 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScale-Sensitive Shattering: Learnability and Evaluability at Optimal Scale
May 13, 2026We study the optimal scale at which real-valued function classes exhibit uniform convergence and learnability. Our main result establishes a scale-sensitive generalization of the fundamental theorem of PAC learning: for every bounded real-valued class and every $γ>0$, uniform convergence at scale $γ$, agnostic learnability at scale $γ/2$, and finiteness of the fat-shattering dimension at every scale $γ'>γ$ are equivalent. This resolves a question by Anthony and Bartlett (Cambridge Univ. Press 1999) on the precise scales governing learnability, refuting a conjecture attributed there to Phil Long that a multiplicative 2-factor gap is unavoidable, and improves the upper bounds of Bartlett and Long (JCSS 1998), which incur such a loss. The key technical ingredient is a direct bound on empirical $\ell_\infty$ covering numbers, avoiding the standard detour through packing numbers. As a consequence, we obtain sharp asymptotic metric-entropy bounds in terms of the fat-shattering scale $γ$: an $O(\log^2 n)$ bound holds already at scale $γ/2$, while an $O(\log n)$ bound holds at scale $2γ$. We further show that the $O(\log^2 n)$ bound is sometimes tight. These results resolve open questions by Alon et al. (JACM 1997) and Rudelson and Vershynin (Ann. of Math. 2006). As an application, we establish a sharp dichotomy for bounded integral probability metrics: every such IPM is either estimable or cannot be weakly evaluated within any multiplicative factor $c<3$, while $3$-weak evaluability always holds, resolving an open question from Aiyer et al. (ICML 2026). We also highlight several open questions on quantitative sample complexity and evaluability.
Online Set Learning from Precision and Recall Feedback
May 10, 2026We consider the problem of learning an unknown subset $N_\text{target}$ of a domain in an online setting. In each round $t$, the learner predicts a set of items ${N}_t$ and receives one of two types of feedback, each with equal probability: precision feedback, in which a randomly chosen item from the predicted set $N_t$ is revealed and the learner is told whether it belongs to $N_\text{target}$ (incurring a reward if it does), or recall feedback, in which a randomly chosen item from the target set $N_\text{target}$ is revealed and the learner is told whether it belongs to $N_t$ (incurring a reward if it does). The goal is to maximize the cumulative reward over time. This simple online set learning problem abstracts a variety of learning scenarios with precision- and recall-type feedback. We show that a hypothesis class (a family of subsets of the domain) is learnable in this setting if and only if it has finite Vapnik-Chervonenkis (VC) dimension, mirroring the classical PAC characterization. However, the resulting algorithmic structure is markedly more intricate: in contrast to standard Probably Approximately Correct (PAC) learning -- where the algorithmic landscape is governed by the simple principle of Empirical Risk Minimization (ERM) -- our partial feedback model can invalidate ERM and even all proper learning rules. We develop algorithms to address the dependencies induced by the feedback, obtaining regret guarantees in both the realizable and agnostic settings. Our results provide a qualitative characterization of learnability in this model, addressing its most basic question, while pointing to a range of natural and intriguing open questions, including the determination of optimal regret rates.
A Theoretical Framework for Statistical Evaluability of Generative Models
Apr 07, 2026Statistical evaluation aims to estimate the generalization performance of a model using held-out i.i.d.\ test data sampled from the ground-truth distribution. In supervised learning settings such as classification, performance metrics such as error rate are well-defined, and test error reliably approximates population error given sufficiently large datasets. In contrast, evaluation is more challenging for generative models due to their open-ended nature: it is unclear which metrics are appropriate and whether such metrics can be reliably evaluated from finite samples. In this work, we introduce a theoretical framework for evaluating generative models and establish evaluability results for commonly used metrics. We study two categories of metrics: test-based metrics, including integral probability metrics (IPMs), and Rényi divergences. We show that IPMs with respect to any bounded test class can be evaluated from finite samples up to multiplicative and additive approximation errors. Moreover, when the test class has finite fat-shattering dimension, IPMs can be evaluated with arbitrary precision. In contrast, Rényi and KL divergences are not evaluable from finite samples, as their values can be critically determined by rare events. We also analyze the potential and limitations of perplexity as an evaluation method.
