 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeature Responsiveness Scores: Model-Agnostic Explanations for Recourse
Oct 29, 2024
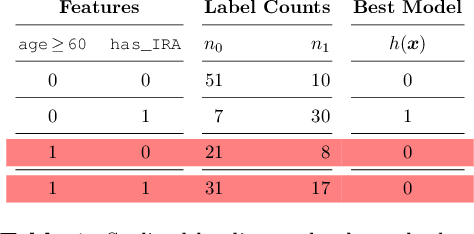
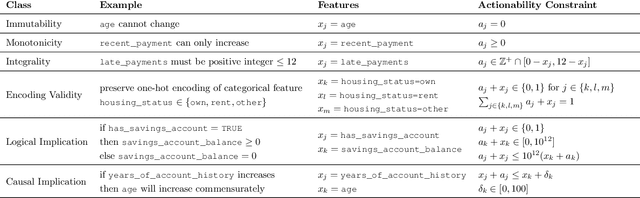

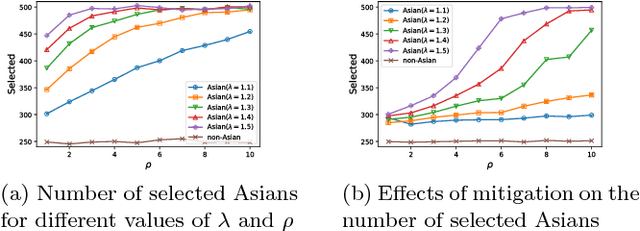
Machine learning models are often used to automate or support decisions in applications such as lending and hiring. In such settings, consumer protection rules mandate that we provide a list of "principal reasons" to consumers who receive adverse decisions. In practice, lenders and employers identify principal reasons by returning the top-scoring features from a feature attribution method. In this work, we study how such practices align with one of the underlying goals of consumer protection - recourse - i.e., educating individuals on how they can attain a desired outcome. We show that standard attribution methods can mislead individuals by highlighting reasons without recourse - i.e., by presenting consumers with features that cannot be changed to achieve recourse. We propose to address these issues by scoring features on the basis of responsiveness - i.e., the probability that an individual can attain a desired outcome by changing a specific feature. We develop efficient methods to compute responsiveness scores for any model and any dataset under complex actionability constraints. We present an extensive empirical study on the responsiveness of explanations in lending and demonstrate how responsiveness scores can be used to construct feature-highlighting explanations that lead to recourse and mitigate harm by flagging instances with fixed predictions.
Measuring and mitigating voting access disparities: a study of race and polling locations in Florida and North Carolina
May 30, 2022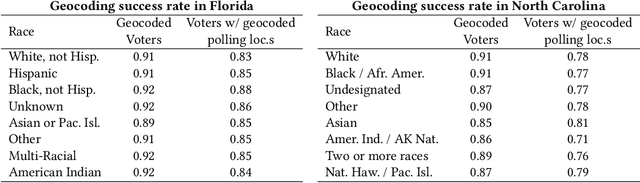

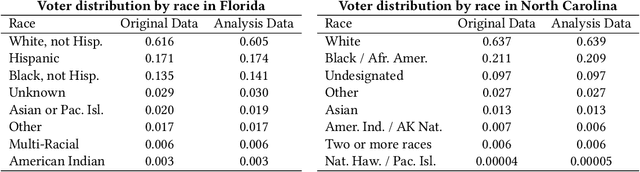

Voter suppression and associated racial disparities in access to voting are long-standing civil rights concerns in the United States. Barriers to voting have taken many forms over the decades. A history of violent explicit discouragement has shifted to more subtle access limitations that can include long lines and wait times, long travel times to reach a polling station, and other logistical barriers to voting. Our focus in this work is on quantifying disparities in voting access pertaining to the overall time-to-vote, and how they could be remedied via a better choice of polling location or provisioning more sites where voters can cast ballots. However, appropriately calibrating access disparities is difficult because of the need to account for factors such as population density and different community expectations for reasonable travel times. In this paper, we quantify access to polling locations, developing a methodology for the calibrated measurement of racial disparities in polling location "load" and distance to polling locations. We apply this methodology to a study of real-world data from Florida and North Carolina to identify disparities in voting access from the 2020 election. We also introduce algorithms, with modifications to handle scale, that can reduce these disparities by suggesting new polling locations from a given list of identified public locations (including schools and libraries). Applying these algorithms on the 2020 election location data also helps to expose and explore tradeoffs between the cost of allocating more polling locations and the potential impact on access disparities. The developed voting access measurement methodology and algorithmic remediation technique is a first step in better polling location assignment.
