark a number of different models in an offline simulation environment using a publicly available dataset of user-ads engagements. We test our proposed deep Bayesian bandits algorithm in the offline simulation and online AB setting with large-scale production traffic, where we demonstrate a positive gain of our exploration model.
Model Size Reduction Using Frequency Based Double Hashing for Recommender Systems
Jul 28, 2020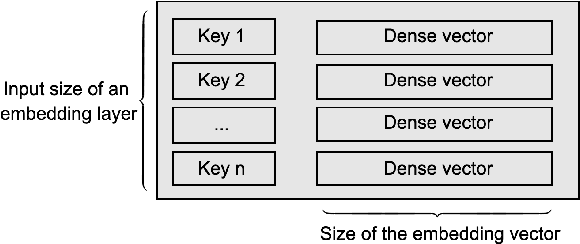
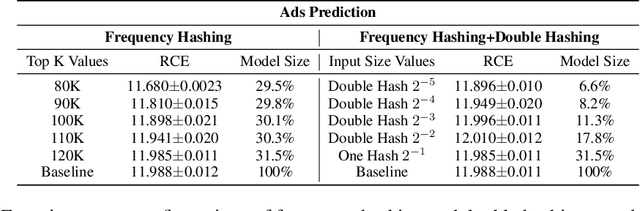
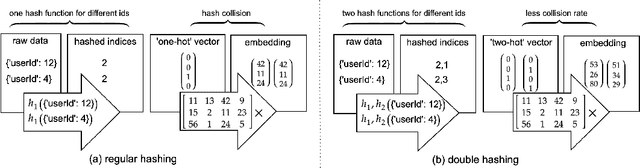
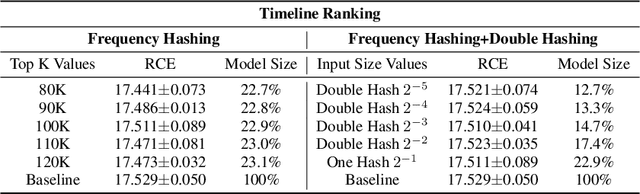
Deep Neural Networks (DNNs) with sparse input features have been widely used in recommender systems in industry. These models have large memory requirements and need a huge amount of training data. The large model size usually entails a cost, in the range of millions of dollars, for storage and communication with the inference services. In this paper, we propose a hybrid hashing method to combine frequency hashing and double hashing techniques for model size reduction, without compromising performance. We evaluate the proposed models on two product surfaces. In both cases, experiment results demonstrated that we can reduce the model size by around 90 % while keeping the performance on par with the original baselines.
Privacy-Preserving Recommender Systems Challenge on Twitter's Home Timeline
Apr 28, 2020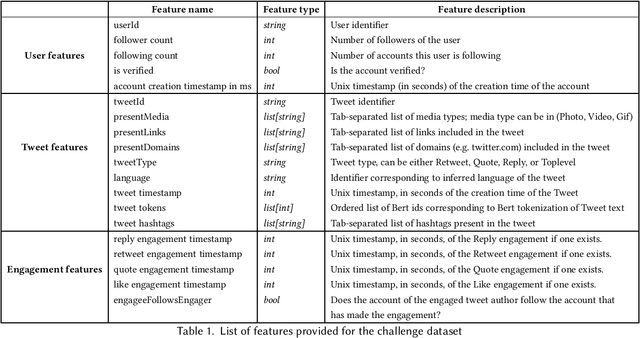
Recommender systems constitute the core engine of most social network platforms nowadays, aiming to maximize user satisfaction along with other key business objectives. Twitter is no exception. Despite the fact that Twitter data has been extensively used to understand socioeconomic and political phenomena and user behaviour, the implicit feedback provided by users on Tweets through their engagements on the Home Timeline has only been explored to a limited extent. At the same time, there is a lack of large-scale public social network datasets that would enable the scientific community to both benchmark and build more powerful and comprehensive models that tailor content to user interests. By releasing an original dataset of 160 million Tweets along with engagement information, Twitter aims to address exactly that. During this release, special attention is drawn on maintaining compliance with existing privacy laws. Apart from user privacy, this paper touches on the key challenges faced by researchers and professionals striving to predict user engagements. It further describes the key aspects of the RecSys 2020 Challenge that was organized by ACM RecSys in partnership with Twitter using this dataset.
Addressing Delayed Feedback for Continuous Training with Neural Networks in CTR prediction
Jul 15, 2019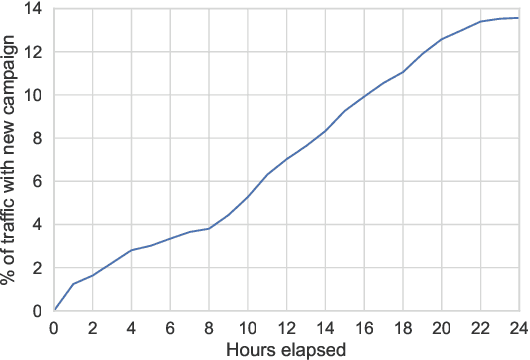
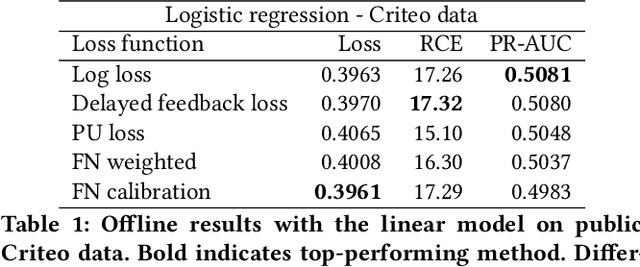
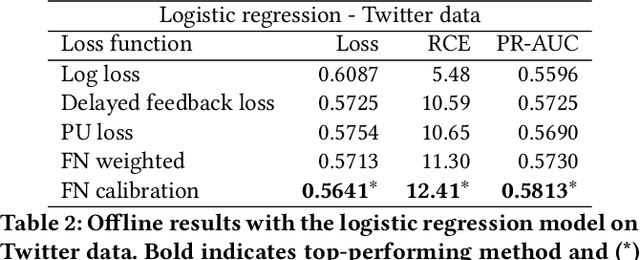
One of the challenges in display advertising is that the distribution of features and click through rate (CTR) can exhibit large shifts over time due to seasonality, changes to ad campaigns and other factors. The predominant strategy to keep up with these shifts is to train predictive models continuously, on fresh data, in order to prevent them from becoming stale. However, in many ad systems positive labels are only observed after a possibly long and random delay. These delayed labels pose a challenge to data freshness in continuous training: fresh data may not have complete label information at the time they are ingested by the training algorithm. Naive strategies which consider any data point a negative example until a positive label becomes available tend to underestimate CTR, resulting in inferior user experience and suboptimal performance for advertisers. The focus of this paper is to identify the best combination of loss functions and models that enable large-scale learning from a continuous stream of data in the presence of delayed labels. In this work, we compare 5 different loss functions, 3 of them applied to this problem for the first time. We benchmark their performance in offline settings on both public and proprietary datasets in conjunction with shallow and deep model architectures. We also discuss the engineering cost associated with implementing each loss function in a production environment. Finally, we carried out online experiments with the top performing methods, in order to validate their performance in a continuous training scheme. While training on 668 million in-house data points offline, our proposed methods outperform previous state-of-the-art by 3% relative cross entropy (RCE). During online experiments, we observed 55% gain in revenue per thousand requests (RPMq) against naive log loss.