 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIn-Context Fine-Tuning for Time-Series Foundation Models
Oct 31, 2024



Motivated by the recent success of time-series foundation models for zero-shot forecasting, we present a methodology for $\textit{in-context fine-tuning}$ of a time-series foundation model. In particular, we design a pretrained foundation model that can be prompted (at inference time) with multiple time-series examples, in order to forecast a target time-series into the future. Our foundation model is specifically trained to utilize examples from multiple related time-series in its context window (in addition to the history of the target time-series) to help it adapt to the specific distribution of the target domain at inference time. We show that such a foundation model that uses in-context examples at inference time can obtain much better performance on popular forecasting benchmarks compared to supervised deep learning methods, statistical models, as well as other time-series foundation models. Interestingly, our in-context fine-tuning approach even rivals the performance of a foundation model that is explicitly fine-tuned on the target domain.
A decoder-only foundation model for time-series forecasting
Oct 14, 2023



Motivated by recent advances in large language models for Natural Language Processing (NLP), we design a time-series foundation model for forecasting whose out-of-the-box zero-shot performance on a variety of public datasets comes close to the accuracy of state-of-the-art supervised forecasting models for each individual dataset. Our model is based on pretraining a patched-decoder style attention model on a large time-series corpus, and can work well across different forecasting history lengths, prediction lengths and temporal granularities.
MetaFormer Baselines for Vision
Oct 24, 2022



MetaFormer, the abstracted architecture of Transformer, has been found to play a significant role in achieving competitive performance. In this paper, we further explore the capacity of MetaFormer, again, without focusing on token mixer design: we introduce several baseline models under MetaFormer using the most basic or common mixers, and summarize our observations as follows: (1) MetaFormer ensures solid lower bound of performance. By merely adopting identity mapping as the token mixer, the MetaFormer model, termed IdentityFormer, achieves >80% accuracy on ImageNet-1K. (2) MetaFormer works well with arbitrary token mixers. When specifying the token mixer as even a random matrix to mix tokens, the resulting model RandFormer yields an accuracy of >81%, outperforming IdentityFormer. Rest assured of MetaFormer's results when new token mixers are adopted. (3) MetaFormer effortlessly offers state-of-the-art results. With just conventional token mixers dated back five years ago, the models instantiated from MetaFormer already beat state of the art. (a) ConvFormer outperforms ConvNeXt. Taking the common depthwise separable convolutions as the token mixer, the model termed ConvFormer, which can be regarded as pure CNNs, outperforms the strong CNN model ConvNeXt. (b) CAFormer sets new record on ImageNet-1K. By simply applying depthwise separable convolutions as token mixer in the bottom stages and vanilla self-attention in the top stages, the resulting model CAFormer sets a new record on ImageNet-1K: it achieves an accuracy of 85.5% at 224x224 resolution, under normal supervised training without external data or distillation. In our expedition to probe MetaFormer, we also find that a new activation, StarReLU, reduces 71% FLOPs of activation compared with GELU yet achieves better performance. We expect StarReLU to find great potential in MetaFormer-like models alongside other neural networks.