Energy Usage Reports: Environmental awareness as part of algorithmic accountability
Dec 16, 2019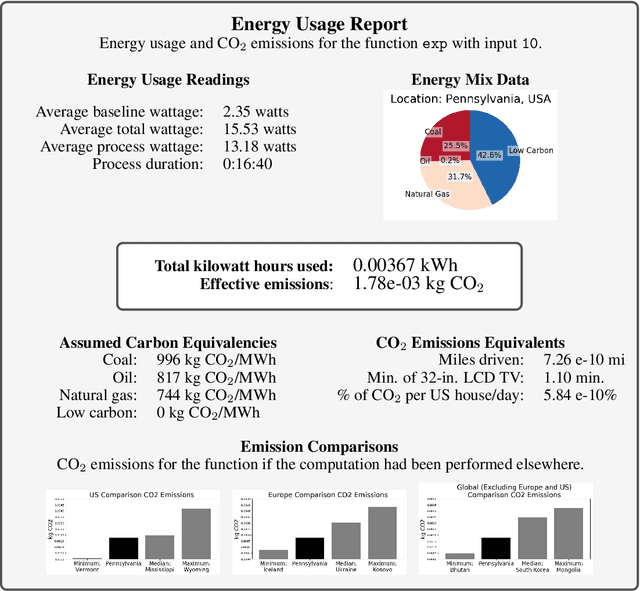
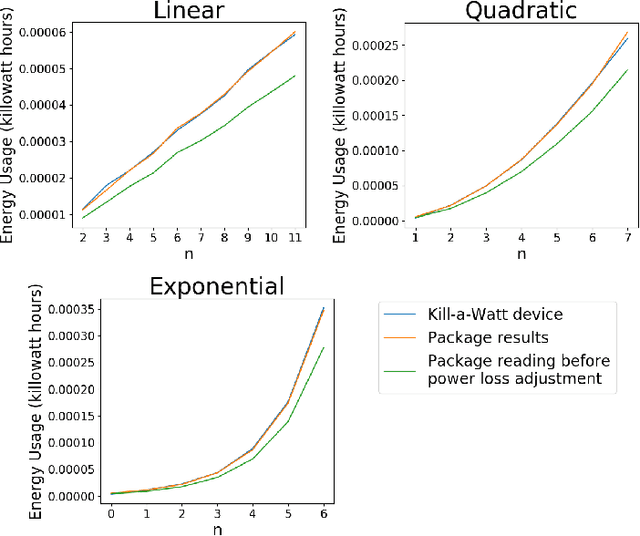
The carbon footprint of algorithms must be measured and transparently reported so computer scientists can take an honest and active role in environmental sustainability. In this paper, we take analyses usually applied at the industrial level and make them accessible for individual computer science researchers with an easy-to-use Python package. Localizing to the energy mixture of the electrical power grid, we make the conversion from energy usage to CO2 emissions, in addition to contextualizing these results with more human-understandable benchmarks such as automobile miles driven. We also include comparisons with energy mixtures employed in electrical grids around the world. We propose including these automatically-generated Energy Usage Reports as part of standard algorithmic accountability practices, and demonstrate the use of these reports as part of model-choice in a machine learning context.
