 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiPOD: Diffusion Policy Optimization without Drifting Apart
Jun 17, 2026RL post-training has become increasingly pivotal for improving diffusion policies, but existing diffusion policy-gradient methods are often unstable and cannot achieve reliable policy improvement. We identify the cause as the double-drift phenomenon: optimizing a variational surrogate can let the ELBO separate from the true log-likelihood, which then makes the resulting proxy policy gradient misaligned with the true policy gradient of expected return. We propose \textbf{DiPOD}, a diffusion policy optimization framework that maintains tight-bound behavior throughout training by interleaving self-distillation with policy-improving gradient updates. This leads to a simple and practical algorithm: augmenting each diffusion policy-gradient update with an on-policy ELBO regularizer. Across diffusion language model post-training and continuous-control diffusion policies, DiPOD substantially stabilizes training and reaches higher rewards than previous methods.
Strategic Feature Selection
Jun 17, 2026When algorithmic predictors inform resource allocation in high-stakes domains such as healthcare, these predictors must account for strategic manipulation of input features. The typical solution is to redesign the predictor itself to explicitly account for strategic interactions. In practice, however, decision makers are often constrained to adjusting coarser levers within existing prediction pipelines. For example, healthcare organizations often select which features to exclude based on perceived manipulability, while using standard regularization procedures to shrink the coefficients of retained features. In this work, we initiate a formal study of strategic classification through feature selection and its interaction with ridge regularization. Our main finding is that excluding individual features based on their manipulability alone is generally suboptimal. We provide a fine-grained characterization of the performance of a feature subset under optimal regularization, yielding new insights for policy design. Motivated by this characterization, we develop a practical algorithm for jointly choosing the feature set and the level of ridge regularization. Through a real-world case study on a healthcare payments benchmark, we illustrate how our algorithm can guide the design of coarse policy levers in practice. Our results provide a principled, practical framework for mitigating the effects of strategic behavior in algorithmic decision-making systems.
Diffusion Policy Optimization without Drifting Apart
Jun 11, 2026RL post-training has become increasingly pivotal for improving diffusion policies, but existing diffusion policy-gradient methods are often unstable and cannot achieve reliable policy improvement. We identify the cause as the double-drift phenomenon: optimizing a variational surrogate can let the ELBO separate from the true log-likelihood, which then makes the resulting proxy policy gradient misaligned with the true policy gradient of expected return. We propose \textbf{DiPOD}, a diffusion policy optimization framework that maintains tight-bound behavior throughout training by interleaving self-distillation with policy-improving gradient updates. This leads to a simple and practical algorithm: augmenting each diffusion policy-gradient update with an on-policy ELBO regularizer. Across diffusion language model post-training and continuous-control diffusion policies, DiPOD substantially stabilizes training and reaches higher rewards than previous methods.
Subliminal Effects in Your Data: A General Mechanism via Log-Linearity
Feb 04, 2026Training modern large language models (LLMs) has become a veritable smorgasbord of algorithms and datasets designed to elicit particular behaviors, making it critical to develop techniques to understand the effects of datasets on the model's properties. This is exacerbated by recent experiments that show datasets can transmit signals that are not directly observable from individual datapoints, posing a conceptual challenge for dataset-centric understandings of LLM training and suggesting a missing fundamental account of such phenomena. Towards understanding such effects, inspired by recent work on the linear structure of LLMs, we uncover a general mechanism through which hidden subtexts can arise in generic datasets. We introduce Logit-Linear-Selection (LLS), a method that prescribes how to select subsets of a generic preference dataset to elicit a wide range of hidden effects. We apply LLS to discover subsets of real-world datasets so that models trained on them exhibit behaviors ranging from having specific preferences, to responding to prompts in a different language not present in the dataset, to taking on a different persona. Crucially, the effect persists for the selected subset, across models with varying architectures, supporting its generality and universality.
