 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Models in K-12 Education: Alignment with State Curriculum Standards and Student Personas
Jun 03, 2026As Large Language Models (LLMs) become increasingly popular in educational settings, they raise important questions about the ethical implications of their use. Publicly available online chatbots are quickly improving in capability and accuracy leading to more widespread use, including among students looking for help with their homework. This makes it crucial to consider whether these models are aligned with educational standards. Because curriculum standards in the United States are set at the state level, they differ significantly in required content, emphasis, and narrative focus. In this work, we develop an LLM-based pipeline to identify variations in U.S. History curricula across states and evaluate the extent to which different LLMs reflect these state-specific curricular differences. In addition, we conduct controlled experiments that vary user personas by stating user attributes such as geographic location, grade level, gender and race to evaluate the sensitivity of LLM responses to user characteristics. We find that while models are able to adjust their presentation of historical topics, these shifts may come from the perceived political leanings of states and do not necessarily reflect actual curriculum content. Additionally, models successfully adapt to a student's grade level while showing minimal sensitivity to race or gender, suggesting they are capable of useful adaptation to student personas with limited demographic bias. Together, these findings highlight potential risks that open access to LLM chatbots may cause to student learning outcomes stemming from misalignment with state curriculum standards and highlight the need for more robust alignment techniques.
TwERC: High Performance Ensembled Candidate Generation for Ads Recommendation at Twitter
Feb 27, 2023



Recommendation systems are a core feature of social media companies with their uses including recommending organic and promoted contents. Many modern recommendation systems are split into multiple stages - candidate generation and heavy ranking - to balance computational cost against recommendation quality. We focus on the candidate generation phase of a large-scale ads recommendation problem in this paper, and present a machine learning first heterogeneous re-architecture of this stage which we term TwERC. We show that a system that combines a real-time light ranker with sourcing strategies capable of capturing additional information provides validated gains. We present two strategies. The first strategy uses a notion of similarity in the interaction graph, while the second strategy caches previous scores from the ranking stage. The graph based strategy achieves a 4.08% revenue gain and the rankscore based strategy achieves a 1.38% gain. These two strategies have biases that complement both the light ranker and one another. Finally, we describe a set of metrics that we believe are valuable as a means of understanding the complex product trade offs inherent in industrial candidate generation systems.
Random Isn't Always Fair: Candidate Set Imbalance and Exposure Inequality in Recommender Systems
Sep 12, 2022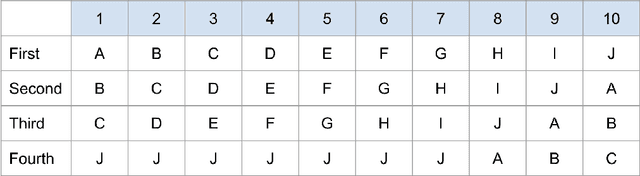

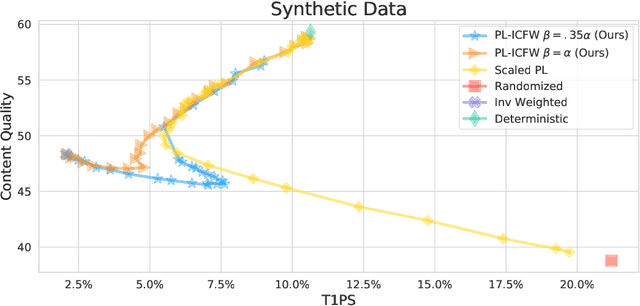
Traditionally, recommender systems operate by returning a user a set of items, ranked in order of estimated relevance to that user. In recent years, methods relying on stochastic ordering have been developed to create "fairer" rankings that reduce inequality in who or what is shown to users. Complete randomization -- ordering candidate items randomly, independent of estimated relevance -- is largely considered a baseline procedure that results in the most equal distribution of exposure. In industry settings, recommender systems often operate via a two-step process in which candidate items are first produced using computationally inexpensive methods and then a full ranking model is applied only to those candidates. In this paper, we consider the effects of inequality at the first step and show that, paradoxically, complete randomization at the second step can result in a higher degree of inequality relative to deterministic ordering of items by estimated relevance scores. In light of this observation, we then propose a simple post-processing algorithm in pursuit of reducing exposure inequality that works both when candidate sets have a high level of imbalance and when they do not. The efficacy of our method is illustrated on both simulated data and a common benchmark data set used in studying fairness in recommender systems.
