 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersistent Classification: A New Approach to Stability of Data and Adversarial Examples
Apr 11, 2024



There are a number of hypotheses underlying the existence of adversarial examples for classification problems. These include the high-dimensionality of the data, high codimension in the ambient space of the data manifolds of interest, and that the structure of machine learning models may encourage classifiers to develop decision boundaries close to data points. This article proposes a new framework for studying adversarial examples that does not depend directly on the distance to the decision boundary. Similarly to the smoothed classifier literature, we define a (natural or adversarial) data point to be $(\gamma,\sigma)$-stable if the probability of the same classification is at least $\gamma$ for points sampled in a Gaussian neighborhood of the point with a given standard deviation $\sigma$. We focus on studying the differences between persistence metrics along interpolants of natural and adversarial points. We show that adversarial examples have significantly lower persistence than natural examples for large neural networks in the context of the MNIST and ImageNet datasets. We connect this lack of persistence with decision boundary geometry by measuring angles of interpolants with respect to decision boundaries. Finally, we connect this approach with robustness by developing a manifold alignment gradient metric and demonstrating the increase in robustness that can be achieved when training with the addition of this metric.
UnProjection: Leveraging Inverse-Projections for Visual Analytics of High-Dimensional Data
Nov 02, 2021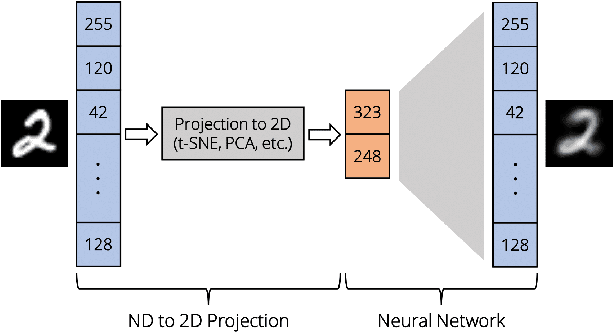
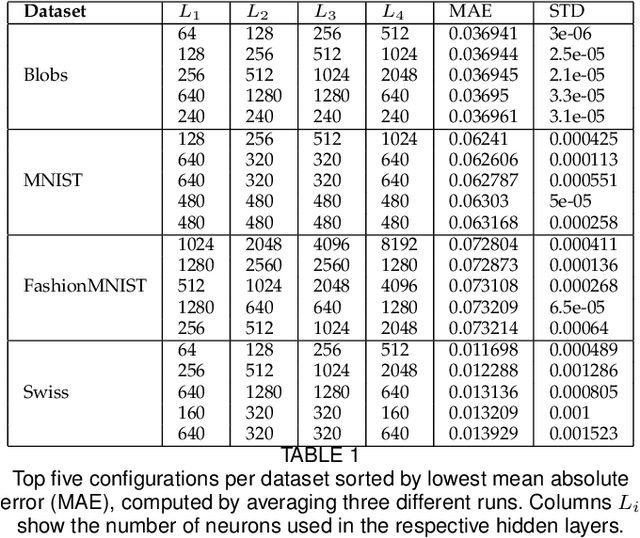

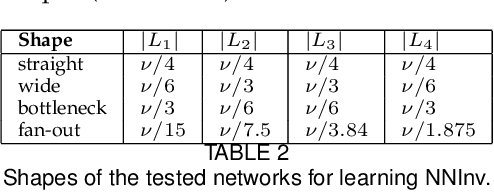
Projection techniques are often used to visualize high-dimensional data, allowing users to better understand the overall structure of multi-dimensional spaces on a 2D screen. Although many such methods exist, comparably little work has been done on generalizable methods of inverse-projection -- the process of mapping the projected points, or more generally, the projection space back to the original high-dimensional space. In this paper we present NNInv, a deep learning technique with the ability to approximate the inverse of any projection or mapping. NNInv learns to reconstruct high-dimensional data from any arbitrary point on a 2D projection space, giving users the ability to interact with the learned high-dimensional representation in a visual analytics system. We provide an analysis of the parameter space of NNInv, and offer guidance in selecting these parameters. We extend validation of the effectiveness of NNInv through a series of quantitative and qualitative analyses. We then demonstrate the method's utility by applying it to three visualization tasks: interactive instance interpolation, classifier agreement, and gradient visualization.