Robust Distillation for Worst-class Performance
Jun 13, 2022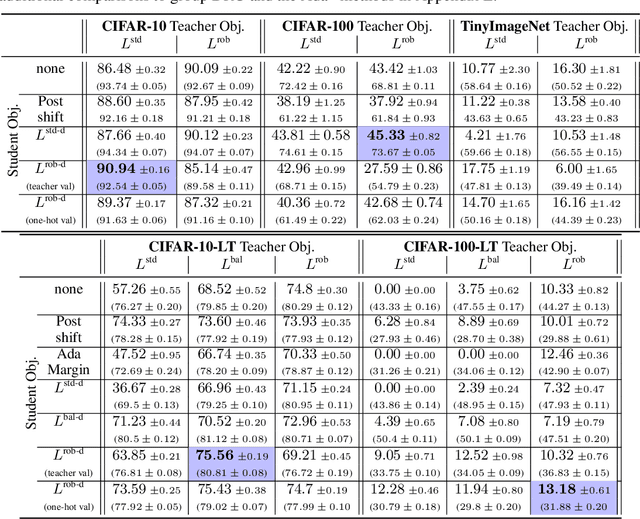
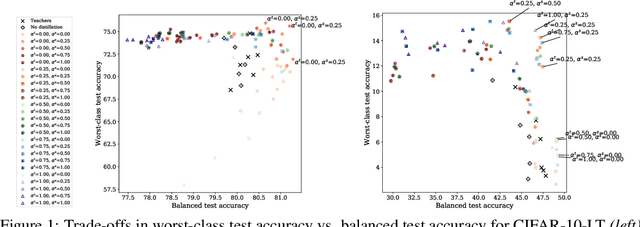
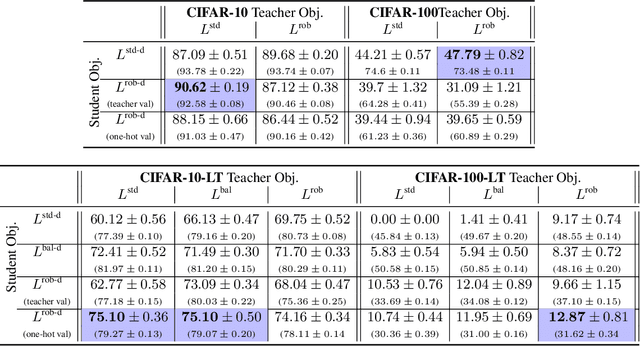
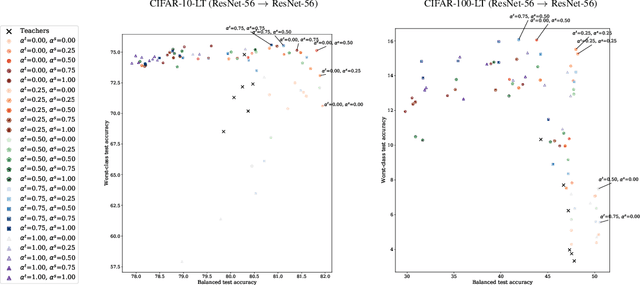
Knowledge distillation has proven to be an effective technique in improving the performance a student model using predictions from a teacher model. However, recent work has shown that gains in average efficiency are not uniform across subgroups in the data, and in particular can often come at the cost of accuracy on rare subgroups and classes. To preserve strong performance across classes that may follow a long-tailed distribution, we develop distillation techniques that are tailored to improve the student's worst-class performance. Specifically, we introduce robust optimization objectives in different combinations for the teacher and student, and further allow for training with any tradeoff between the overall accuracy and the robust worst-class objective. We show empirically that our robust distillation techniques not only achieve better worst-class performance, but also lead to Pareto improvement in the tradeoff between overall performance and worst-class performance compared to other baseline methods. Theoretically, we provide insights into what makes a good teacher when the goal is to train a robust student.
Inception Transformer
May 26, 2022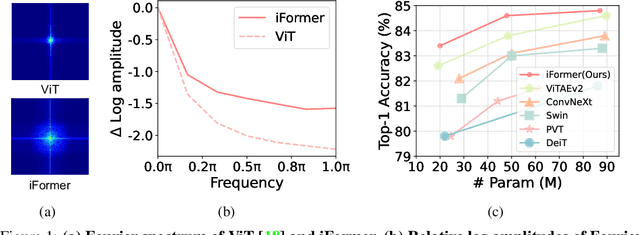
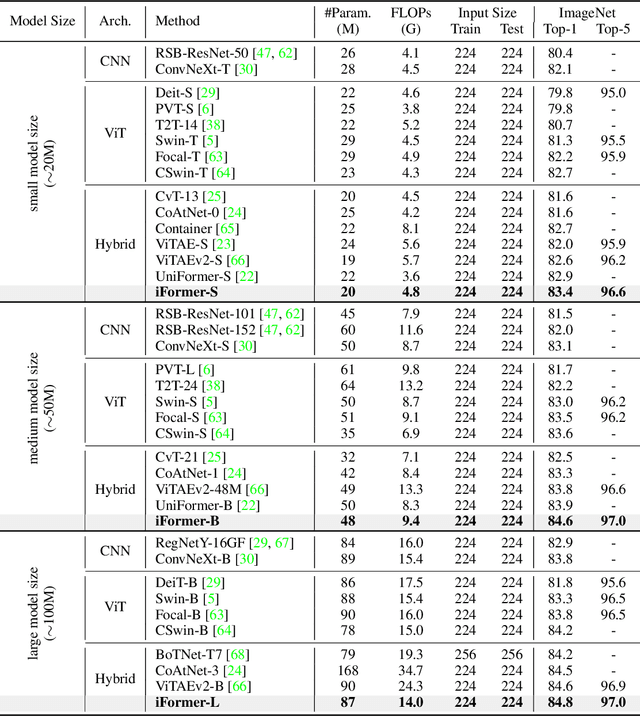
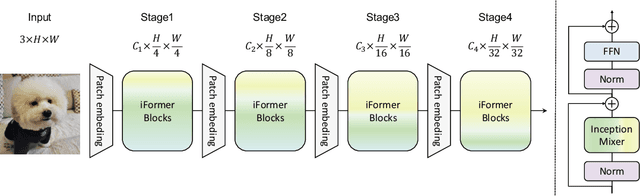
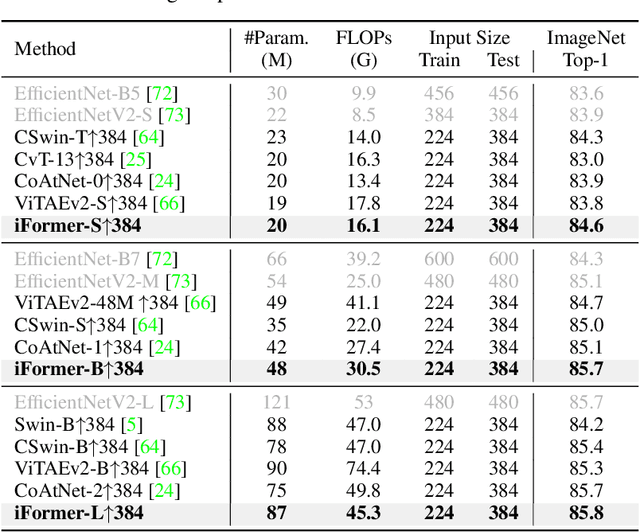