Diffusion Language Models are Provably Optimal Parallel Samplers
Dec 31, 2025Diffusion language models (DLMs) have emerged as a promising alternative to autoregressive models for faster inference via parallel token generation. We provide a rigorous foundation for this advantage by formalizing a model of parallel sampling and showing that DLMs augmented with polynomial-length chain-of-thought (CoT) can simulate any parallel sampling algorithm using an optimal number of sequential steps. Consequently, whenever a target distribution can be generated using a small number of sequential steps, a DLM can be used to generate the distribution using the same number of optimal sequential steps. However, without the ability to modify previously revealed tokens, DLMs with CoT can still incur large intermediate footprints. We prove that enabling remasking (converting unmasked tokens to masks) or revision (converting unmasked tokens to other unmasked tokens) together with CoT further allows DLMs to simulate any parallel sampling algorithm with optimal space complexity. We further justify the advantage of revision by establishing a strict expressivity gap: DLMs with revision or remasking are strictly more expressive than those without. Our results not only provide a theoretical justification for the promise of DLMs as the most efficient parallel sampler, but also advocate for enabling revision in DLMs.
Sample-Adaptivity Tradeoff in On-Demand Sampling
Nov 19, 2025We study the tradeoff between sample complexity and round complexity in on-demand sampling, where the learning algorithm adaptively samples from $k$ distributions over a limited number of rounds. In the realizable setting of Multi-Distribution Learning (MDL), we show that the optimal sample complexity of an $r$-round algorithm scales approximately as $dk^{Θ(1/r)} / ε$. For the general agnostic case, we present an algorithm that achieves near-optimal sample complexity of $\widetilde O((d + k) / ε^2)$ within $\widetilde O(\sqrt{k})$ rounds. Of independent interest, we introduce a new framework, Optimization via On-Demand Sampling (OODS), which abstracts the sample-adaptivity tradeoff and captures most existing MDL algorithms. We establish nearly tight bounds on the round complexity in the OODS setting. The upper bounds directly yield the $\widetilde O(\sqrt{k})$-round algorithm for agnostic MDL, while the lower bounds imply that achieving sub-polynomial round complexity would require fundamentally new techniques that bypass the inherent hardness of OODS.
Panprediction: Optimal Predictions for Any Downstream Task and Loss
Oct 31, 2025Supervised learning is classically formulated as training a model to minimize a fixed loss function over a fixed distribution, or task. However, an emerging paradigm instead views model training as extracting enough information from data so that the model can be used to minimize many losses on many downstream tasks. We formalize a mathematical framework for this paradigm, which we call panprediction, and study its statistical complexity. Formally, panprediction generalizes omniprediction and sits upstream from multi-group learning, which respectively focus on predictions that generalize to many downstream losses or many downstream tasks, but not both. Concretely, we design algorithms that learn deterministic and randomized panpredictors with $\tilde{O}(1/\varepsilon^3)$ and $\tilde{O}(1/\varepsilon^2)$ samples, respectively. Our results demonstrate that under mild assumptions, simultaneously minimizing infinitely many losses on infinitely many tasks can be as statistically easy as minimizing one loss on one task. Along the way, we improve the best known sample complexity guarantee of deterministic omniprediction by a factor of $1/\varepsilon$, and match all other known sample complexity guarantees of omniprediction and multi-group learning. Our key technical ingredient is a nearly lossless reduction from panprediction to a statistically efficient notion of calibration, called step calibration.
On Surjectivity of Neural Networks: Can you elicit any behavior from your model?
Aug 26, 2025
Given a trained neural network, can any specified output be generated by some input? Equivalently, does the network correspond to a function that is surjective? In generative models, surjectivity implies that any output, including harmful or undesirable content, can in principle be generated by the networks, raising concerns about model safety and jailbreak vulnerabilities. In this paper, we prove that many fundamental building blocks of modern neural architectures, such as networks with pre-layer normalization and linear-attention modules, are almost always surjective. As corollaries, widely used generative frameworks, including GPT-style transformers and diffusion models with deterministic ODE solvers, admit inverse mappings for arbitrary outputs. By studying surjectivity of these modern and commonly used neural architectures, we contribute a formalism that sheds light on their unavoidable vulnerability to a broad class of adversarial attacks.
Distortion of AI Alignment: Does Preference Optimization Optimize for Preferences?