Disentangling Influence: Using Disentangled Representations to Audit Model Predictions
Jun 20, 2019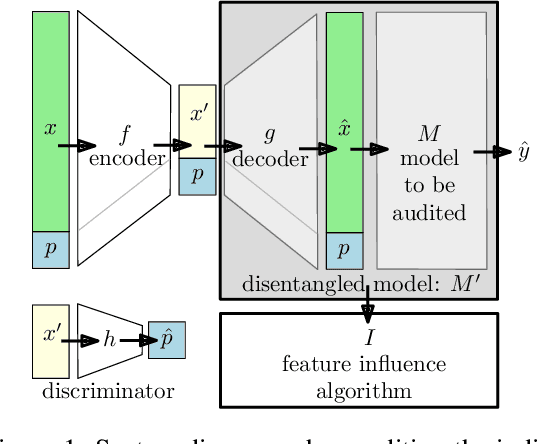
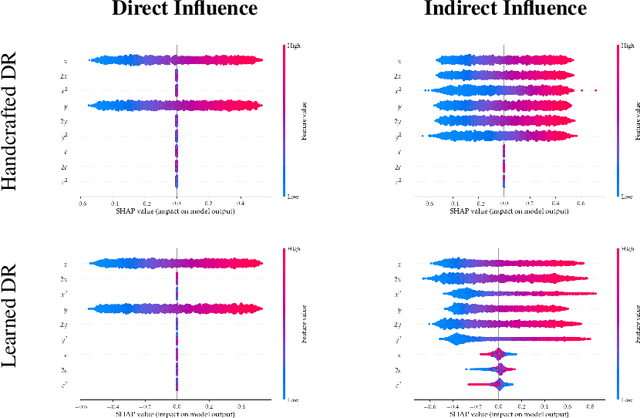
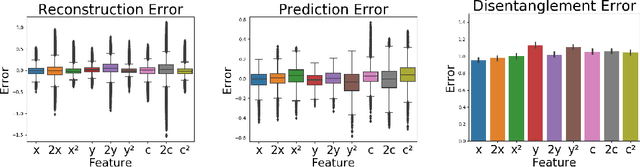
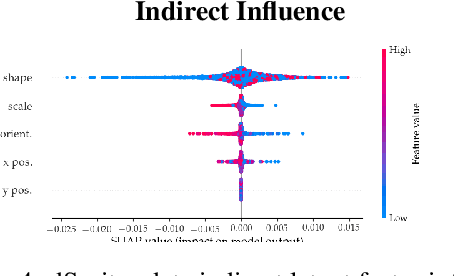
Motivated by the need to audit complex and black box models, there has been extensive research on quantifying how data features influence model predictions. Feature influence can be direct (a direct influence on model outcomes) and indirect (model outcomes are influenced via proxy features). Feature influence can also be expressed in aggregate over the training or test data or locally with respect to a single point. Current research has typically focused on one of each of these dimensions. In this paper, we develop disentangled influence audits, a procedure to audit the indirect influence of features. Specifically, we show that disentangled representations provide a mechanism to identify proxy features in the dataset, while allowing an explicit computation of feature influence on either individual outcomes or aggregate-level outcomes. We show through both theory and experiments that disentangled influence audits can both detect proxy features and show, for each individual or in aggregate, which of these proxy features affects the classifier being audited the most. In this respect, our method is more powerful than existing methods for ascertaining feature influence.
Assessing the Local Interpretability of Machine Learning Models
Feb 09, 2019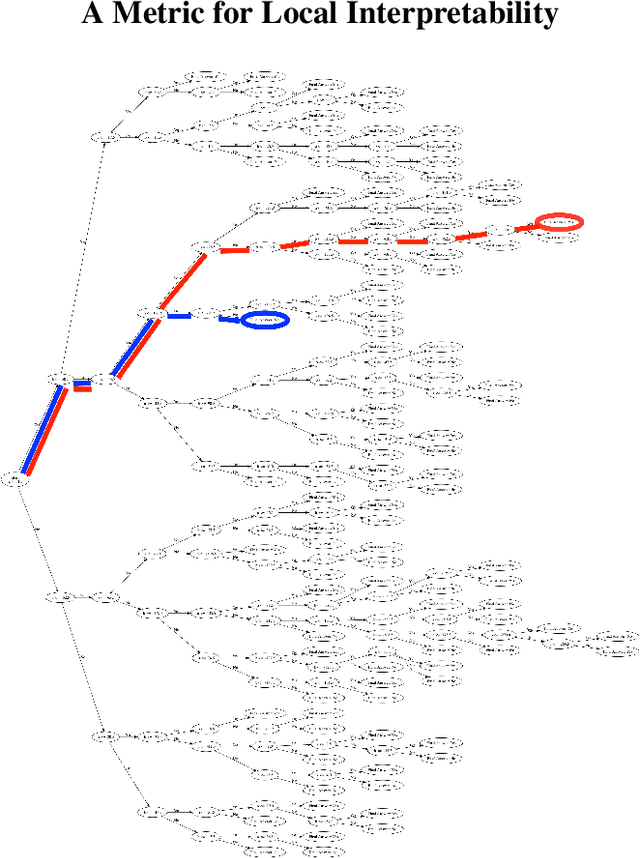
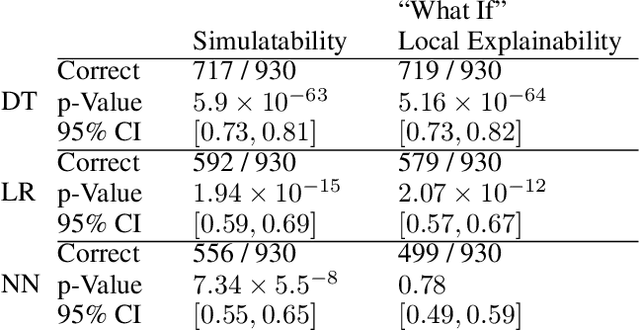