Measuring Disparate Outcomes of Content Recommendation Algorithms with Distributional Inequality Metrics
Feb 03, 2022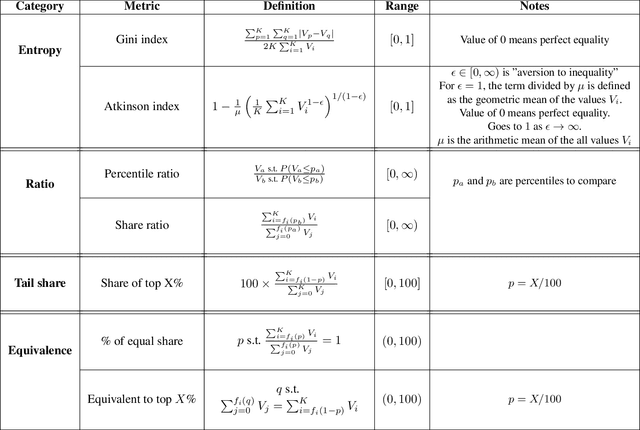
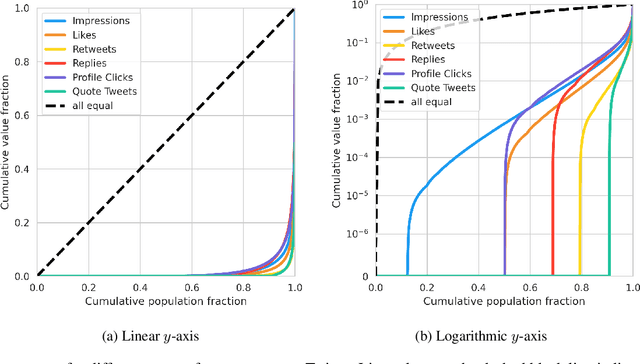
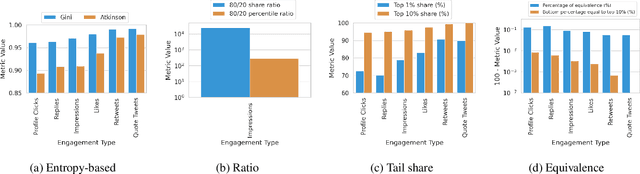
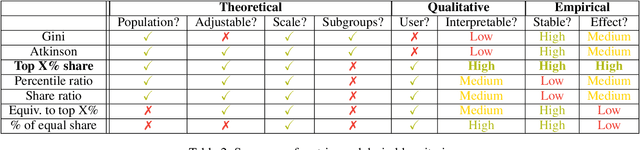
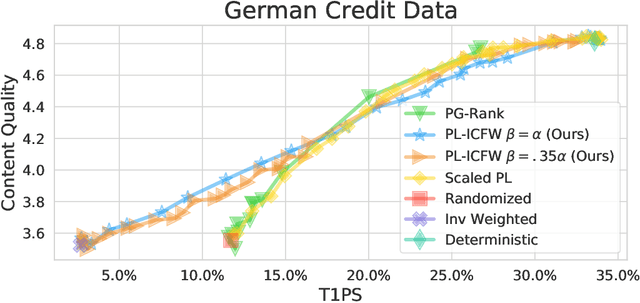
The harmful impacts of algorithmic decision systems have recently come into focus, with many examples of systems such as machine learning (ML) models amplifying existing societal biases. Most metrics attempting to quantify disparities resulting from ML algorithms focus on differences between groups, dividing users based on demographic identities and comparing model performance or overall outcomes between these groups. However, in industry settings, such information is often not available, and inferring these characteristics carries its own risks and biases. Moreover, typical metrics that focus on a single classifier's output ignore the complex network of systems that produce outcomes in real-world settings. In this paper, we evaluate a set of metrics originating from economics, distributional inequality metrics, and their ability to measure disparities in content exposure in a production recommendation system, the Twitter algorithmic timeline. We define desirable criteria for metrics to be used in an operational setting, specifically by ML practitioners. We characterize different types of engagement with content on Twitter using these metrics, and use these results to evaluate the metrics with respect to the desired criteria. We show that we can use these metrics to identify content suggestion algorithms that contribute more strongly to skewed outcomes between users. Overall, we conclude that these metrics can be useful tools for understanding disparate outcomes in online social networks.
