 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasuring Disparate Outcomes of Content Recommendation Algorithms with Distributional Inequality Metrics
Feb 03, 2022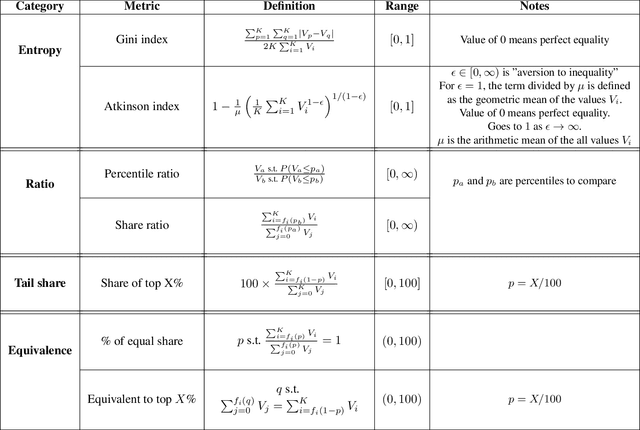
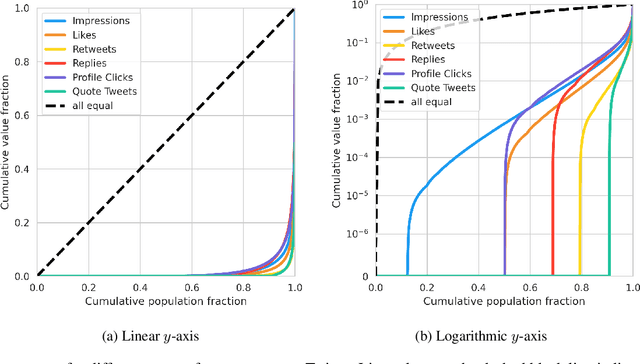
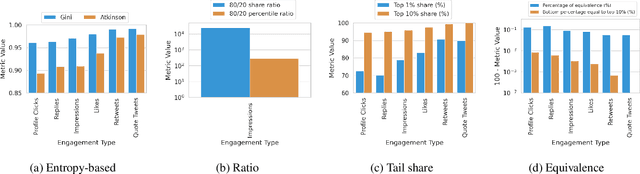
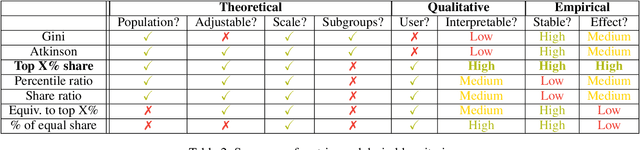
The harmful impacts of algorithmic decision systems have recently come into focus, with many examples of systems such as machine learning (ML) models amplifying existing societal biases. Most metrics attempting to quantify disparities resulting from ML algorithms focus on differences between groups, dividing users based on demographic identities and comparing model performance or overall outcomes between these groups. However, in industry settings, such information is often not available, and inferring these characteristics carries its own risks and biases. Moreover, typical metrics that focus on a single classifier's output ignore the complex network of systems that produce outcomes in real-world settings. In this paper, we evaluate a set of metrics originating from economics, distributional inequality metrics, and their ability to measure disparities in content exposure in a production recommendation system, the Twitter algorithmic timeline. We define desirable criteria for metrics to be used in an operational setting, specifically by ML practitioners. We characterize different types of engagement with content on Twitter using these metrics, and use these results to evaluate the metrics with respect to the desired criteria. We show that we can use these metrics to identify content suggestion algorithms that contribute more strongly to skewed outcomes between users. Overall, we conclude that these metrics can be useful tools for understanding disparate outcomes in online social networks.