Recent studies show that Transformer has strong capability of building long-range dependencies, yet is incompetent in capturing high frequencies that predominantly convey local information. To tackle this issue, we present a novel and general-purpose Inception Transformer, or iFormer for short, that effectively learns comprehensive features with both high- and low-frequency information in visual data. Specifically, we design an Inception mixer to explicitly graft the advantages of convolution and max-pooling for capturing the high-frequency information to Transformers. Different from recent hybrid frameworks, the Inception mixer brings greater efficiency through a channel splitting mechanism to adopt parallel convolution/max-pooling path and self-attention path as high- and low-frequency mixers, while having the flexibility to model discriminative information scattered within a wide frequency range. Considering that bottom layers play more roles in capturing high-frequency details while top layers more in modeling low-frequency global information, we further introduce a frequency ramp structure, i.e. gradually decreasing the dimensions fed to the high-frequency mixer and increasing those to the low-frequency mixer, which can effectively trade-off high- and low-frequency components across different layers. We benchmark the iFormer on a series of vision tasks, and showcase that it achieves impressive performance on image classification, COCO detection and ADE20K segmentation. For example, our iFormer-S hits the top-1 accuracy of 83.4% on ImageNet-1K, much higher than DeiT-S by 3.6%, and even slightly better than much bigger model Swin-B (83.3%) with only 1/4 parameters and 1/3 FLOPs. Code and models will be released at https://github.com/sail-sg/iFormer.
