 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne for One, or All for All: Equilibria and Optimality of Collaboration in Federated Learning
Mar 04, 2021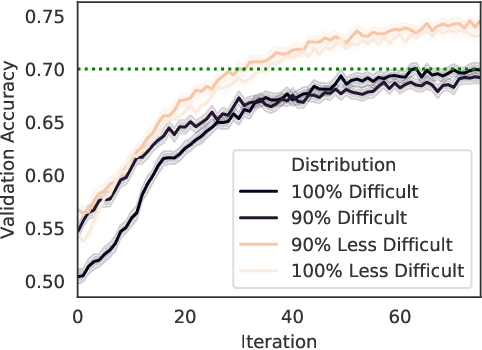
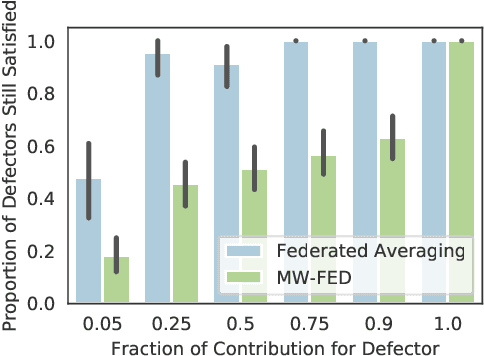
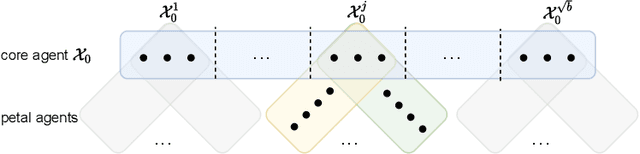
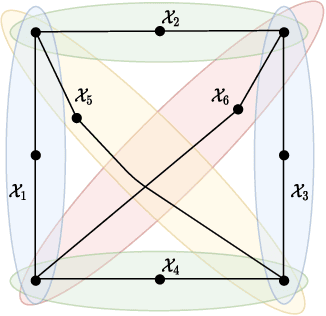
In recent years, federated learning has been embraced as an approach for bringing about collaboration across large populations of learning agents. However, little is known about how collaboration protocols should take agents' incentives into account when allocating individual resources for communal learning in order to maintain such collaborations. Inspired by game theoretic notions, this paper introduces a framework for incentive-aware learning and data sharing in federated learning. Our stable and envy-free equilibria capture notions of collaboration in the presence of agents interested in meeting their learning objectives while keeping their own sample collection burden low. For example, in an envy-free equilibrium, no agent would wish to swap their sampling burden with any other agent and in a stable equilibrium, no agent would wish to unilaterally reduce their sampling burden. In addition to formalizing this framework, our contributions include characterizing the structural properties of such equilibria, proving when they exist, and showing how they can be computed. Furthermore, we compare the sample complexity of incentive-aware collaboration with that of optimal collaboration when one ignores agents' incentives.
WILDS: A Benchmark of in-the-Wild Distribution Shifts
Dec 14, 2020
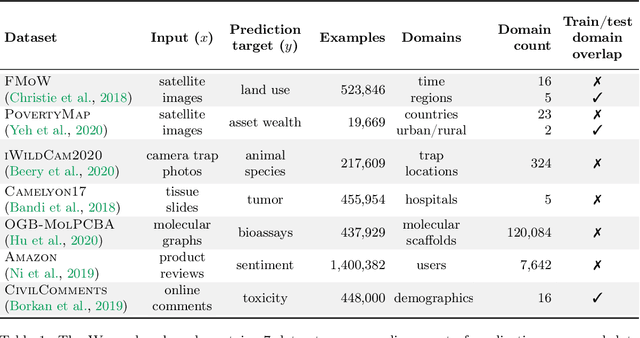

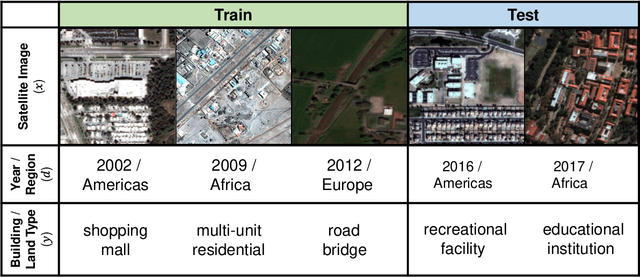
Distribution shifts can cause significant degradation in a broad range of machine learning (ML) systems deployed in the wild. However, many widely-used datasets in the ML community today were not designed for evaluating distribution shifts. These datasets typically have training and test sets drawn from the same distribution, and prior work on retrofitting them with distribution shifts has generally relied on artificial shifts that need not represent the kinds of shifts encountered in the wild. In this paper, we present WILDS, a benchmark of in-the-wild distribution shifts spanning diverse data modalities and applications, from tumor identification to wildlife monitoring to poverty mapping. WILDS builds on top of recent data collection efforts by domain experts in these applications and provides a unified collection of datasets with evaluation metrics and train/test splits that are representative of real-world distribution shifts. These datasets reflect distribution shifts arising from training and testing on different hospitals, cameras, countries, time periods, demographics, molecular scaffolds, etc., all of which cause substantial performance drops in our baseline models. Finally, we survey other applications that would be promising additions to the benchmark but for which we did not manage to find appropriate datasets; we discuss their associated challenges and detail datasets and shifts where we did not see an appreciable performance drop. By unifying datasets from a variety of application areas and making them accessible to the ML community, we hope to encourage the development of general-purpose methods that are anchored to real-world distribution shifts and that work well across different applications and problem settings. Data loaders, default models, and leaderboards are available at https://wilds.stanford.edu.