Learning to Repair Software Vulnerabilities with Generative Adversarial Networks
Oct 28, 2018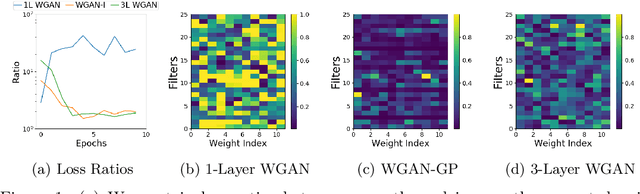
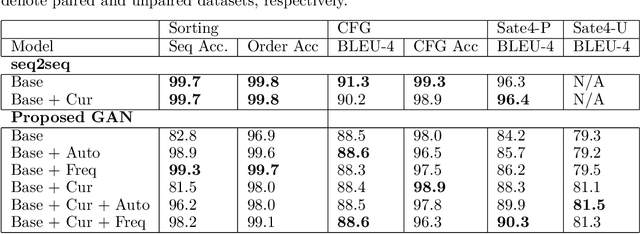

Motivated by the problem of automated repair of software vulnerabilities, we propose an adversarial learning approach that maps from one discrete source domain to another target domain without requiring paired labeled examples or source and target domains to be bijections. We demonstrate that the proposed adversarial learning approach is an effective technique for repairing software vulnerabilities, performing close to seq2seq approaches that require labeled pairs. The proposed Generative Adversarial Network approach is application-agnostic in that it can be applied to other problems similar to code repair, such as grammar correction or sentiment translation.
Automated software vulnerability detection with machine learning
Aug 02, 2018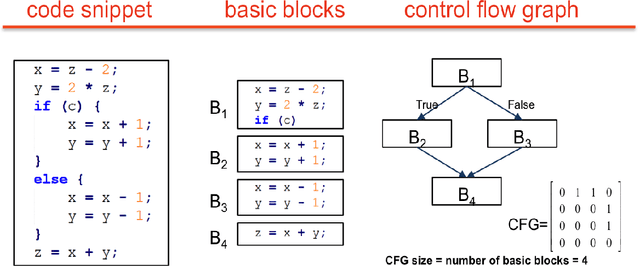
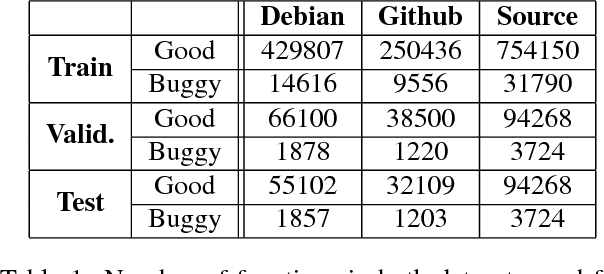
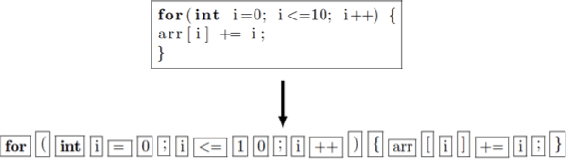
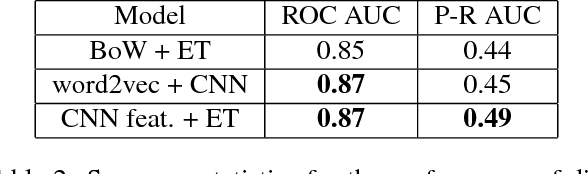
Thousands of security vulnerabilities are discovered in production software each year, either reported publicly to the Common Vulnerabilities and Exposures database or discovered internally in proprietary code. Vulnerabilities often manifest themselves in subtle ways that are not obvious to code reviewers or the developers themselves. With the wealth of open source code available for analysis, there is an opportunity to learn the patterns of bugs that can lead to security vulnerabilities directly from data. In this paper, we present a data-driven approach to vulnerability detection using machine learning, specifically applied to C and C++ programs. We first compile a large dataset of hundreds of thousands of open-source functions labeled with the outputs of a static analyzer. We then compare methods applied directly to source code with methods applied to artifacts extracted from the build process, finding that source-based models perform better. We also compare the application of deep neural network models with more traditional models such as random forests and find the best performance comes from combining features learned by deep models with tree-based models. Ultimately, our highest performing model achieves an area under the precision-recall curve of 0.49 and an area under the ROC curve of 0.87.