Comparing Deep Neural Nets with UMAP Tour
Oct 18, 2021

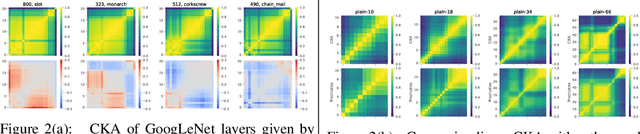
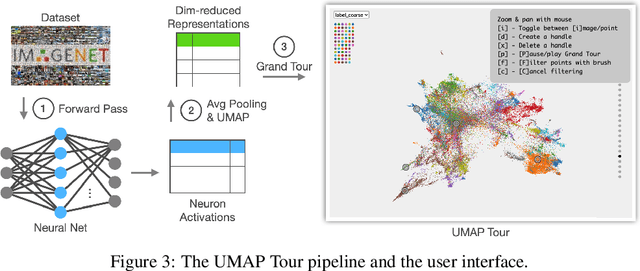
Neural networks should be interpretable to humans. In particular, there is a growing interest in concepts learned in a layer and similarity between layers. In this work, a tool, UMAP Tour, is built to visually inspect and compare internal behavior of real-world neural network models using well-aligned, instance-level representations. The method used in the visualization also implies a new similarity measure between neural network layers. Using the visual tool and the similarity measure, we find concepts learned in state-of-the-art models and dissimilarities between them, such as GoogLeNet and ResNet.
Problems with Shapley-value-based explanations as feature importance measures
Feb 25, 2020
Game-theoretic formulations of feature importance have become popular as a way to "explain" machine learning models. These methods define a cooperative game between the features of a model and distribute influence among these input elements using some form of the game's unique Shapley values. Justification for these methods rests on two pillars: their desirable mathematical properties, and their applicability to specific motivations for explanations. We show that mathematical problems arise when Shapley values are used for feature importance and that the solutions to mitigate these necessarily induce further complexity, such as the need for causal reasoning. We also draw on additional literature to argue that Shapley values do not provide explanations which suit human-centric goals of explainability.
Disentangling Influence: Using Disentangled Representations to Audit Model Predictions
Jun 20, 2019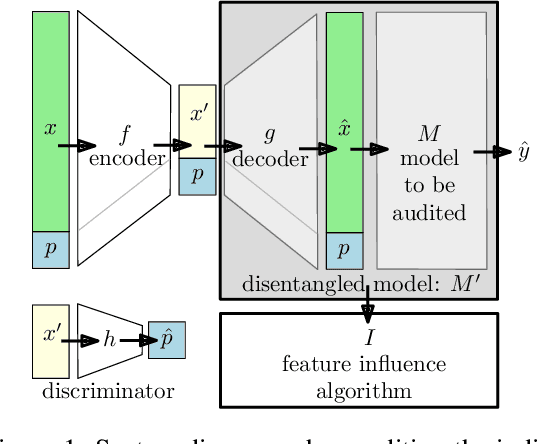
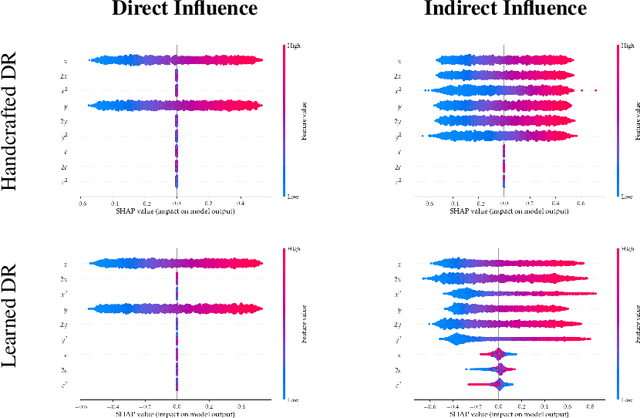
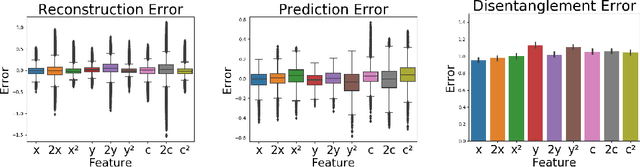
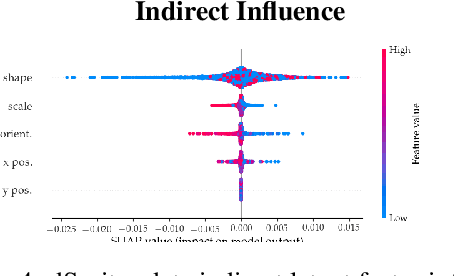