The increasing adoption of machine learning tools has led to calls for accountability via model interpretability. But what does it mean for a machine learning model to be interpretable by humans, and how can this be assessed? We focus on two definitions of interpretability that have been introduced in the machine learning literature: simulatability (a user's ability to run a model on a given input) and "what if" local explainability (a user's ability to correctly indicate the outcome to a model under local changes to the input). Through a user study with 1000 participants, we test whether humans perform well on tasks that mimic the definitions of simulatability and "what if" local explainability on models that are typically considered locally interpretable. We find evidence consistent with the common intuition that decision trees and logistic regression models are interpretable and are more interpretable than neural networks. We propose a metric - the runtime operation count on the simulatability task - to indicate the relative interpretability of models and show that as the number of operations increases the users' accuracy on the local interpretability tasks decreases.
Fairness in representation: quantifying stereotyping as a representational harm
Jan 28, 2019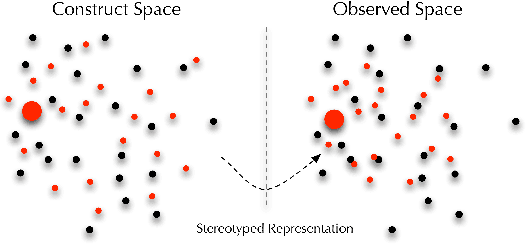
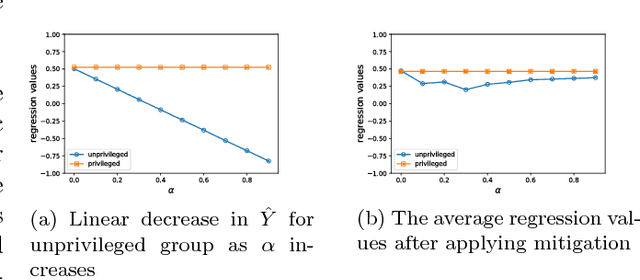
While harms of allocation have been increasingly studied as part of the subfield of algorithmic fairness, harms of representation have received considerably less attention. In this paper, we formalize two notions of stereotyping and show how they manifest in later allocative harms within the machine learning pipeline. We also propose mitigation strategies and demonstrate their effectiveness on synthetic datasets.