Efficient Wasserstein Natural Gradients for Reinforcement Learning
Oct 12, 2020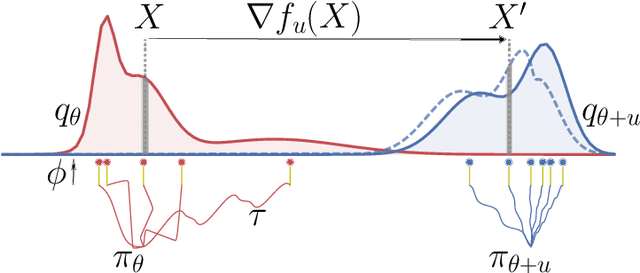
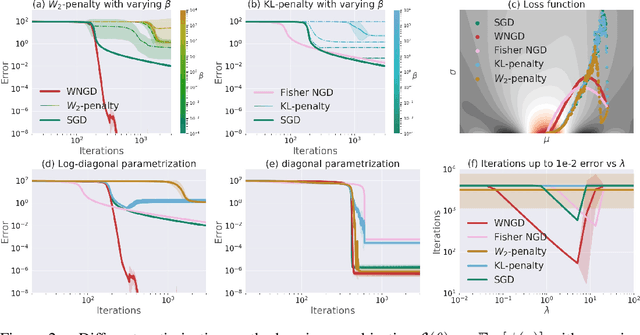
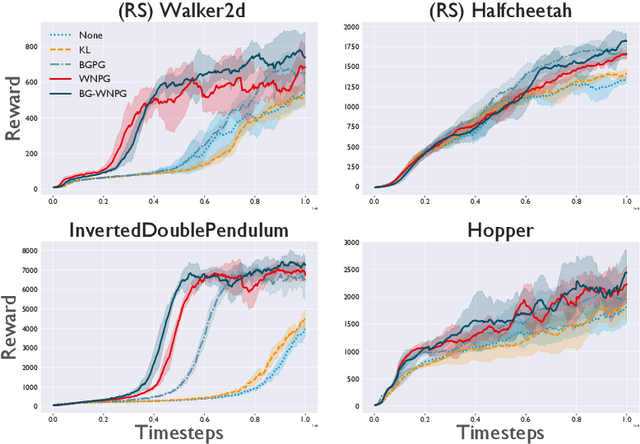
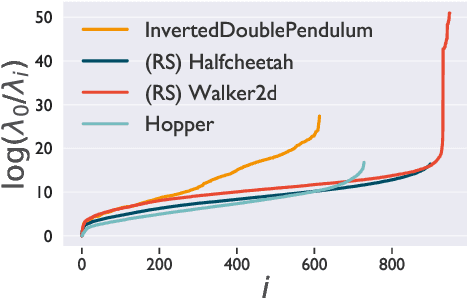
A novel optimization approach is proposed for application to policy gradient methods and evolution strategies for reinforcement learning (RL). The procedure uses a computationally efficient Wasserstein natural gradient (WNG) descent that takes advantage of the geometry induced by a Wasserstein penalty to speed optimization. This method follows the recent theme in RL of including a divergence penalty in the objective to establish a trust region. Experiments on challenging tasks demonstrate improvements in both computational cost and performance over advanced baselines.
Deep Bayesian Bandits: Exploring in Online Personalized Recommendations
Aug 03, 2020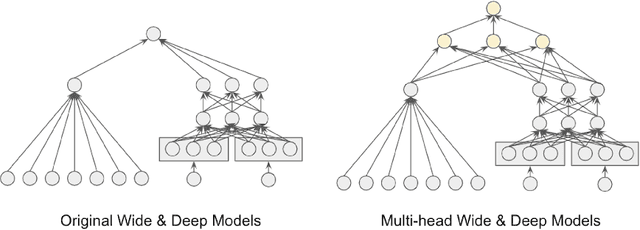
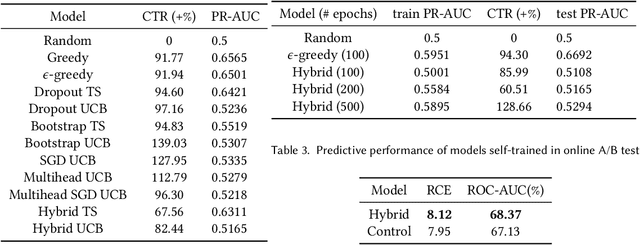
Recommender systems trained in a continuous learning fashion are plagued by the feedback loop problem, also known as algorithmic bias. This causes a newly trained model to act greedily and favor items that have already been engaged by users. This behavior is particularly harmful in personalised ads recommendations, as it can also cause new campaigns to remain unexplored. Exploration aims to address this limitation by providing new information about the environment, which encompasses user preference, and can lead to higher long-term reward. In this work, we formulate a display advertising recommender as a contextual bandit and implement exploration techniques that require sampling from the posterior distribution of click-through-rates in a computationally tractable manner. Traditional large-scale deep learning models do not provide uncertainty estimates by default. We approximate these uncertainty measurements of the predictions by employing a bootstrapped model with multiple heads and dropout units. We benchmark a number of different models in an offline simulation environment using a publicly available dataset of user-ads engagements. We test our proposed deep Bayesian bandits algorithm in the offline simulation and online AB setting with large-scale production traffic, where we demonstrate a positive gain of our exploration model.