Motivated by the need to audit complex and black box models, there has been extensive research on quantifying how data features influence model predictions. Feature influence can be direct (a direct influence on model outcomes) and indirect (model outcomes are influenced via proxy features). Feature influence can also be expressed in aggregate over the training or test data or locally with respect to a single point. Current research has typically focused on one of each of these dimensions. In this paper, we develop disentangled influence audits, a procedure to audit the indirect influence of features. Specifically, we show that disentangled representations provide a mechanism to identify proxy features in the dataset, while allowing an explicit computation of feature influence on either individual outcomes or aggregate-level outcomes. We show through both theory and experiments that disentangled influence audits can both detect proxy features and show, for each individual or in aggregate, which of these proxy features affects the classifier being audited the most. In this respect, our method is more powerful than existing methods for ascertaining feature influence.
Assessing the Local Interpretability of Machine Learning Models
Feb 09, 2019
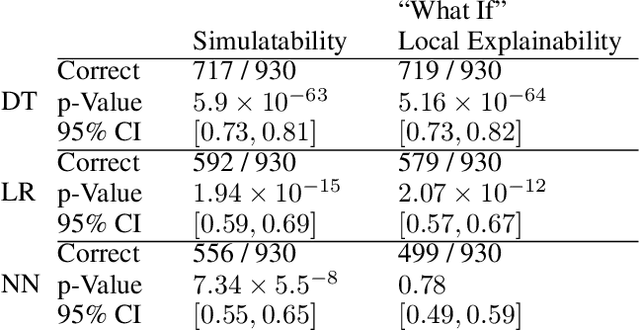


The increasing adoption of machine learning tools has led to calls for accountability via model interpretability. But what does it mean for a machine learning model to be interpretable by humans, and how can this be assessed? We focus on two definitions of interpretability that have been introduced in the machine learning literature: simulatability (a user's ability to run a model on a given input) and "what if" local explainability (a user's ability to correctly indicate the outcome to a model under local changes to the input). Through a user study with 1000 participants, we test whether humans perform well on tasks that mimic the definitions of simulatability and "what if" local explainability on models that are typically considered locally interpretable. We find evidence consistent with the common intuition that decision trees and logistic regression models are interpretable and are more interpretable than neural networks. We propose a metric - the runtime operation count on the simulatability task - to indicate the relative interpretability of models and show that as the number of operations increases the users' accuracy on the local interpretability tasks decreases.
