 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasuring and mitigating voting access disparities: a study of race and polling locations in Florida and North Carolina
May 30, 2022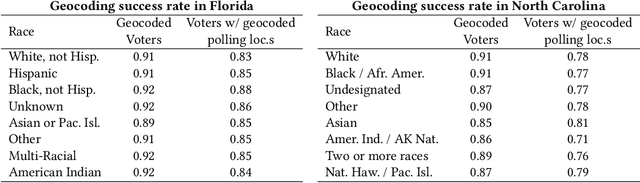

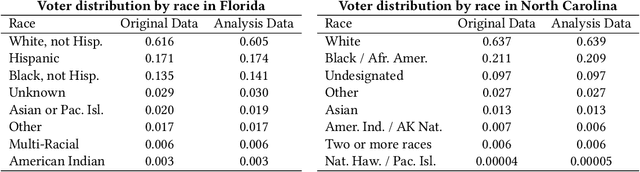

Voter suppression and associated racial disparities in access to voting are long-standing civil rights concerns in the United States. Barriers to voting have taken many forms over the decades. A history of violent explicit discouragement has shifted to more subtle access limitations that can include long lines and wait times, long travel times to reach a polling station, and other logistical barriers to voting. Our focus in this work is on quantifying disparities in voting access pertaining to the overall time-to-vote, and how they could be remedied via a better choice of polling location or provisioning more sites where voters can cast ballots. However, appropriately calibrating access disparities is difficult because of the need to account for factors such as population density and different community expectations for reasonable travel times. In this paper, we quantify access to polling locations, developing a methodology for the calibrated measurement of racial disparities in polling location "load" and distance to polling locations. We apply this methodology to a study of real-world data from Florida and North Carolina to identify disparities in voting access from the 2020 election. We also introduce algorithms, with modifications to handle scale, that can reduce these disparities by suggesting new polling locations from a given list of identified public locations (including schools and libraries). Applying these algorithms on the 2020 election location data also helps to expose and explore tradeoffs between the cost of allocating more polling locations and the potential impact on access disparities. The developed voting access measurement methodology and algorithmic remediation technique is a first step in better polling location assignment.
Fair clustering via equitable group representations
Jun 19, 2020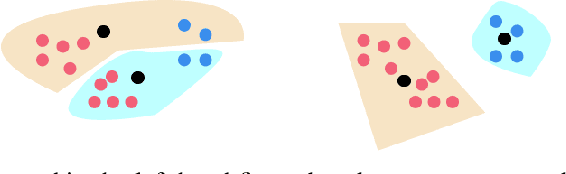

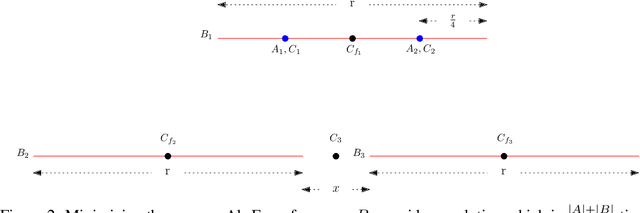
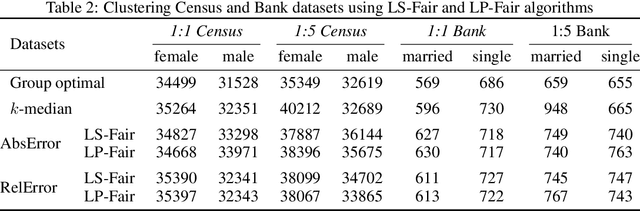
What does it mean for a clustering to be fair? One popular approach seeks to ensure that each cluster contains groups in (roughly) the same proportion in which they exist in the population. The normative principle at play is balance: any cluster might act as a representative of the data, and thus should reflect its diversity. But clustering also captures a different form of representativeness. A core principle in most clustering problems is that a cluster center should be representative of the cluster it represents, by being "close" to the points associated with it. This is so that we can effectively replace the points by their cluster centers without significant loss in fidelity, and indeed is a common "use case" for clustering. For such a clustering to be fair, the centers should "represent" different groups equally well. We call such a clustering a group-representative clustering. In this paper, we study the structure and computation of group-representative clusterings. We show that this notion naturally parallels the development of fairness notions in classification, with direct analogs of ideas like demographic parity and equal opportunity. We demonstrate how these notions are distinct from and cannot be captured by balance-based notions of fairness. We present approximation algorithms for group representative $k$-median clustering and couple this with an empirical evaluation on various real-world data sets.
Fairness in representation: quantifying stereotyping as a representational harm
Jan 28, 2019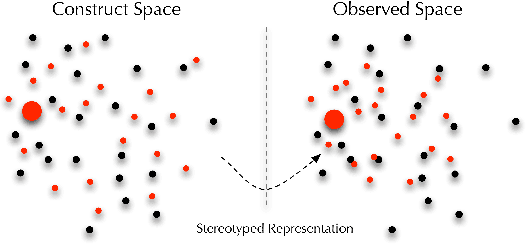
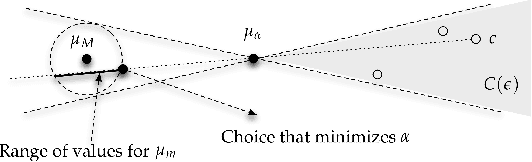
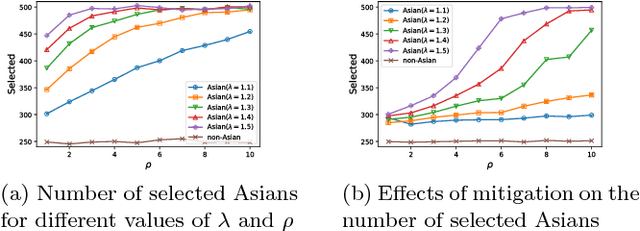
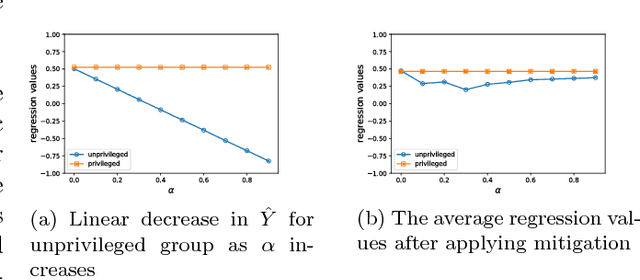
While harms of allocation have been increasingly studied as part of the subfield of algorithmic fairness, harms of representation have received considerably less attention. In this paper, we formalize two notions of stereotyping and show how they manifest in later allocative harms within the machine learning pipeline. We also propose mitigation strategies and demonstrate their effectiveness on synthetic datasets.