Mugs: A Multi-Granular Self-Supervised Learning Framework
Mar 27, 2022
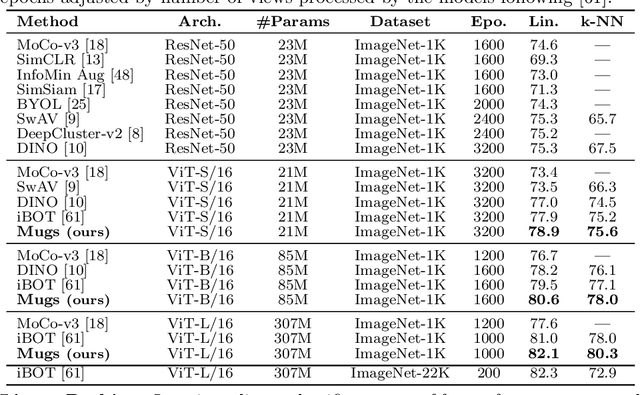
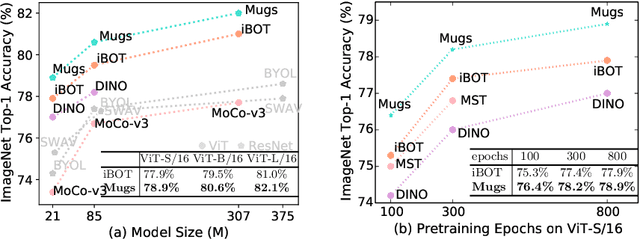
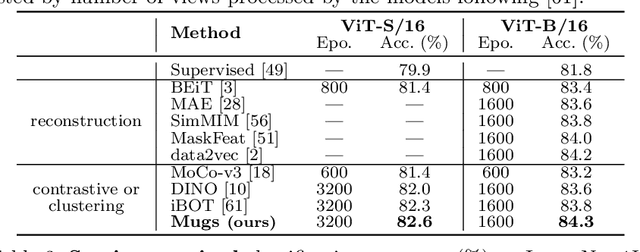
In self-supervised learning, multi-granular features are heavily desired though rarely investigated, as different downstream tasks (e.g., general and fine-grained classification) often require different or multi-granular features, e.g.~fine- or coarse-grained one or their mixture. In this work, for the first time, we propose an effective MUlti-Granular Self-supervised learning (Mugs) framework to explicitly learn multi-granular visual features. Mugs has three complementary granular supervisions: 1) an instance discrimination supervision (IDS), 2) a novel local-group discrimination supervision (LGDS), and 3) a group discrimination supervision (GDS). IDS distinguishes different instances to learn instance-level fine-grained features. LGDS aggregates features of an image and its neighbors into a local-group feature, and pulls local-group features from different crops of the same image together and push them away for others. It provides complementary instance supervision to IDS via an extra alignment on local neighbors, and scatters different local-groups separately to increase discriminability. Accordingly, it helps learn high-level fine-grained features at a local-group level. Finally, to prevent similar local-groups from being scattered randomly or far away, GDS brings similar samples close and thus pulls similar local-groups together, capturing coarse-grained features at a (semantic) group level. Consequently, Mugs can capture three granular features that often enjoy higher generality on diverse downstream tasks over single-granular features, e.g.~instance-level fine-grained features in contrastive learning. By only pretraining on ImageNet-1K, Mugs sets new SoTA linear probing accuracy 82.1$\%$ on ImageNet-1K and improves previous SoTA by $1.1\%$. It also surpasses SoTAs on other tasks, e.g. transfer learning, detection and segmentation.