Fairness in representation: quantifying stereotyping as a representational harm
Jan 28, 2019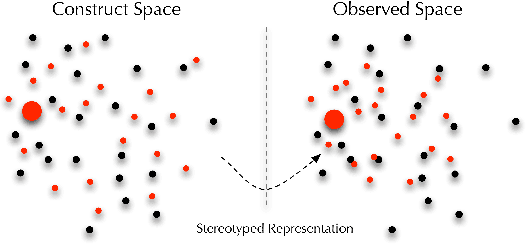
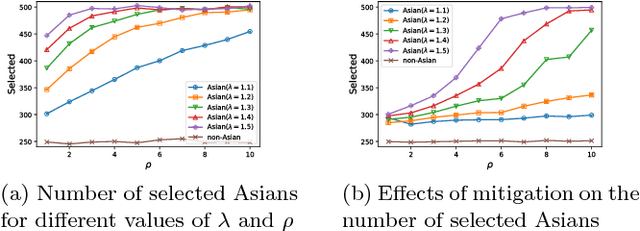
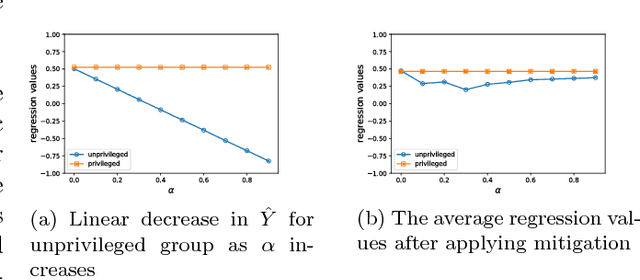
While harms of allocation have been increasingly studied as part of the subfield of algorithmic fairness, harms of representation have received considerably less attention. In this paper, we formalize two notions of stereotyping and show how they manifest in later allocative harms within the machine learning pipeline. We also propose mitigation strategies and demonstrate their effectiveness on synthetic datasets.
A comparative study of fairness-enhancing interventions in machine learning
Feb 13, 2018
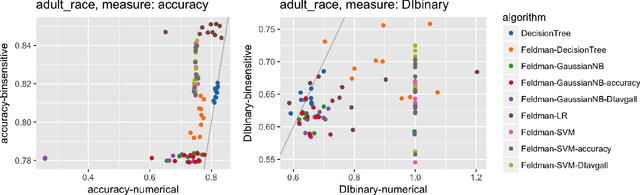
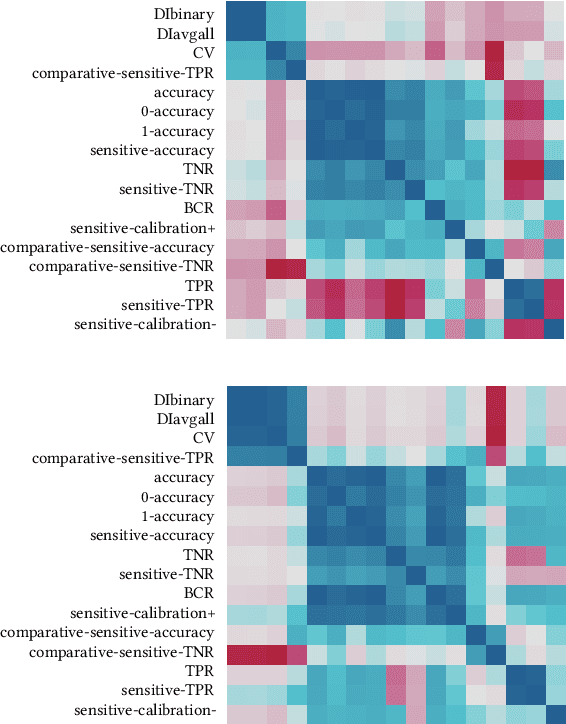
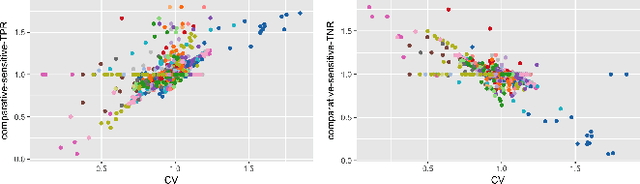
Computers are increasingly used to make decisions that have significant impact in people's lives. Often, these predictions can affect different population subgroups disproportionately. As a result, the issue of fairness has received much recent interest, and a number of fairness-enhanced classifiers and predictors have appeared in the literature. This paper seeks to study the following questions: how do these different techniques fundamentally compare to one another, and what accounts for the differences? Specifically, we seek to bring attention to many under-appreciated aspects of such fairness-enhancing interventions. Concretely, we present the results of an open benchmark we have developed that lets us compare a number of different algorithms under a variety of fairness measures, and a large number of existing datasets. We find that although different algorithms tend to prefer specific formulations of fairness preservations, many of these measures strongly correlate with one another. In addition, we find that fairness-preserving algorithms tend to be sensitive to fluctuations in dataset composition (simulated in our benchmark by varying training-test splits), indicating that fairness interventions might be more brittle than previously thought.
