 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInsufficient Statistics Perturbation: Stable Estimators for Private Least Squares
Apr 23, 2024
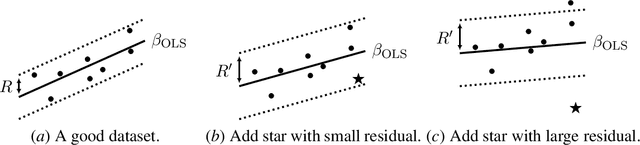
We present a sample- and time-efficient differentially private algorithm for ordinary least squares, with error that depends linearly on the dimension and is independent of the condition number of $X^\top X$, where $X$ is the design matrix. All prior private algorithms for this task require either $d^{3/2}$ examples, error growing polynomially with the condition number, or exponential time. Our near-optimal accuracy guarantee holds for any dataset with bounded statistical leverage and bounded residuals. Technically, we build on the approach of Brown et al. (2023) for private mean estimation, adding scaled noise to a carefully designed stable nonprivate estimator of the empirical regression vector.
A Combinatorial Approach to Robust PCA
Nov 28, 2023We study the problem of recovering Gaussian data under adversarial corruptions when the noises are low-rank and the corruptions are on the coordinate level. Concretely, we assume that the Gaussian noises lie in an unknown $k$-dimensional subspace $U \subseteq \mathbb{R}^d$, and $s$ randomly chosen coordinates of each data point fall into the control of an adversary. This setting models the scenario of learning from high-dimensional yet structured data that are transmitted through a highly-noisy channel, so that the data points are unlikely to be entirely clean. Our main result is an efficient algorithm that, when $ks^2 = O(d)$, recovers every single data point up to a nearly-optimal $\ell_1$ error of $\tilde O(ks/d)$ in expectation. At the core of our proof is a new analysis of the well-known Basis Pursuit (BP) method for recovering a sparse signal, which is known to succeed under additional assumptions (e.g., incoherence or the restricted isometry property) on the underlying subspace $U$. In contrast, we present a novel approach via studying a natural combinatorial problem and show that, over the randomness in the support of the sparse signal, a high-probability error bound is possible even if the subspace $U$ is arbitrary.
Transformers can optimally learn regression mixture models
Nov 14, 2023
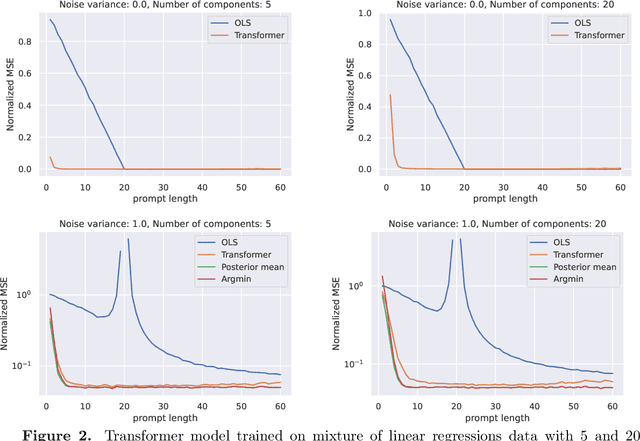


Mixture models arise in many regression problems, but most methods have seen limited adoption partly due to these algorithms' highly-tailored and model-specific nature. On the other hand, transformers are flexible, neural sequence models that present the intriguing possibility of providing general-purpose prediction methods, even in this mixture setting. In this work, we investigate the hypothesis that transformers can learn an optimal predictor for mixtures of regressions. We construct a generative process for a mixture of linear regressions for which the decision-theoretic optimal procedure is given by data-driven exponential weights on a finite set of parameters. We observe that transformers achieve low mean-squared error on data generated via this process. By probing the transformer's output at inference time, we also show that transformers typically make predictions that are close to the optimal predictor. Our experiments also demonstrate that transformers can learn mixtures of regressions in a sample-efficient fashion and are somewhat robust to distribution shifts. We complement our experimental observations by proving constructively that the decision-theoretic optimal procedure is indeed implementable by a transformer.
A decoder-only foundation model for time-series forecasting
Oct 14, 2023



Motivated by recent advances in large language models for Natural Language Processing (NLP), we design a time-series foundation model for forecasting whose out-of-the-box zero-shot performance on a variety of public datasets comes close to the accuracy of state-of-the-art supervised forecasting models for each individual dataset. Our model is based on pretraining a patched-decoder style attention model on a large time-series corpus, and can work well across different forecasting history lengths, prediction lengths and temporal granularities.
Linear Regression using Heterogeneous Data Batches
Sep 05, 2023


