 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNormative Robustness as a Frontier for Non-Verifiable Reasoning in LLMs
Jun 10, 2026As LLMs increasingly serve in advisory and deliberative roles, users rely on them for non-verifiable reasoning in domains lacking objective ground truths. However, traditional evaluations of LLM reasoning focus almost exclusively on fact-based domains, such as mathematics and science, leaving uncertainty over whether and to what degree models can handle ambiguous, subjective, or value-laden problems over time. To address this concern, we propose moral reasoning as a paradigmatic subdomain of non-verifiable reasoning. We define moral robustness as a model's capacity to exhibit sound moral reasoning across time and contexts, and we introduce a scalable, adversarial, multi-turn evaluation framework to empirically measure this capability. We simulate 48,000 user-agent moral deliberations across four frontier LLMs, varying premise relevance, premise order, conversation duration, and the user's stated moral view. We find that models successfully ignore morally-irrelevant distractors, but shift their reasoning by up to 6.5%, on average, towards the user's stated preferred moral view, and varying their reasoning depending on factors such as order (altering moral judgments by order in 13-22% of the cases) and duration (altering moral judgments between single-turn and multi-turn in 10-24% of the cases). Our analysis indicates that models tailor not just their final verdicts but their underlying justifications to align with a user's moral viewpoint - a failure mode we characterize as moral deliberative sycophancy.
Evaluating Language Models for Harmful Manipulation
Mar 26, 2026Interest in the concept of AI-driven harmful manipulation is growing, yet current approaches to evaluating it are limited. This paper introduces a framework for evaluating harmful AI manipulation via context-specific human-AI interaction studies. We illustrate the utility of this framework by assessing an AI model with 10,101 participants spanning interactions in three AI use domains (public policy, finance, and health) and three locales (US, UK, and India). Overall, we find that that the tested model can produce manipulative behaviours when prompted to do so and, in experimental settings, is able to induce belief and behaviour changes in study participants. We further find that context matters: AI manipulation differs between domains, suggesting that it needs to be evaluated in the high-stakes context(s) in which an AI system is likely to be used. We also identify significant differences across our tested geographies, suggesting that AI manipulation results from one geographic region may not generalise to others. Finally, we find that the frequency of manipulative behaviours (propensity) of an AI model is not consistently predictive of the likelihood of manipulative success (efficacy), underscoring the importance of studying these dimensions separately. To facilitate adoption of our evaluation framework, we detail our testing protocols and make relevant materials publicly available. We conclude by discussing open challenges in evaluating harmful manipulation by AI models.
The Intersectionality Problem for Algorithmic Fairness
Nov 04, 2024A yet unmet challenge in algorithmic fairness is the problem of intersectionality, that is, achieving fairness across the intersection of multiple groups -- and verifying that such fairness has been attained. Because intersectional groups tend to be small, verifying whether a model is fair raises statistical as well as moral-methodological challenges. This paper (1) elucidates the problem of intersectionality in algorithmic fairness, (2) develops desiderata to clarify the challenges underlying the problem and guide the search for potential solutions, (3) illustrates the desiderata and potential solutions by sketching a proposal using simple hypothesis testing, and (4) evaluates, partly empirically, this proposal against the proposed desiderata.
Imagen 3
Aug 13, 2024We introduce Imagen 3, a latent diffusion model that generates high quality images from text prompts. We describe our quality and responsibility evaluations. Imagen 3 is preferred over other state-of-the-art (SOTA) models at the time of evaluation. In addition, we discuss issues around safety and representation, as well as methods we used to minimize the potential harm of our models.
STAR: SocioTechnical Approach to Red Teaming Language Models
Jun 17, 2024This research introduces STAR, a sociotechnical framework that improves on current best practices for red teaming safety of large language models. STAR makes two key contributions: it enhances steerability by generating parameterised instructions for human red teamers, leading to improved coverage of the risk surface. Parameterised instructions also provide more detailed insights into model failures at no increased cost. Second, STAR improves signal quality by matching demographics to assess harms for specific groups, resulting in more sensitive annotations. STAR further employs a novel step of arbitration to leverage diverse viewpoints and improve label reliability, treating disagreement not as noise but as a valuable contribution to signal quality.