Automated Vulnerability Detection in Source Code Using Deep Representation Learning
Jul 11, 2018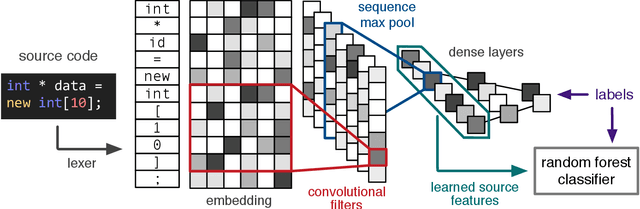
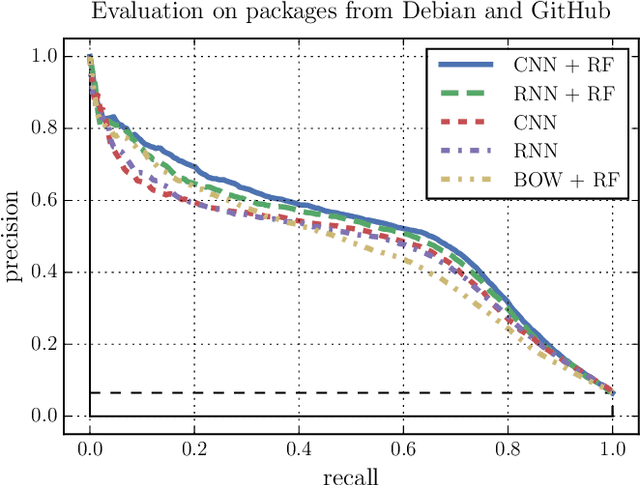
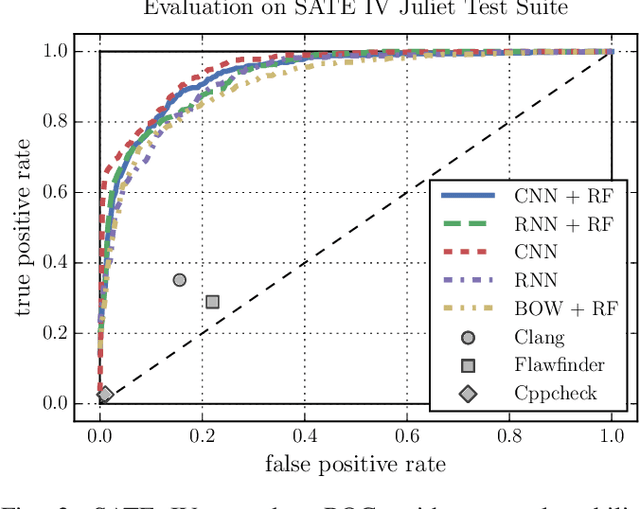
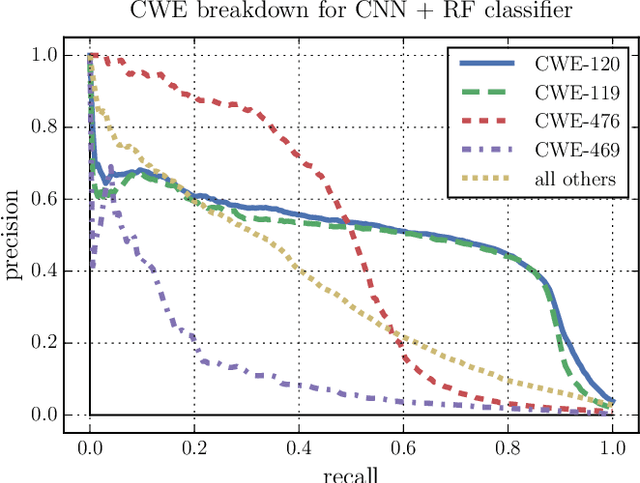
Increasing numbers of software vulnerabilities are discovered every year whether they are reported publicly or discovered internally in proprietary code. These vulnerabilities can pose serious risk of exploit and result in system compromise, information leaks, or denial of service. We leveraged the wealth of C and C++ open-source code available to develop a large-scale function-level vulnerability detection system using machine learning. To supplement existing labeled vulnerability datasets, we compiled a vast dataset of millions of open-source functions and labeled it with carefully-selected findings from three different static analyzers that indicate potential exploits. Using these datasets, we developed a fast and scalable vulnerability detection tool based on deep feature representation learning that directly interprets lexed source code. We evaluated our tool on code from both real software packages and the NIST SATE IV benchmark dataset. Our results demonstrate that deep feature representation learning on source code is a promising approach for automated software vulnerability detection.