Runaway Feedback Loops in Predictive Policing
Dec 22, 2017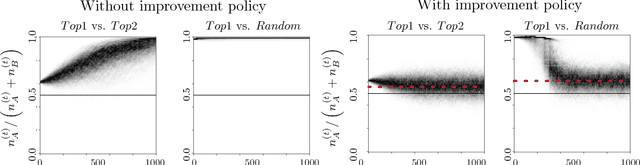
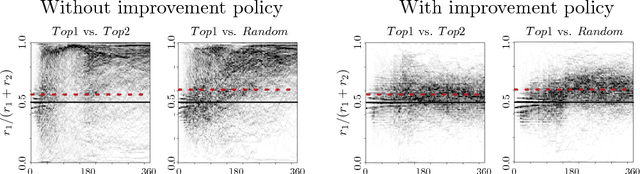
Predictive policing systems are increasingly used to determine how to allocate police across a city in order to best prevent crime. Discovered crime data (e.g., arrest counts) are used to help update the model, and the process is repeated. Such systems have been empirically shown to be susceptible to runaway feedback loops, where police are repeatedly sent back to the same neighborhoods regardless of the true crime rate. In response, we develop a mathematical model of predictive policing that proves why this feedback loop occurs, show empirically that this model exhibits such problems, and demonstrate how to change the inputs to a predictive policing system (in a black-box manner) so the runaway feedback loop does not occur, allowing the true crime rate to be learned. Our results are quantitative: we can establish a link (in our model) between the degree to which runaway feedback causes problems and the disparity in crime rates between areas. Moreover, we can also demonstrate the way in which \emph{reported} incidents of crime (those reported by residents) and \emph{discovered} incidents of crime (i.e. those directly observed by police officers dispatched as a result of the predictive policing algorithm) interact: in brief, while reported incidents can attenuate the degree of runaway feedback, they cannot entirely remove it without the interventions we suggest.