Equitable Evaluation via Elicitation
Feb 24, 2026Individuals with similar qualifications and skills may vary in their demeanor, or outward manner: some tend toward self-promotion while others are modest to the point of omitting crucial information. Comparing the self-descriptions of equally qualified job-seekers with different self-presentation styles is therefore problematic. We build an interactive AI for skill elicitation that provides accurate determination of skills while simultaneously allowing individuals to speak in their own voice. Such a system can be deployed, for example, when a new user joins a professional networking platform, or when matching employees to needs during a company reorganization. To obtain sufficient training data, we train an LLM to act as synthetic humans. Elicitation mitigates endogenous bias arising from individuals' own self-reports. To address systematic model bias we enforce a mathematically rigorous notion of equitability ensuring that the covariance between self-presentation manner and skill evaluation error is small.
On Randomized Algorithms in Online Strategic Classification
Feb 05, 2026Online strategic classification studies settings in which agents strategically modify their features to obtain favorable predictions. For example, given a classifier that determines loan approval based on credit scores, applicants may open or close credit cards and bank accounts to obtain a positive prediction. The learning goal is to achieve low mistake or regret bounds despite such strategic behavior. While randomized algorithms have the potential to offer advantages to the learner in strategic settings, they have been largely underexplored. In the realizable setting, no lower bound is known for randomized algorithms, and existing lower bound constructions for deterministic learners can be circumvented by randomization. In the agnostic setting, the best known regret upper bound is $O(T^{3/4}\log^{1/4}T|\mathcal H|)$, which is far from the standard online learning rate of $O(\sqrt{T\log|\mathcal H|})$. In this work, we provide refined bounds for online strategic classification in both settings. In the realizable setting, we extend, for $T > \mathrm{Ldim}(\mathcal{H}) Δ^2$, the existing lower bound $Ω(\mathrm{Ldim}(\mathcal{H}) Δ)$ for deterministic learners to all learners. This yields the first lower bound that applies to randomized learners. We also provide the first randomized learner that improves the known (deterministic) upper bound of $O(\mathrm{Ldim}(\mathcal H) \cdot Δ\log Δ)$. In the agnostic setting, we give a proper learner using convex optimization techniques to improve the regret upper bound to $O(\sqrt{T \log |\mathcal{H}|} + |\mathcal{H}| \log(T|\mathcal{H}|))$. We show a matching lower bound up to logarithmic factors for all proper learning rules, demonstrating the optimality of our learner among proper learners. As such, improper learning is necessary to further improve regret guarantees.
Probably Approximately Precision and Recall Learning
Nov 20, 2024


Precision and Recall are foundational metrics in machine learning where both accurate predictions and comprehensive coverage are essential, such as in recommender systems and multi-label learning. In these tasks, balancing precision (the proportion of relevant items among those predicted) and recall (the proportion of relevant items successfully predicted) is crucial. A key challenge is that one-sided feedback--where only positive examples are observed during training--is inherent in many practical problems. For instance, in recommender systems like YouTube, training data only consists of videos that a user has actively selected, while unselected items remain unseen. Despite this lack of negative feedback in training, avoiding undesirable recommendations at test time is essential. We introduce a PAC learning framework where each hypothesis is represented by a graph, with edges indicating positive interactions, such as between users and items. This framework subsumes the classical binary and multi-class PAC learning models as well as multi-label learning with partial feedback, where only a single random correct label per example is observed, rather than all correct labels. Our work uncovers a rich statistical and algorithmic landscape, with nuanced boundaries on what can and cannot be learned. Notably, classical methods like Empirical Risk Minimization fail in this setting, even for simple hypothesis classes with only two hypotheses. To address these challenges, we develop novel algorithms that learn exclusively from positive data, effectively minimizing both precision and recall losses. Specifically, in the realizable setting, we design algorithms that achieve optimal sample complexity guarantees. In the agnostic case, we show that it is impossible to achieve additive error guarantees--as is standard in PAC learning--and instead obtain meaningful multiplicative approximations.