MetaFormer is Actually What You Need for Vision
Nov 29, 2021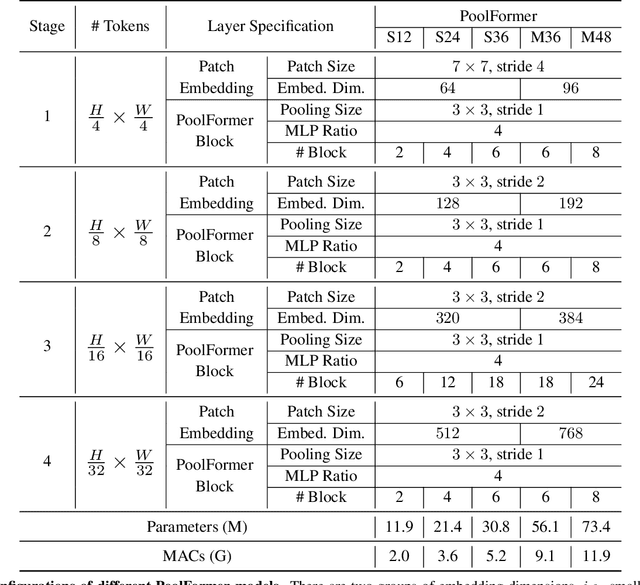
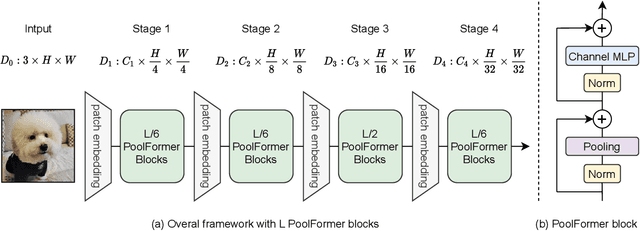
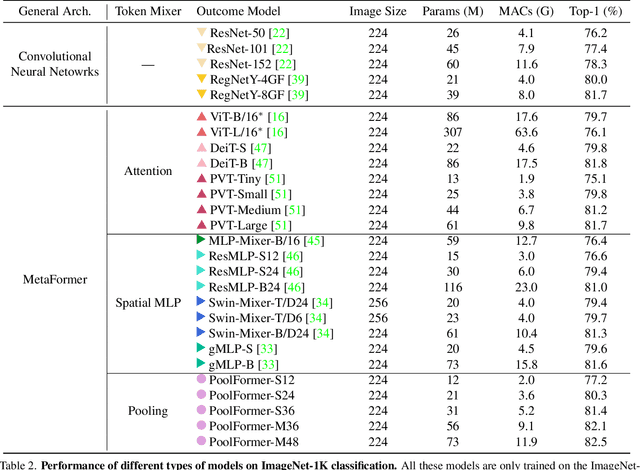
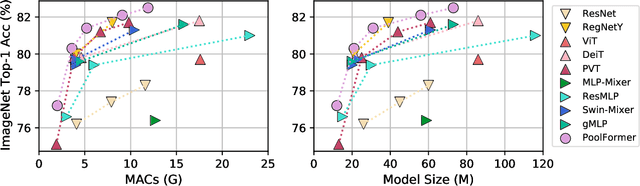
Transformers have shown great potential in computer vision tasks. A common belief is their attention-based token mixer module contributes most to their competence. However, recent works show the attention-based module in transformers can be replaced by spatial MLPs and the resulted models still perform quite well. Based on this observation, we hypothesize that the general architecture of the transformers, instead of the specific token mixer module, is more essential to the model's performance. To verify this, we deliberately replace the attention module in transformers with an embarrassingly simple spatial pooling operator to conduct only the most basic token mixing. Surprisingly, we observe that the derived model, termed as PoolFormer, achieves competitive performance on multiple computer vision tasks. For example, on ImageNet-1K, PoolFormer achieves 82.1% top-1 accuracy, surpassing well-tuned vision transformer/MLP-like baselines DeiT-B/ResMLP-B24 by 0.3%/1.1% accuracy with 35%/52% fewer parameters and 48%/60% fewer MACs. The effectiveness of PoolFormer verifies our hypothesis and urges us to initiate the concept of "MetaFormer", a general architecture abstracted from transformers without specifying the token mixer. Based on the extensive experiments, we argue that MetaFormer is the key player in achieving superior results for recent transformer and MLP-like models on vision tasks. This work calls for more future research dedicated to improving MetaFormer instead of focusing on the token mixer modules. Additionally, our proposed PoolFormer could serve as a starting baseline for future MetaFormer architecture design. Code is available at https://github.com/sail-sg/poolformer
