 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSample-Adaptivity Tradeoff in On-Demand Sampling
Nov 19, 2025We study the tradeoff between sample complexity and round complexity in on-demand sampling, where the learning algorithm adaptively samples from $k$ distributions over a limited number of rounds. In the realizable setting of Multi-Distribution Learning (MDL), we show that the optimal sample complexity of an $r$-round algorithm scales approximately as $dk^{Θ(1/r)} / ε$. For the general agnostic case, we present an algorithm that achieves near-optimal sample complexity of $\widetilde O((d + k) / ε^2)$ within $\widetilde O(\sqrt{k})$ rounds. Of independent interest, we introduce a new framework, Optimization via On-Demand Sampling (OODS), which abstracts the sample-adaptivity tradeoff and captures most existing MDL algorithms. We establish nearly tight bounds on the round complexity in the OODS setting. The upper bounds directly yield the $\widetilde O(\sqrt{k})$-round algorithm for agnostic MDL, while the lower bounds imply that achieving sub-polynomial round complexity would require fundamentally new techniques that bypass the inherent hardness of OODS.
Truthfulness of Decision-Theoretic Calibration Measures
Mar 04, 2025Calibration measures quantify how much a forecaster's predictions violates calibration, which requires that forecasts are unbiased conditioning on the forecasted probabilities. Two important desiderata for a calibration measure are its decision-theoretic implications (i.e., downstream decision-makers that best-respond to the forecasts are always no-regret) and its truthfulness (i.e., a forecaster approximately minimizes error by always reporting the true probabilities). Existing measures satisfy at most one of the properties, but not both. We introduce a new calibration measure termed subsampled step calibration, $\mathsf{StepCE}^{\textsf{sub}}$, that is both decision-theoretic and truthful. In particular, on any product distribution, $\mathsf{StepCE}^{\textsf{sub}}$ is truthful up to an $O(1)$ factor whereas prior decision-theoretic calibration measures suffer from an $e^{-\Omega(T)}$-$\Omega(\sqrt{T})$ truthfulness gap. Moreover, in any smoothed setting where the conditional probability of each event is perturbed by a noise of magnitude $c > 0$, $\mathsf{StepCE}^{\textsf{sub}}$ is truthful up to an $O(\sqrt{\log(1/c)})$ factor, while prior decision-theoretic measures have an $e^{-\Omega(T)}$-$\Omega(T^{1/3})$ truthfulness gap. We also prove a general impossibility result for truthful decision-theoretic forecasting: any complete and decision-theoretic calibration measure must be discontinuous and non-truthful in the non-smoothed setting.
Truthfulness of Calibration Measures
Jul 19, 2024We initiate the study of the truthfulness of calibration measures in sequential prediction. A calibration measure is said to be truthful if the forecaster (approximately) minimizes the expected penalty by predicting the conditional expectation of the next outcome, given the prior distribution of outcomes. Truthfulness is an important property of calibration measures, ensuring that the forecaster is not incentivized to exploit the system with deliberate poor forecasts. This makes it an essential desideratum for calibration measures, alongside typical requirements, such as soundness and completeness. We conduct a taxonomy of existing calibration measures and their truthfulness. Perhaps surprisingly, we find that all of them are far from being truthful. That is, under existing calibration measures, there are simple distributions on which a polylogarithmic (or even zero) penalty is achievable, while truthful prediction leads to a polynomial penalty. Our main contribution is the introduction of a new calibration measure termed the Subsampled Smooth Calibration Error (SSCE) under which truthful prediction is optimal up to a constant multiplicative factor.
Collaborative Learning with Different Labeling Functions
Feb 20, 2024We study a variant of Collaborative PAC Learning, in which we aim to learn an accurate classifier for each of the $n$ data distributions, while minimizing the number of samples drawn from them in total. Unlike in the usual collaborative learning setup, it is not assumed that there exists a single classifier that is simultaneously accurate for all distributions. We show that, when the data distributions satisfy a weaker realizability assumption, sample-efficient learning is still feasible. We give a learning algorithm based on Empirical Risk Minimization (ERM) on a natural augmentation of the hypothesis class, and the analysis relies on an upper bound on the VC dimension of this augmented class. In terms of the computational efficiency, we show that ERM on the augmented hypothesis class is NP-hard, which gives evidence against the existence of computationally efficient learners in general. On the positive side, for two special cases, we give learners that are both sample- and computationally-efficient.