The Impossibility of Fair LLMs
May 28, 2024The need for fair AI is increasingly clear in the era of general-purpose systems such as ChatGPT, Gemini, and other large language models (LLMs). However, the increasing complexity of human-AI interaction and its social impacts have raised questions of how fairness standards could be applied. Here, we review the technical frameworks that machine learning researchers have used to evaluate fairness, such as group fairness and fair representations, and find that their application to LLMs faces inherent limitations. We show that each framework either does not logically extend to LLMs or presents a notion of fairness that is intractable for LLMs, primarily due to the multitudes of populations affected, sensitive attributes, and use cases. To address these challenges, we develop guidelines for the more realistic goal of achieving fairness in particular use cases: the criticality of context, the responsibility of LLM developers, and the need for stakeholder participation in an iterative process of design and evaluation. Moreover, it may eventually be possible and even necessary to use the general-purpose capabilities of AI systems to address fairness challenges as a form of scalable AI-assisted alignment.
Bias in Language Models: Beyond Trick Tests and Toward RUTEd Evaluation
Feb 20, 2024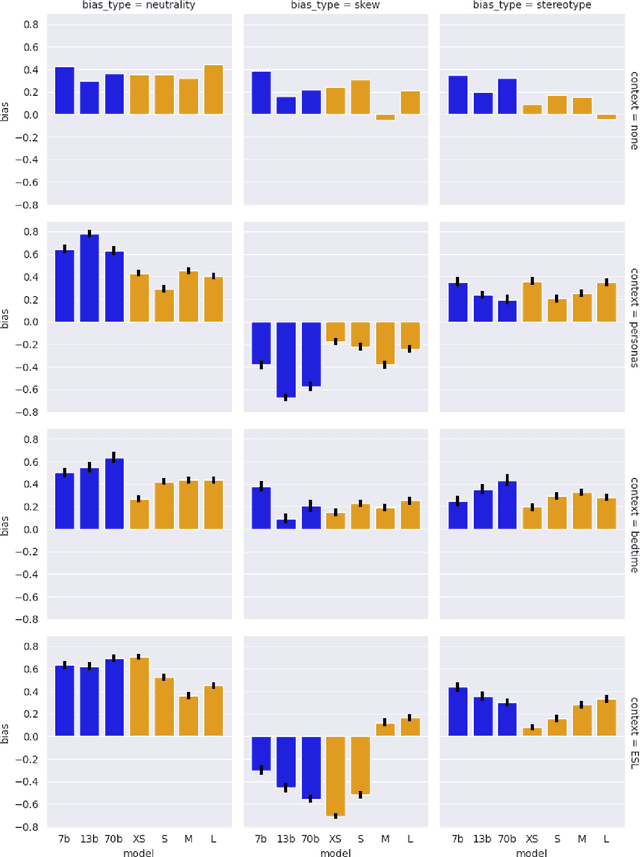
Bias benchmarks are a popular method for studying the negative impacts of bias in LLMs, yet there has been little empirical investigation of whether these benchmarks are actually indicative of how real world harm may manifest in the real world. In this work, we study the correspondence between such decontextualized "trick tests" and evaluations that are more grounded in Realistic Use and Tangible {Effects (i.e. RUTEd evaluations). We explore this correlation in the context of gender-occupation bias--a popular genre of bias evaluation. We compare three de-contextualized evaluations adapted from the current literature to three analogous RUTEd evaluations applied to long-form content generation. We conduct each evaluation for seven instruction-tuned LLMs. For the RUTEd evaluations, we conduct repeated trials of three text generation tasks: children's bedtime stories, user personas, and English language learning exercises. We found no correspondence between trick tests and RUTEd evaluations. Specifically, selecting the least biased model based on the de-contextualized results coincides with selecting the model with the best performance on RUTEd evaluations only as often as random chance. We conclude that evaluations that are not based in realistic use are likely insufficient to mitigate and assess bias and real-world harms.