Distilling Double Descent
Feb 13, 2021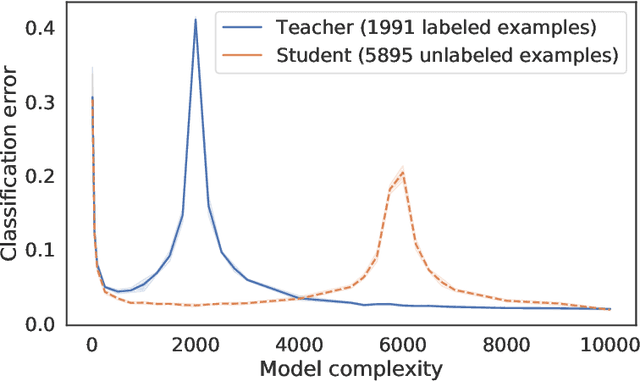
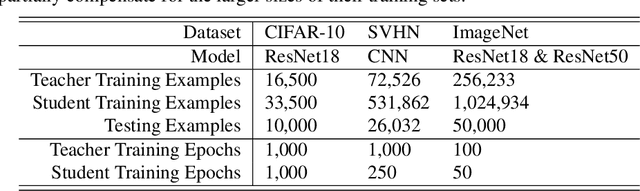
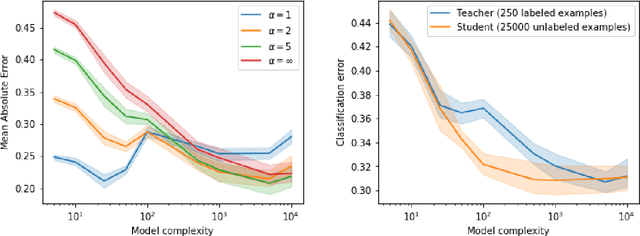
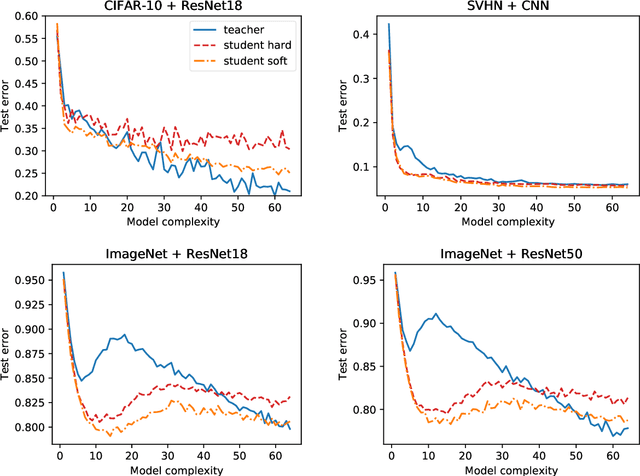
Distillation is the technique of training a "student" model based on examples that are labeled by a separate "teacher" model, which itself is trained on a labeled dataset. The most common explanations for why distillation "works" are predicated on the assumption that student is provided with \emph{soft} labels, \eg probabilities or confidences, from the teacher model. In this work, we show, that, even when the teacher model is highly overparameterized, and provides \emph{hard} labels, using a very large held-out unlabeled dataset to train the student model can result in a model that outperforms more "traditional" approaches. Our explanation for this phenomenon is based on recent work on "double descent". It has been observed that, once a model's complexity roughly exceeds the amount required to memorize the training data, increasing the complexity \emph{further} can, counterintuitively, result in \emph{better} generalization. Researchers have identified several settings in which it takes place, while others have made various attempts to explain it (thus far, with only partial success). In contrast, we avoid these questions, and instead seek to \emph{exploit} this phenomenon by demonstrating that a highly-overparameterized teacher can avoid overfitting via double descent, while a student trained on a larger independent dataset labeled by this teacher will avoid overfitting due to the size of its training set.
Towards Accurate Human Pose Estimation in Videos of Crowded Scenes
Oct 21, 2020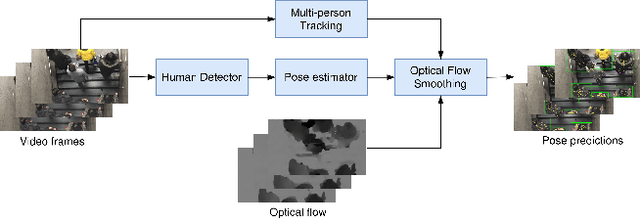

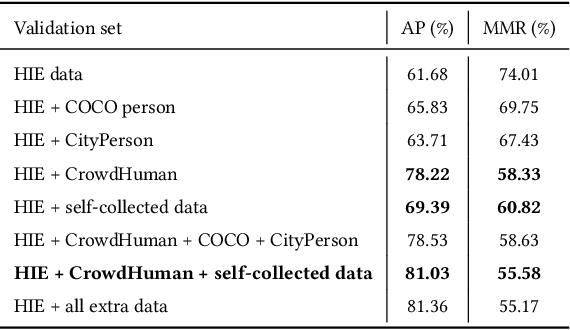
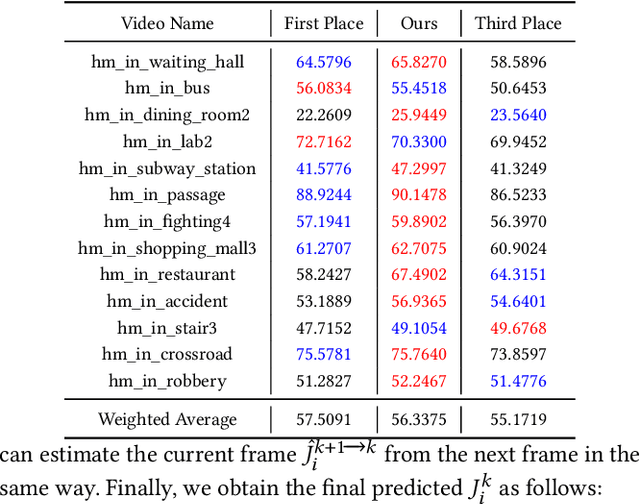
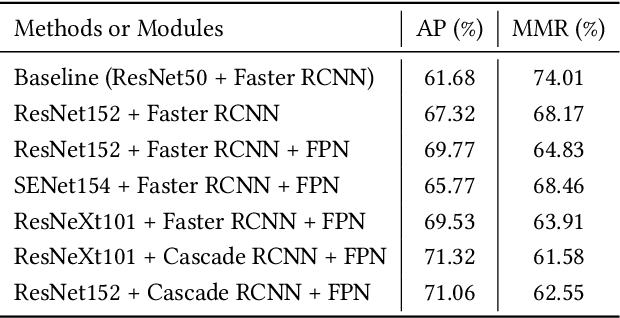