On the Distance from Calibration in Sequential Prediction
Feb 12, 2024We study a sequential binary prediction setting where the forecaster is evaluated in terms of the calibration distance, which is defined as the $L_1$ distance between the predicted values and the set of predictions that are perfectly calibrated in hindsight. This is analogous to a calibration measure recently proposed by B{\l}asiok, Gopalan, Hu and Nakkiran (STOC 2023) for the offline setting. The calibration distance is a natural and intuitive measure of deviation from perfect calibration, and satisfies a Lipschitz continuity property which does not hold for many popular calibration measures, such as the $L_1$ calibration error and its variants. We prove that there is a forecasting algorithm that achieves an $O(\sqrt{T})$ calibration distance in expectation on an adversarially chosen sequence of $T$ binary outcomes. At the core of this upper bound is a structural result showing that the calibration distance is accurately approximated by the lower calibration distance, which is a continuous relaxation of the former. We then show that an $O(\sqrt{T})$ lower calibration distance can be achieved via a simple minimax argument and a reduction to online learning on a Lipschitz class. On the lower bound side, an $\Omega(T^{1/3})$ calibration distance is shown to be unavoidable, even when the adversary outputs a sequence of independent random bits, and has an additional ability to early stop (i.e., to stop producing random bits and output the same bit in the remaining steps). Interestingly, without this early stopping, the forecaster can achieve a much smaller calibration distance of $\mathrm{polylog}(T)$.
A Combinatorial Approach to Robust PCA
Nov 28, 2023We study the problem of recovering Gaussian data under adversarial corruptions when the noises are low-rank and the corruptions are on the coordinate level. Concretely, we assume that the Gaussian noises lie in an unknown $k$-dimensional subspace $U \subseteq \mathbb{R}^d$, and $s$ randomly chosen coordinates of each data point fall into the control of an adversary. This setting models the scenario of learning from high-dimensional yet structured data that are transmitted through a highly-noisy channel, so that the data points are unlikely to be entirely clean. Our main result is an efficient algorithm that, when $ks^2 = O(d)$, recovers every single data point up to a nearly-optimal $\ell_1$ error of $\tilde O(ks/d)$ in expectation. At the core of our proof is a new analysis of the well-known Basis Pursuit (BP) method for recovering a sparse signal, which is known to succeed under additional assumptions (e.g., incoherence or the restricted isometry property) on the underlying subspace $U$. In contrast, we present a novel approach via studying a natural combinatorial problem and show that, over the randomness in the support of the sparse signal, a high-probability error bound is possible even if the subspace $U$ is arbitrary.
A Fourier Approach to Mixture Learning
Oct 06, 2022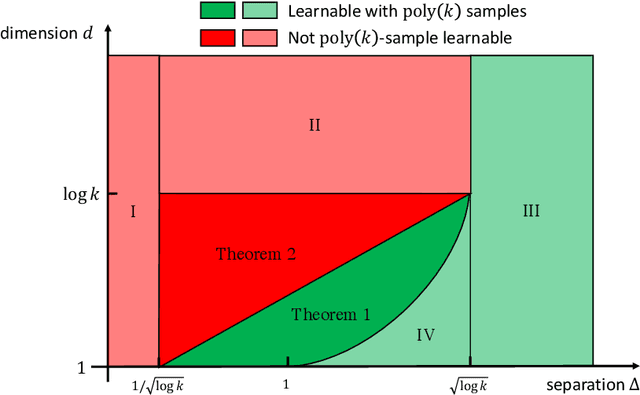

We revisit the problem of learning mixtures of spherical Gaussians. Given samples from mixture $\frac{1}{k}\sum_{j=1}^{k}\mathcal{N}(\mu_j, I_d)$, the goal is to estimate the means $\mu_1, \mu_2, \ldots, \mu_k \in \mathbb{R}^d$ up to a small error. The hardness of this learning problem can be measured by the separation $\Delta$ defined as the minimum distance between all pairs of means. Regev and Vijayaraghavan (2017) showed that with $\Delta = \Omega(\sqrt{\log k})$ separation, the means can be learned using $\mathrm{poly}(k, d)$ samples, whereas super-polynomially many samples are required if $\Delta = o(\sqrt{\log k})$ and $d = \Omega(\log k)$. This leaves open the low-dimensional regime where $d = o(\log k)$. In this work, we give an algorithm that efficiently learns the means in $d = O(\log k/\log\log k)$ dimensions under separation $d/\sqrt{\log k}$ (modulo doubly logarithmic factors). This separation is strictly smaller than $\sqrt{\log k}$, and is also shown to be necessary. Along with the results of Regev and Vijayaraghavan (2017), our work almost pins down the critical separation threshold at which efficient parameter learning becomes possible for spherical Gaussian mixtures. More generally, our algorithm runs in time $\mathrm{poly}(k)\cdot f(d, \Delta, \epsilon)$, and is thus fixed-parameter tractable in parameters $d$, $\Delta$ and $\epsilon$. Our approach is based on estimating the Fourier transform of the mixture at carefully chosen frequencies, and both the algorithm and its analysis are simple and elementary. Our positive results can be easily extended to learning mixtures of non-Gaussian distributions, under a mild condition on the Fourier spectrum of the distribution.