Random Isn't Always Fair: Candidate Set Imbalance and Exposure Inequality in Recommender Systems
Sep 12, 2022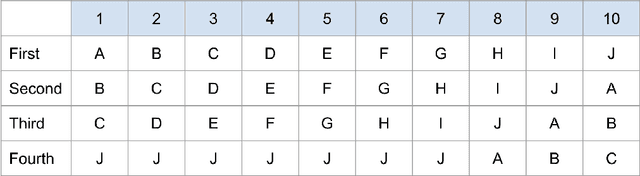

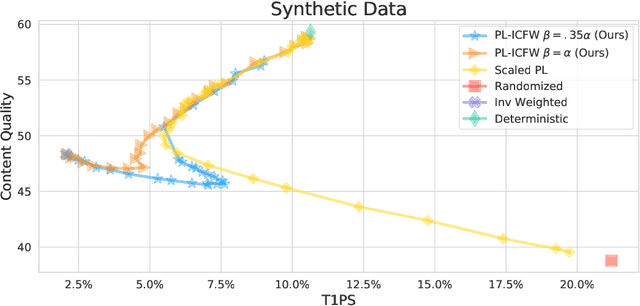
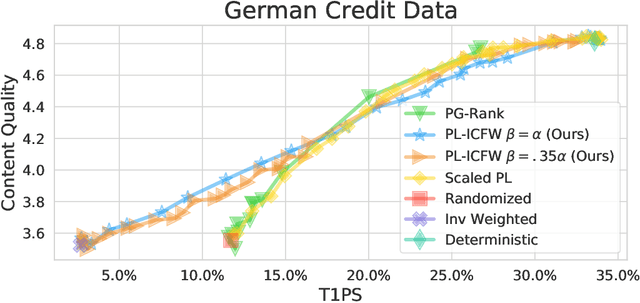
Traditionally, recommender systems operate by returning a user a set of items, ranked in order of estimated relevance to that user. In recent years, methods relying on stochastic ordering have been developed to create "fairer" rankings that reduce inequality in who or what is shown to users. Complete randomization -- ordering candidate items randomly, independent of estimated relevance -- is largely considered a baseline procedure that results in the most equal distribution of exposure. In industry settings, recommender systems often operate via a two-step process in which candidate items are first produced using computationally inexpensive methods and then a full ranking model is applied only to those candidates. In this paper, we consider the effects of inequality at the first step and show that, paradoxically, complete randomization at the second step can result in a higher degree of inequality relative to deterministic ordering of items by estimated relevance scores. In light of this observation, we then propose a simple post-processing algorithm in pursuit of reducing exposure inequality that works both when candidate sets have a high level of imbalance and when they do not. The efficacy of our method is illustrated on both simulated data and a common benchmark data set used in studying fairness in recommender systems.