Interpretable Active Learning
Jun 24, 2018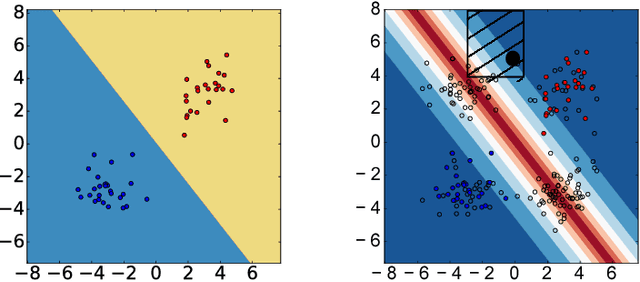
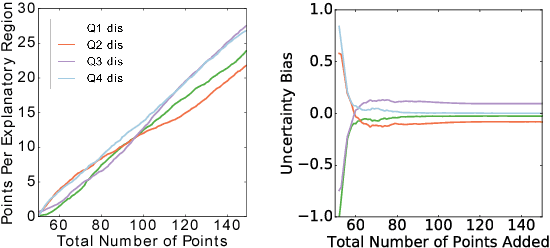
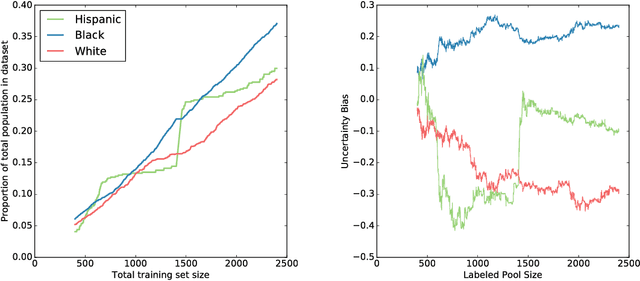
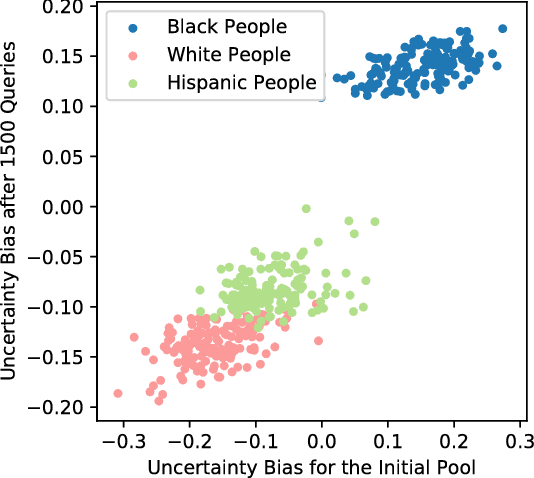
Active learning has long been a topic of study in machine learning. However, as increasingly complex and opaque models have become standard practice, the process of active learning, too, has become more opaque. There has been little investigation into interpreting what specific trends and patterns an active learning strategy may be exploring. This work expands on the Local Interpretable Model-agnostic Explanations framework (LIME) to provide explanations for active learning recommendations. We demonstrate how LIME can be used to generate locally faithful explanations for an active learning strategy, and how these explanations can be used to understand how different models and datasets explore a problem space over time. In order to quantify the per-subgroup differences in how an active learning strategy queries spatial regions, we introduce a notion of uncertainty bias (based on disparate impact) to measure the discrepancy in the confidence for a model's predictions between one subgroup and another. Using the uncertainty bias measure, we show that our query explanations accurately reflect the subgroup focus of the active learning queries, allowing for an interpretable explanation of what is being learned as points with similar sources of uncertainty have their uncertainty bias resolved. We demonstrate that this technique can be applied to track uncertainty bias over user-defined clusters or automatically generated clusters based on the source of uncertainty.
A comparative study of fairness-enhancing interventions in machine learning
Feb 13, 2018
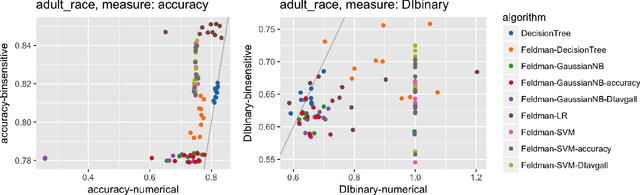
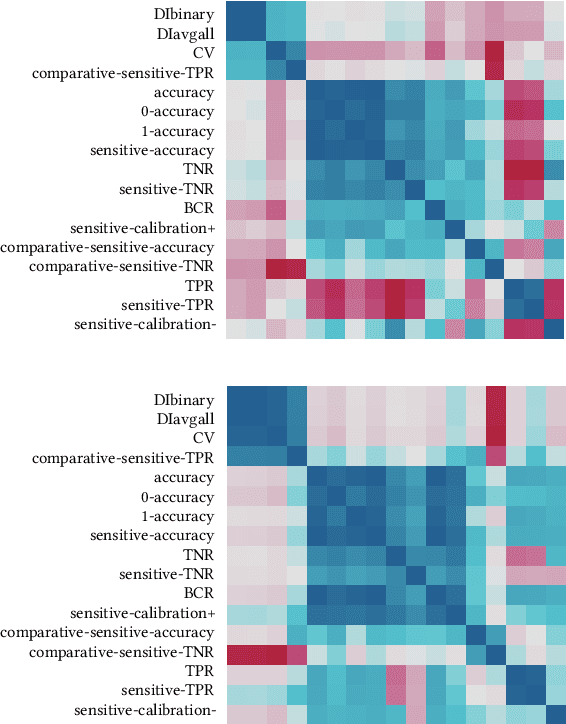
Computers are increasingly used to make decisions that have significant impact in people's lives. Often, these predictions can affect different population subgroups disproportionately. As a result, the issue of fairness has received much recent interest, and a number of fairness-enhanced classifiers and predictors have appeared in the literature. This paper seeks to study the following questions: how do these different techniques fundamentally compare to one another, and what accounts for the differences? Specifically, we seek to bring attention to many under-appreciated aspects of such fairness-enhancing interventions. Concretely, we present the results of an open benchmark we have developed that lets us compare a number of different algorithms under a variety of fairness measures, and a large number of existing datasets. We find that although different algorithms tend to prefer specific formulations of fairness preservations, many of these measures strongly correlate with one another. In addition, we find that fairness-preserving algorithms tend to be sensitive to fluctuations in dataset composition (simulated in our benchmark by varying training-test splits), indicating that fairness interventions might be more brittle than previously thought.