In many learning applications, data are collected from multiple sources, each providing a \emph{batch} of samples that by itself is insufficient to learn its input-output relationship. A common approach assumes that the sources fall in one of several unknown subgroups, each with an unknown input distribution and input-output relationship. We consider one of this setup's most fundamental and important manifestations where the output is a noisy linear combination of the inputs, and there are $k$ subgroups, each with its own regression vector. Prior work~\cite{kong2020meta} showed that with abundant small-batches, the regression vectors can be learned with only few, $\tilde\Omega( k^{3/2})$, batches of medium-size with $\tilde\Omega(\sqrt k)$ samples each. However, the paper requires that the input distribution for all $k$ subgroups be isotropic Gaussian, and states that removing this assumption is an ``interesting and challenging problem". We propose a novel gradient-based algorithm that improves on the existing results in several ways. It extends the applicability of the algorithm by: (1) allowing the subgroups' underlying input distributions to be different, unknown, and heavy-tailed; (2) recovering all subgroups followed by a significant proportion of batches even for infinite $k$; (3) removing the separation requirement between the regression vectors; (4) reducing the number of batches and allowing smaller batch sizes.
Long-term Forecasting with TiDE: Time-series Dense Encoder
Apr 27, 2023



Recent work has shown that simple linear models can outperform several Transformer based approaches in long term time-series forecasting. Motivated by this, we propose a Multi-layer Perceptron (MLP) based encoder-decoder model, Time-series Dense Encoder (TiDE), for long-term time-series forecasting that enjoys the simplicity and speed of linear models while also being able to handle covariates and non-linear dependencies. Theoretically, we prove that the simplest linear analogue of our model can achieve near optimal error rate for linear dynamical systems (LDS) under some assumptions. Empirically, we show that our method can match or outperform prior approaches on popular long-term time-series forecasting benchmarks while being 5-10x faster than the best Transformer based model.
Estimating Optimal Policy Value in General Linear Contextual Bandits
Feb 19, 2023


In many bandit problems, the maximal reward achievable by a policy is often unknown in advance. We consider the problem of estimating the optimal policy value in the sublinear data regime before the optimal policy is even learnable. We refer to this as $V^*$ estimation. It was recently shown that fast $V^*$ estimation is possible but only in disjoint linear bandits with Gaussian covariates. Whether this is possible for more realistic context distributions has remained an open and important question for tasks such as model selection. In this paper, we first provide lower bounds showing that this general problem is hard. However, under stronger assumptions, we give an algorithm and analysis proving that $\widetilde{\mathcal{O}}(\sqrt{d})$ sublinear estimation of $V^*$ is indeed information-theoretically possible, where $d$ is the dimension. We then present a more practical, computationally efficient algorithm that estimates a problem-dependent upper bound on $V^*$ that holds for general distributions and is tight when the context distribution is Gaussian. We prove our algorithm requires only $\widetilde{\mathcal{O}}(\sqrt{d})$ samples to estimate the upper bound. We use this upper bound and the estimator to obtain novel and improved guarantees for several applications in bandit model selection and testing for treatment effects.
Near Optimal Private and Robust Linear Regression
Jan 30, 2023



We study the canonical statistical estimation problem of linear regression from $n$ i.i.d.~examples under $(\varepsilon,\delta)$-differential privacy when some response variables are adversarially corrupted. We propose a variant of the popular differentially private stochastic gradient descent (DP-SGD) algorithm with two innovations: a full-batch gradient descent to improve sample complexity and a novel adaptive clipping to guarantee robustness. When there is no adversarial corruption, this algorithm improves upon the existing state-of-the-art approach and achieves a near optimal sample complexity. Under label-corruption, this is the first efficient linear regression algorithm to guarantee both $(\varepsilon,\delta)$-DP and robustness. Synthetic experiments confirm the superiority of our approach.
Efficient List-Decodable Regression using Batches
Nov 23, 2022We begin the study of list-decodable linear regression using batches. In this setting only an $\alpha \in (0,1]$ fraction of the batches are genuine. Each genuine batch contains $\ge n$ i.i.d. samples from a common unknown distribution and the remaining batches may contain arbitrary or even adversarial samples. We derive a polynomial time algorithm that for any $n\ge \tilde \Omega(1/\alpha)$ returns a list of size $\mathcal O(1/\alpha^2)$ such that one of the items in the list is close to the true regression parameter. The algorithm requires only $\tilde{\mathcal{O}}(d/\alpha^2)$ genuine batches and works under fairly general assumptions on the distribution. The results demonstrate the utility of batch structure, which allows for the first polynomial time algorithm for list-decodable regression, which may be impossible for the non-batch setting, as suggested by a recent SQ lower bound \cite{diakonikolas2021statistical} for the non-batch setting.
Trimmed Maximum Likelihood Estimation for Robust Learning in Generalized Linear Models
Jun 09, 2022We study the problem of learning generalized linear models under adversarial corruptions. We analyze a classical heuristic called the iterative trimmed maximum likelihood estimator which is known to be effective against label corruptions in practice. Under label corruptions, we prove that this simple estimator achieves minimax near-optimal risk on a wide range of generalized linear models, including Gaussian regression, Poisson regression and Binomial regression. Finally, we extend the estimator to the more challenging setting of label and covariate corruptions and demonstrate its robustness and optimality in that setting as well.