Transformation-Invariant Learning and Theoretical Guarantees for OOD Generalization
Oct 30, 2024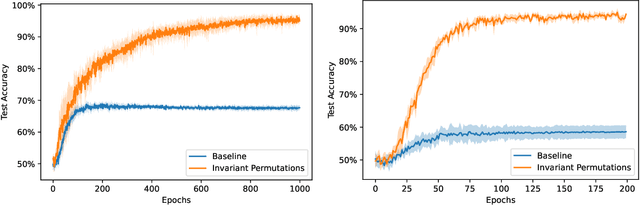
Learning with identical train and test distributions has been extensively investigated both practically and theoretically. Much remains to be understood, however, in statistical learning under distribution shifts. This paper focuses on a distribution shift setting where train and test distributions can be related by classes of (data) transformation maps. We initiate a theoretical study for this framework, investigating learning scenarios where the target class of transformations is either known or unknown. We establish learning rules and algorithmic reductions to Empirical Risk Minimization (ERM), accompanied with learning guarantees. We obtain upper bounds on the sample complexity in terms of the VC dimension of the class composing predictors with transformations, which we show in many cases is not much larger than the VC dimension of the class of predictors. We highlight that the learning rules we derive offer a game-theoretic viewpoint on distribution shift: a learner searching for predictors and an adversary searching for transformation maps to respectively minimize and maximize the worst-case loss.
Trustworthy Machine Learning under Social and Adversarial Data Sources
Aug 02, 2024Machine learning has witnessed remarkable breakthroughs in recent years. As machine learning permeates various aspects of daily life, individuals and organizations increasingly interact with these systems, exhibiting a wide range of social and adversarial behaviors. These behaviors may have a notable impact on the behavior and performance of machine learning systems. Specifically, during these interactions, data may be generated by strategic individuals, collected by self-interested data collectors, possibly poisoned by adversarial attackers, and used to create predictors, models, and policies satisfying multiple objectives. As a result, the machine learning systems' outputs might degrade, such as the susceptibility of deep neural networks to adversarial examples (Shafahi et al., 2018; Szegedy et al., 2013) and the diminished performance of classic algorithms in the presence of strategic individuals (Ahmadi et al., 2021). Addressing these challenges is imperative for the success of machine learning in societal settings.
Learnability Gaps of Strategic Classification
Feb 29, 2024In contrast with standard classification tasks, strategic classification involves agents strategically modifying their features in an effort to receive favorable predictions. For instance, given a classifier determining loan approval based on credit scores, applicants may open or close their credit cards to fool the classifier. The learning goal is to find a classifier robust against strategic manipulations. Various settings, based on what and when information is known, have been explored in strategic classification. In this work, we focus on addressing a fundamental question: the learnability gaps between strategic classification and standard learning. We essentially show that any learnable class is also strategically learnable: we first consider a fully informative setting, where the manipulation structure (which is modeled by a manipulation graph $G^\star$) is known and during training time the learner has access to both the pre-manipulation data and post-manipulation data. We provide nearly tight sample complexity and regret bounds, offering significant improvements over prior results. Then, we relax the fully informative setting by introducing two natural types of uncertainty. First, following Ahmadi et al. (2023), we consider the setting in which the learner only has access to the post-manipulation data. We improve the results of Ahmadi et al. (2023) and close the gap between mistake upper bound and lower bound raised by them. Our second relaxation of the fully informative setting introduces uncertainty to the manipulation structure. That is, we assume that the manipulation graph is unknown but belongs to a known class of graphs. We provide nearly tight bounds on the learning complexity in various unknown manipulation graph settings. Notably, our algorithm in this setting is of independent interest and can be applied to other problems such as multi-label learning.
On the Effect of Defections in Federated Learning and How to Prevent Them
Nov 28, 2023Federated learning is a machine learning protocol that enables a large population of agents to collaborate over multiple rounds to produce a single consensus model. There are several federated learning applications where agents may choose to defect permanently$-$essentially withdrawing from the collaboration$-$if they are content with their instantaneous model in that round. This work demonstrates the detrimental impact of such defections on the final model's robustness and ability to generalize. We also show that current federated optimization algorithms fail to disincentivize these harmful defections. We introduce a novel optimization algorithm with theoretical guarantees to prevent defections while ensuring asymptotic convergence to an effective solution for all participating agents. We also provide numerical experiments to corroborate our findings and demonstrate the effectiveness of our algorithm.