Model Size Reduction Using Frequency Based Double Hashing for Recommender Systems
Jul 28, 2020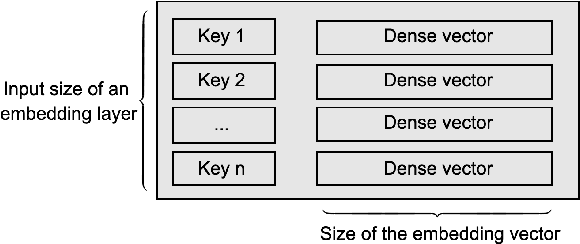
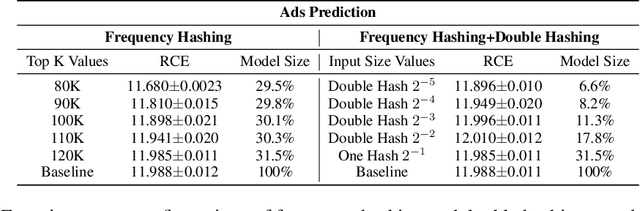
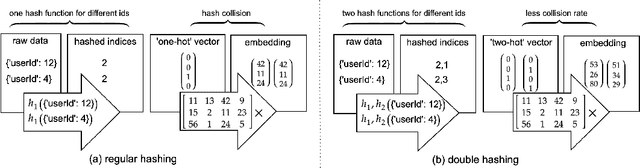
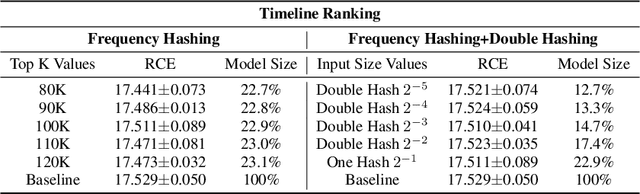
Deep Neural Networks (DNNs) with sparse input features have been widely used in recommender systems in industry. These models have large memory requirements and need a huge amount of training data. The large model size usually entails a cost, in the range of millions of dollars, for storage and communication with the inference services. In this paper, we propose a hybrid hashing method to combine frequency hashing and double hashing techniques for model size reduction, without compromising performance. We evaluate the proposed models on two product surfaces. In both cases, experiment results demonstrated that we can reduce the model size by around 90 % while keeping the performance on par with the original baselines.
Addressing Delayed Feedback for Continuous Training with Neural Networks in CTR prediction
Jul 15, 2019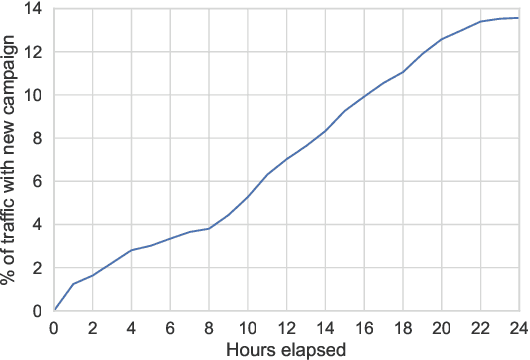
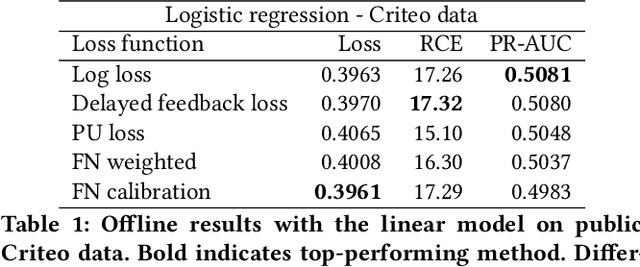
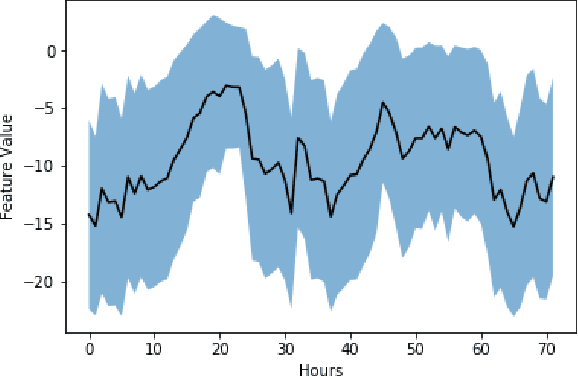
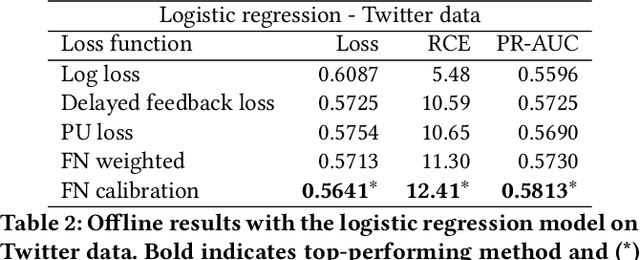
One of the challenges in display advertising is that the distribution of features and click through rate (CTR) can exhibit large shifts over time due to seasonality, changes to ad campaigns and other factors. The predominant strategy to keep up with these shifts is to train predictive models continuously, on fresh data, in order to prevent them from becoming stale. However, in many ad systems positive labels are only observed after a possibly long and random delay. These delayed labels pose a challenge to data freshness in continuous training: fresh data may not have complete label information at the time they are ingested by the training algorithm. Naive strategies which consider any data point a negative example until a positive label becomes available tend to underestimate CTR, resulting in inferior user experience and suboptimal performance for advertisers. The focus of this paper is to identify the best combination of loss functions and models that enable large-scale learning from a continuous stream of data in the presence of delayed labels. In this work, we compare 5 different loss functions, 3 of them applied to this problem for the first time. We benchmark their performance in offline settings on both public and proprietary datasets in conjunction with