Measuring and mitigating voting access disparities: a study of race and polling locations in Florida and North Carolina
May 30, 2022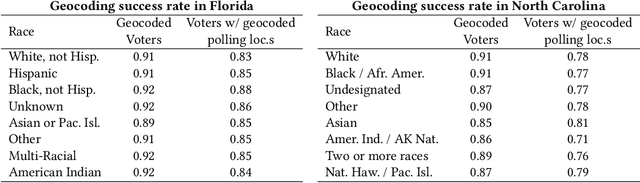

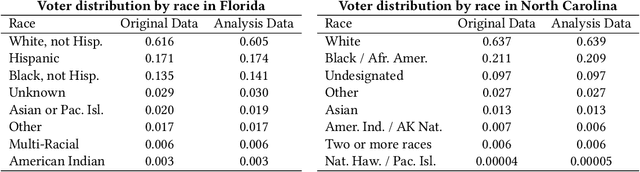

Voter suppression and associated racial disparities in access to voting are long-standing civil rights concerns in the United States. Barriers to voting have taken many forms over the decades. A history of violent explicit discouragement has shifted to more subtle access limitations that can include long lines and wait times, long travel times to reach a polling station, and other logistical barriers to voting. Our focus in this work is on quantifying disparities in voting access pertaining to the overall time-to-vote, and how they could be remedied via a better choice of polling location or provisioning more sites where voters can cast ballots. However, appropriately calibrating access disparities is difficult because of the need to account for factors such as population density and different community expectations for reasonable travel times. In this paper, we quantify access to polling locations, developing a methodology for the calibrated measurement of racial disparities in polling location "load" and distance to polling locations. We apply this methodology to a study of real-world data from Florida and North Carolina to identify disparities in voting access from the 2020 election. We also introduce algorithms, with modifications to handle scale, that can reduce these disparities by suggesting new polling locations from a given list of identified public locations (including schools and libraries). Applying these algorithms on the 2020 election location data also helps to expose and explore tradeoffs between the cost of allocating more polling locations and the potential impact on access disparities. The developed voting access measurement methodology and algorithmic remediation technique is a first step in better polling location assignment.
De-biasing "bias" measurement
May 11, 2022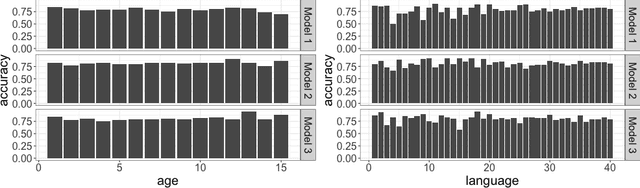

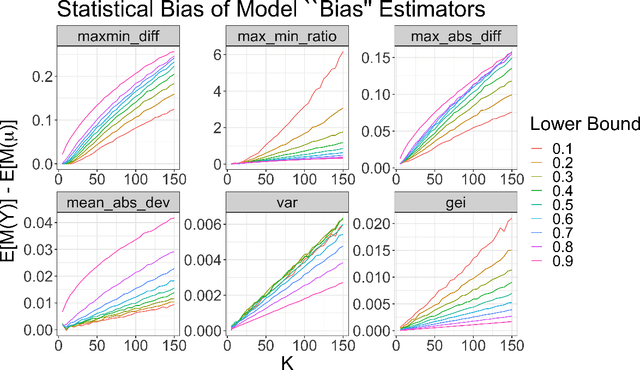
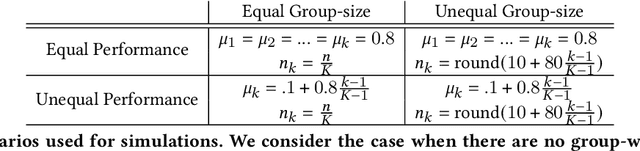
When a model's performance differs across socially or culturally relevant groups--like race, gender, or the intersections of many such groups--it is often called "biased." While much of the work in algorithmic fairness over the last several years has focused on developing various definitions of model fairness (the absence of group-wise model performance disparities) and eliminating such "bias," much less work has gone into rigorously measuring it. In practice, it important to have high quality, human digestible measures of model performance disparities and associated uncertainty quantification about them that can serve as inputs into multi-faceted decision-making processes. In this paper, we show both mathematically and through simulation that many of the metrics used to measure group-wise model performance disparities are themselves statistically biased estimators of the underlying quantities they purport to represent. We argue that this can cause misleading conclusions about the relative group-wise model performance disparities along different dimensions, especially in cases where some sensitive variables consist of categories with few members. We propose the "double-corrected" variance estimator, which provides unbiased estimates and uncertainty quantification of the variance of model performance across groups. It is conceptually simple and easily implementable without statistical software package or numerical optimization. We demonstrate the utility of this approach through simulation and show on a real dataset that while statistically biased estimators of model group-wise model performance disparities indicate statistically significant between-group model performance disparities, when accounting for statistical bias in the estimator, the estimated group-wise disparities in model performance are no longer statistically significant.