Runaway Feedback Loops in Predictive Policing
Dec 22, 2017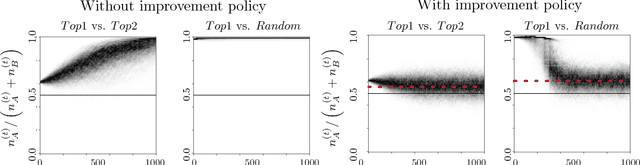
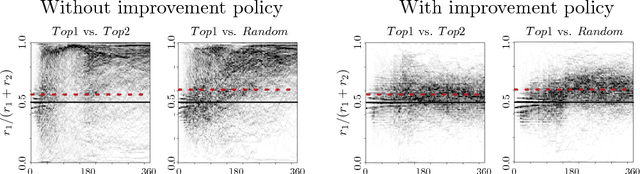
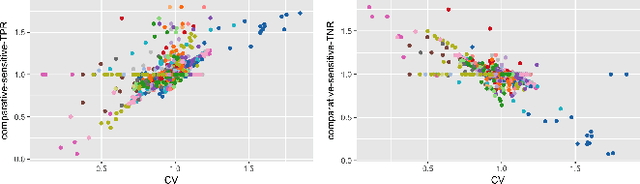
Predictive policing systems are increasingly used to determine how to allocate police across a city in order to best prevent crime. Discovered crime data (e.g., arrest counts) are used to help update the model, and the process is repeated. Such systems have been empirically shown to be susceptible to runaway feedback loops, where police are repeatedly sent back to the same neighborhoods regardless of the true crime rate. In response, we develop a mathematical model of predictive policing that proves why this feedback loop occurs, show empirically that this model exhibits such problems, and demonstrate how to change the inputs to a predictive policing system (in a black-box manner) so the runaway feedback loop does not occur, allowing the true crime rate to be learned. Our results are quantitative: we can establish a link (in our model) between the degree to which runaway feedback causes problems and the disparity in crime rates between areas. Moreover, we can also demonstrate the way in which \emph{reported} incidents of crime (those reported by residents) and \emph{discovered} incidents of crime (i.e. those directly observed by police officers dispatched as a result of the predictive policing algorithm) interact: in brief, while reported incidents can attenuate the degree of runaway feedback, they cannot entirely remove it without the interventions we suggest.