Auditing Black-box Models for Indirect Influence
Nov 30, 2016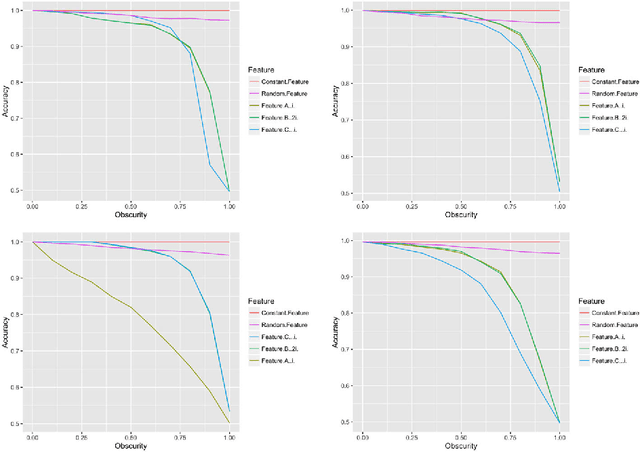
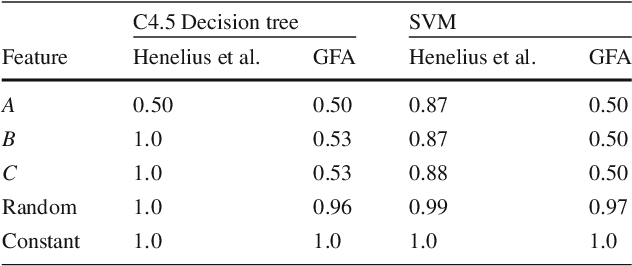
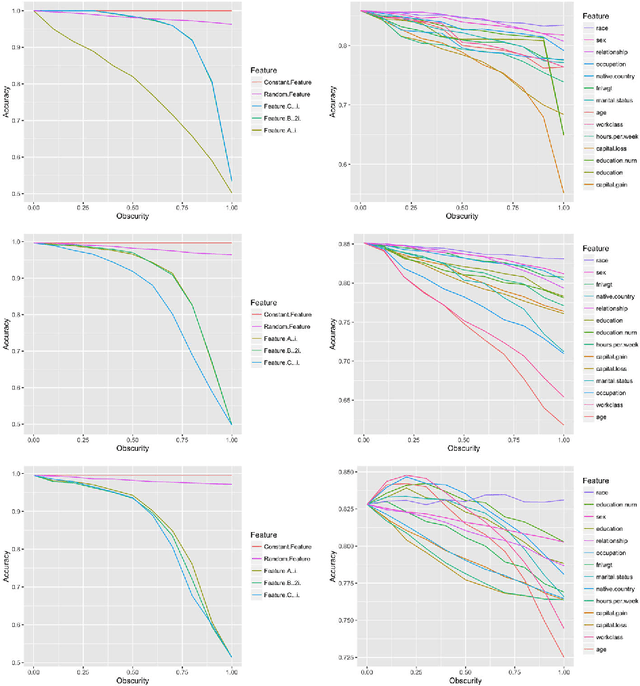
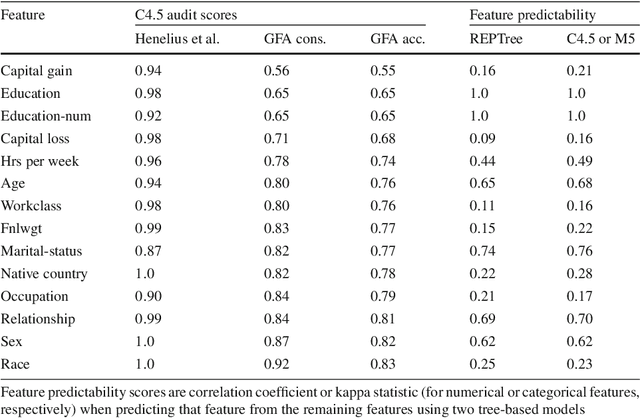
Data-trained predictive models see widespread use, but for the most part they are used as black boxes which output a prediction or score. It is therefore hard to acquire a deeper understanding of model behavior, and in particular how different features influence the model prediction. This is important when interpreting the behavior of complex models, or asserting that certain problematic attributes (like race or gender) are not unduly influencing decisions. In this paper, we present a technique for auditing black-box models, which lets us study the extent to which existing models take advantage of particular features in the dataset, without knowing how the models work. Our work focuses on the problem of indirect influence: how some features might indirectly influence outcomes via other, related features. As a result, we can find attribute influences even in cases where, upon further direct examination of the model, the attribute is not referred to by the model at all. Our approach does not require the black-box model to be retrained. This is important if (for example) the model is only accessible via an API, and contrasts our work with other methods that investigate feature influence like feature selection. We present experimental evidence for the effectiveness of our procedure using a variety of publicly available datasets and models. We also validate our procedure using techniques from interpretable learning and feature selection, as well as against other black-box auditing procedures.