shallow and deep model architectures. We also discuss the engineering cost associated with implementing each loss function in a production environment. Finally, we carried out online experiments with the top performing methods, in order to validate their performance in a continuous training scheme. While training on 668 million in-house data points offline, our proposed methods outperform previous state-of-the-art by 3% relative cross entropy (RCE). During online experiments, we observed 55% gain in revenue per thousand requests (RPMq) against naive log loss.
Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network
May 25, 2017
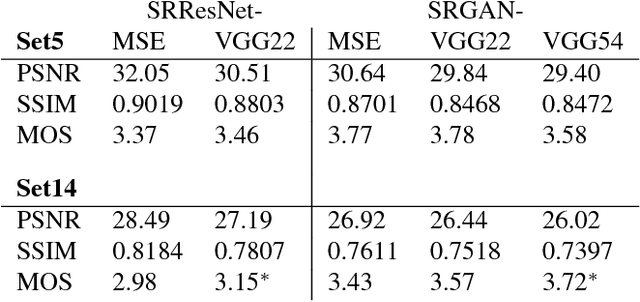

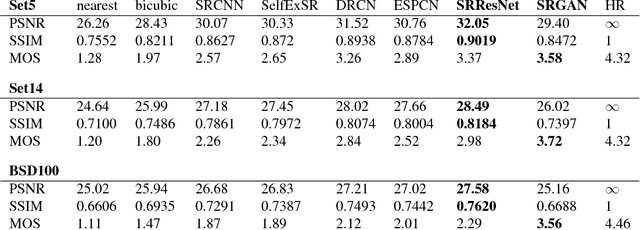
Despite the breakthroughs in accuracy and speed of single image super-resolution using faster and deeper convolutional neural networks, one central problem remains largely unsolved: how do we recover the finer texture details when we super-resolve at large upscaling factors? The behavior of optimization-based super-resolution methods is principally driven by the choice of the objective function. Recent work has largely focused on minimizing the mean squared reconstruction error. The resulting estimates have high peak signal-to-noise ratios, but they are often lacking high-frequency details and are perceptually unsatisfying in the sense that they fail to match the fidelity expected at the higher resolution. In this paper, we present SRGAN, a generative adversarial network (GAN) for image super-resolution (SR). To our knowledge, it is the first framework capable of inferring photo-realistic natural images for 4x upscaling factors. To achieve this, we propose a perceptual loss function which consists of an adversarial loss and a content loss. The adversarial loss pushes our solution to the natural image manifold using a discriminator network that is trained to differentiate between the super-resolved images and original photo-realistic images. In addition, we use a content loss motivated by perceptual similarity instead of similarity in pixel space. Our deep residual network is able to recover photo-realistic textures from heavily downsampled images on public benchmarks. An extensive mean-opinion-score (MOS) test shows hugely significant gains in perceptual quality using SRGAN. The MOS scores obtained with SRGAN are closer to those of the original high-resolution images than to those obtained with any state-of-the-art method.
Is the deconvolution layer the same as a convolutional layer?