Auditing Black-box Models for Indirect Influence
Nov 30, 2016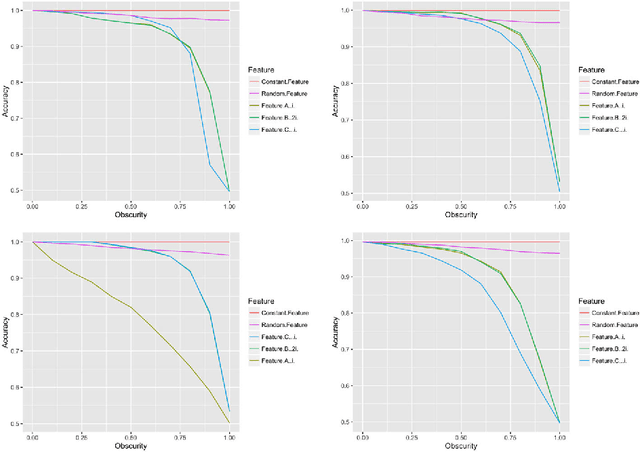
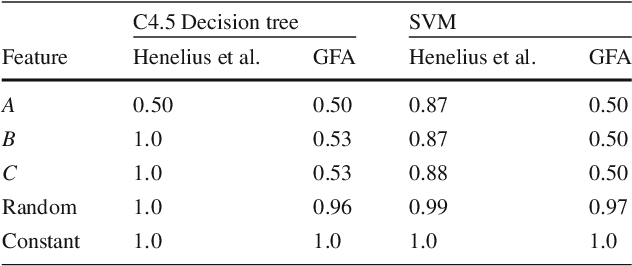
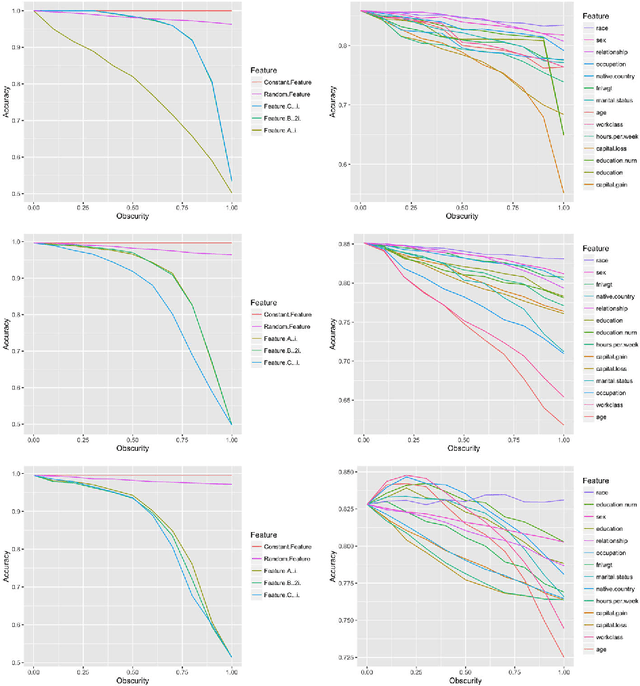
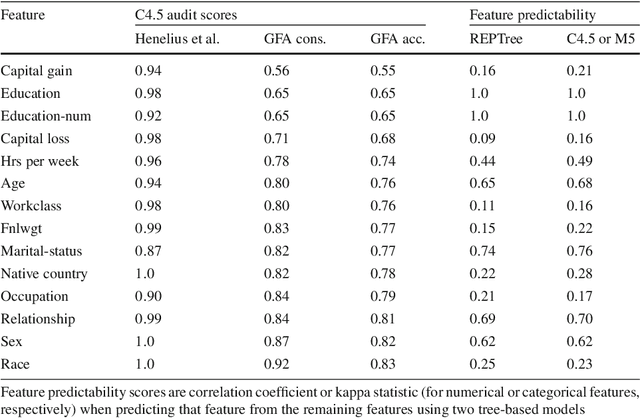
Data-trained predictive models see widespread use, but for the most part they are used as black boxes which output a prediction or score. It is therefore hard to acquire a deeper understanding of model behavior, and in particular how different features influence the model prediction. This is important when interpreting the behavior of complex models, or asserting that certain problematic attributes (like race or gender) are not unduly influencing decisions. In this paper, we present a technique for auditing black-box models, which lets us study the extent to which existing models take advantage of particular features in the dataset, without knowing how the models work. Our work focuses on the problem of indirect influence: how some features might indirectly influence outcomes via other, related features. As a result, we can find attribute influences even in cases where, upon further direct examination of the model, the attribute is not referred to by the model at all. Our approach does not require the black-box model to be retrained. This is important if (for example) the model is only accessible via an API, and contrasts our work with other methods that investigate feature influence like feature selection. We present experimental evidence for the effectiveness of our procedure using a variety of publicly available datasets and models. We also validate our procedure using techniques from interpretable learning and feature selection, as well as against other black-box auditing procedures.