Open Problem: Properly learning decision trees in polynomial time?
Jun 29, 2022
The authors recently gave an $n^{O(\log\log n)}$ time membership query algorithm for properly learning decision trees under the uniform distribution (Blanc et al., 2021). The previous fastest algorithm for this problem ran in $n^{O(\log n)}$ time, a consequence of Ehrenfeucht and Haussler (1989)'s classic algorithm for the distribution-free setting. In this article we highlight the natural open problem of obtaining a polynomial-time algorithm, discuss possible avenues towards obtaining it, and state intermediate milestones that we believe are of independent interest.
Properly learning decision trees in almost polynomial time
Sep 01, 2021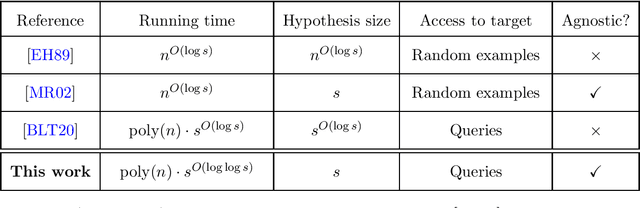


We give an $n^{O(\log\log n)}$-time membership query algorithm for properly and agnostically learning decision trees under the uniform distribution over $\{\pm 1\}^n$. Even in the realizable setting, the previous fastest runtime was $n^{O(\log n)}$, a consequence of a classic algorithm of Ehrenfeucht and Haussler. Our algorithm shares similarities with practical heuristics for learning decision trees, which we augment with additional ideas to circumvent known lower bounds against these heuristics. To analyze our algorithm, we prove a new structural result for decision trees that strengthens a theorem of O'Donnell, Saks, Schramm, and Servedio. While the OSSS theorem says that every decision tree has an influential variable, we show how every decision tree can be "pruned" so that every variable in the resulting tree is influential.
Decision tree heuristics can fail, even in the smoothed setting
Jul 02, 2021Greedy decision tree learning heuristics are mainstays of machine learning practice, but theoretical justification for their empirical success remains elusive. In fact, it has long been known that there are simple target functions for which they fail badly (Kearns and Mansour, STOC 1996). Recent work of Brutzkus, Daniely, and Malach (COLT 2020) considered the smoothed analysis model as a possible avenue towards resolving this disconnect. Within the smoothed setting and for targets $f$ that are $k$-juntas, they showed that these heuristics successfully learn $f$ with depth-$k$ decision tree hypotheses. They conjectured that the same guarantee holds more generally for targets that are depth-$k$ decision trees. We provide a counterexample to this conjecture: we construct targets that are depth-$k$ decision trees and show that even in the smoothed setting, these heuristics build trees of depth $2^{\Omega(k)}$ before achieving high accuracy. We also show that the guarantees of Brutzkus et al. cannot extend to the agnostic setting: there are targets that are very close to $k$-juntas, for which these heuristics build trees of depth $2^{\Omega(k)}$ before achieving high accuracy.