Sep 22, 2016In this note, we want to focus on aspects related to two questions most people asked us at CVPR about the network we presented. Firstly, What is the relationship between our proposed layer and the deconvolution layer? And secondly, why are convolutions in low-resolution (LR) space a better choice? These are key questions we tried to answer in the paper, but we were not able to go into as much depth and clarity as we would have liked in the space allowance. To better answer these questions in this note, we first discuss the relationships between the deconvolution layer in the forms of the transposed convolution layer, the sub-pixel convolutional layer and our efficient sub-pixel convolutional layer. We will refer to our efficient sub-pixel convolutional layer as a convolutional layer in LR space to distinguish it from the common sub-pixel convolutional layer. We will then show that for a fixed computational budget and complexity, a network with convolutions exclusively in LR space has more representation power at the same speed than a network that first upsamples the input in high resolution space.
Optimally-Weighted Herding is Bayesian Quadrature
Jul 13, 2016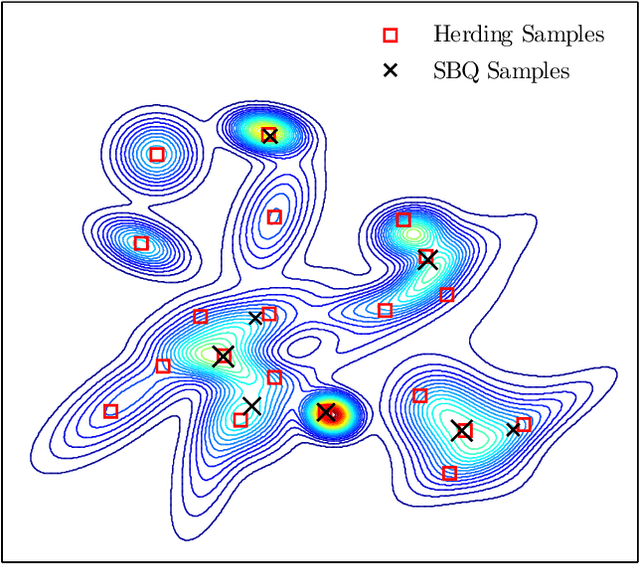

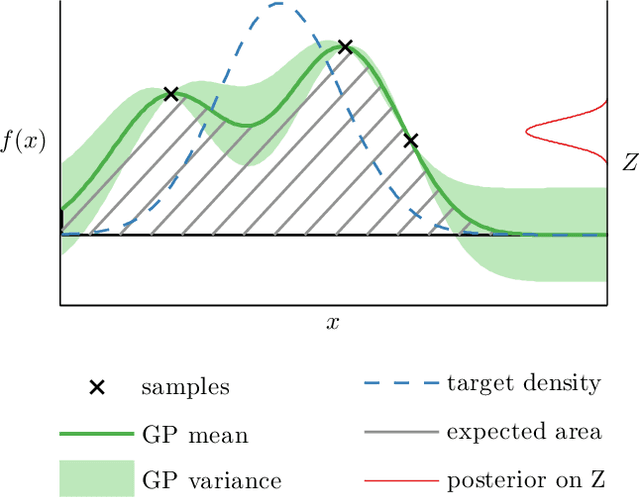
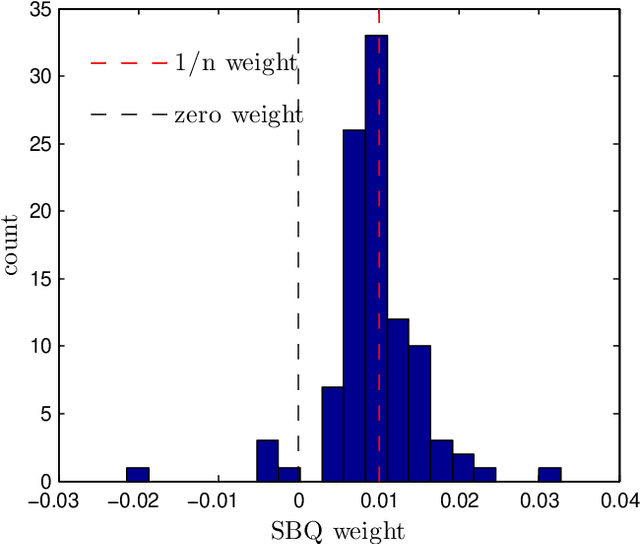
Herding and kernel herding are deterministic methods of choosing samples which summarise a probability distribution. A related task is choosing samples for estimating integrals using Bayesian quadrature. We show that the criterion minimised when selecting samples in kernel herding is equivalent to the posterior variance in Bayesian quadrature. We then show that sequential Bayesian quadrature can be viewed as a weighted version of kernel herding which achieves performance superior to any other weighted herding method. We demonstrate empirically a rate of convergence faster than O(1/N). Our results also imply an upper bound on the empirical error of the Bayesian quadrature estimate.