May 29, 2025



After pre-training, large language models are aligned with human preferences based on pairwise comparisons. State-of-the-art alignment methods (such as PPO-based RLHF and DPO) are built on the assumption of aligning with a single preference model, despite being deployed in settings where users have diverse preferences. As a result, it is not even clear that these alignment methods produce models that satisfy users on average -- a minimal requirement for pluralistic alignment. Drawing on social choice theory and modeling users' comparisons through individual Bradley-Terry (BT) models, we introduce an alignment method's distortion: the worst-case ratio between the optimal achievable average utility, and the average utility of the learned policy. The notion of distortion helps draw sharp distinctions between alignment methods: Nash Learning from Human Feedback achieves the minimax optimal distortion of $(\frac{1}{2} + o(1)) \cdot \beta$ (for the BT temperature $\beta$), robustly across utility distributions, distributions of comparison pairs, and permissible KL divergences from the reference policy. RLHF and DPO, by contrast, suffer $\geq (1 - o(1)) \cdot \beta$ distortion already without a KL constraint, and $e^{\Omega(\beta)}$ or even unbounded distortion in the full setting, depending on how comparison pairs are sampled.
From Style to Facts: Mapping the Boundaries of Knowledge Injection with Finetuning
Mar 07, 2025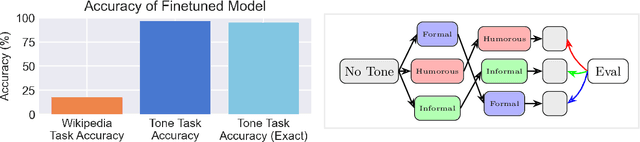
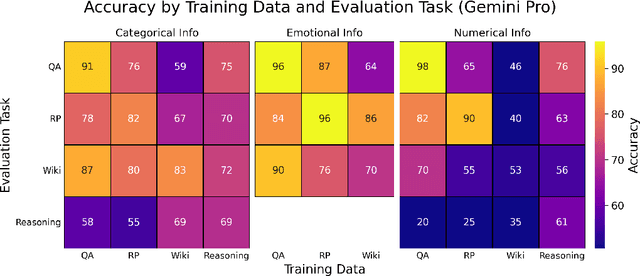
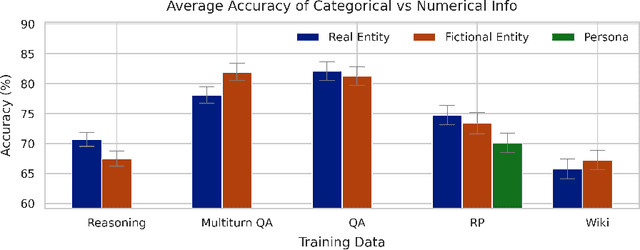
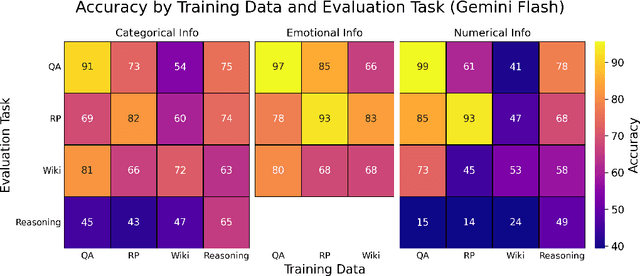
Finetuning provides a scalable and cost-effective means of customizing language models for specific tasks or response styles, with greater reliability than prompting or in-context learning. In contrast, the conventional wisdom is that injecting knowledge via finetuning results in brittle performance and poor generalization. We argue that the dichotomy of "task customization" (e.g., instruction tuning) and "knowledge injection" (e.g., teaching new facts) is a distinction without a difference. We instead identify concrete factors that explain the heterogeneous effectiveness observed with finetuning. To this end, we conduct a large-scale experimental study of finetuning the frontier Gemini v1.5 model family on a spectrum of datasets that are artificially engineered to interpolate between the strengths and failure modes of finetuning. Our findings indicate that question-answer training data formats provide much stronger knowledge generalization than document/article-style training data, numerical information can be harder for finetuning to retain than categorical information, and models struggle to apply finetuned knowledge during multi-step reasoning even when trained on similar examples -- all factors that render "knowledge injection" to be especially difficult, even after controlling for considerations like data augmentation and information volume. On the other hand, our findings also indicate that it is not fundamentally more difficult to finetune information about a real-world event than information about what a model's writing style should be.