Video-based human pose estimation in crowded scenes is a challenging problem due to occlusion, motion blur, scale variation and viewpoint change, etc. Prior approaches always fail to deal with this problem because of (1) lacking of usage of temporal information; (2) lacking of training data in crowded scenes. In this paper, we focus on improving human pose estimation in videos of crowded scenes from the perspectives of exploiting temporal context and collecting new data. In particular, we first follow the top-down strategy to detect persons and perform single-person pose estimation for each frame. Then, we refine the frame-based pose estimation with temporal contexts deriving from the optical-flow. Specifically, for one frame, we forward the historical poses from the previous frames and backward the future poses from the subsequent frames to current frame, leading to stable and accurate human pose estimation in videos. In addition, we mine new data of similar scenes to HIE dataset from the Internet for improving the diversity of training set. In this way, our model achieves best performance on 7 out of 13 videos and 56.33 average w\_AP on test dataset of HIE challenge.
A Simple Baseline for Pose Tracking in Videos of Crowded Scenes
Oct 21, 2020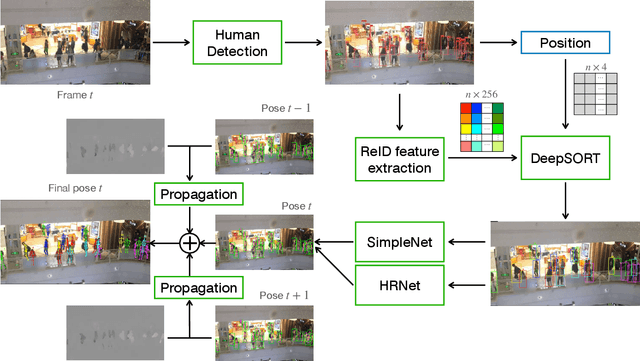
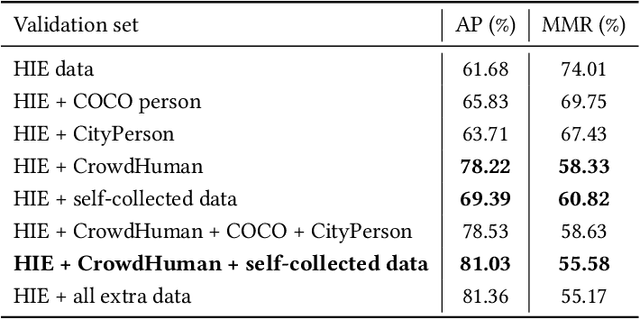

This paper presents our solution to ACM MM challenge: Large-scale Human-centric Video Analysis in Complex Events\cite{lin2020human}; specifically, here we focus on Track3: Crowd Pose Tracking in Complex Events. Remarkable progress has been made in multi-pose training in recent years. However, how to track the human pose in crowded and complex environments has not been well addressed. We formulate the problem as several subproblems to be solved. First, we use a multi-object tracking method to assign human ID to each bounding box generated by the detection model. After that, a pose is generated to each bounding box with ID. At last, optical flow is used to take advantage of the temporal information in the videos and generate the final pose tracking result.