Disentangling Influence: Using Disentangled Representations to Audit Model Predictions
Jun 20, 2019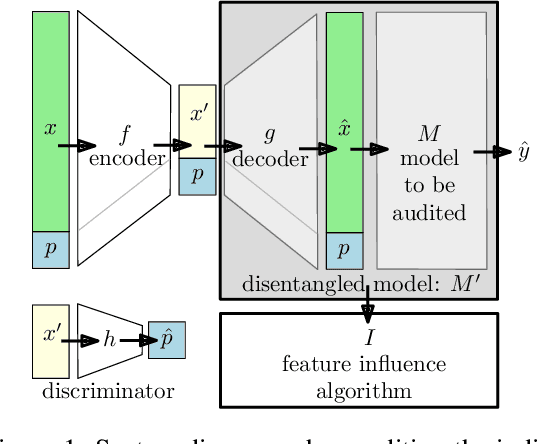
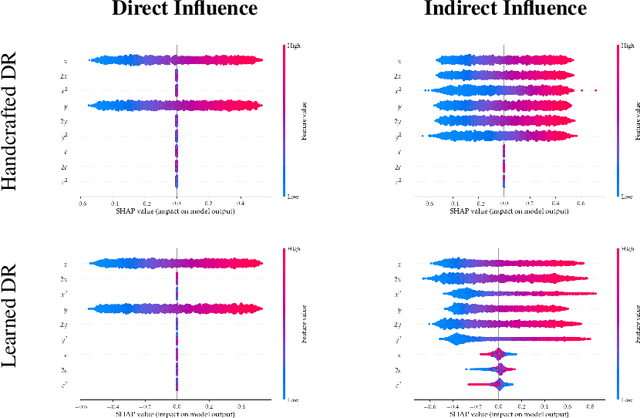
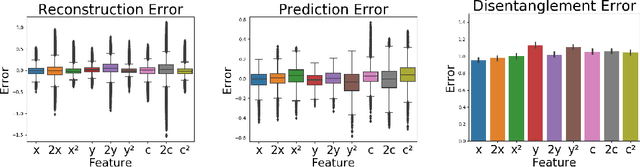
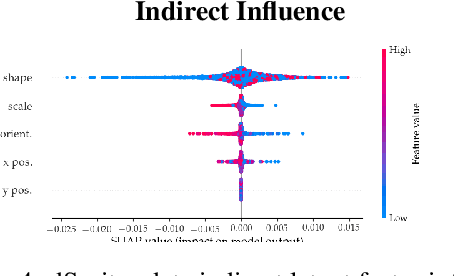
Motivated by the need to audit complex and black box models, there has been extensive research on quantifying how data features influence model predictions. Feature influence can be direct (a direct influence on model outcomes) and indirect (model outcomes are influenced via proxy features). Feature influence can also be expressed in aggregate over the training or test data or locally with respect to a single point. Current research has typically focused on one of each of these dimensions. In this paper, we develop disentangled influence audits, a procedure to audit the indirect influence of features. Specifically, we show that disentangled representations provide a mechanism to identify proxy features in the dataset, while allowing an explicit computation of feature influence on either individual outcomes or aggregate-level outcomes. We show through both theory and experiments that disentangled influence audits can both detect proxy features and show, for each individual or in aggregate, which of these proxy features affects the classifier being audited the most. In this respect, our method is more powerful than existing methods for ascertaining feature influence.