 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeARGenSeg: Image Segmentation with Autoregressive Image Generation Model
Oct 23, 2025
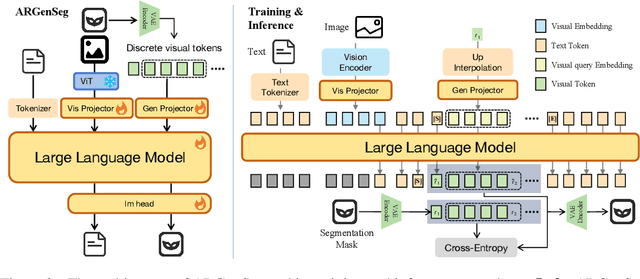
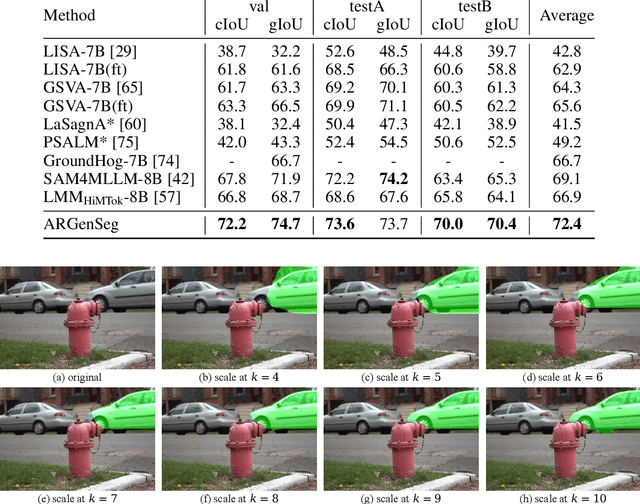

We propose a novel AutoRegressive Generation-based paradigm for image Segmentation (ARGenSeg), achieving multimodal understanding and pixel-level perception within a unified framework. Prior works integrating image segmentation into multimodal large language models (MLLMs) typically employ either boundary points representation or dedicated segmentation heads. These methods rely on discrete representations or semantic prompts fed into task-specific decoders, which limits the ability of the MLLM to capture fine-grained visual details. To address these challenges, we introduce a segmentation framework for MLLM based on image generation, which naturally produces dense masks for target objects. We leverage MLLM to output visual tokens and detokenize them into images using an universal VQ-VAE, making the segmentation fully dependent on the pixel-level understanding of the MLLM. To reduce inference latency, we employ a next-scale-prediction strategy to generate required visual tokens in parallel. Extensive experiments demonstrate that our method surpasses prior state-of-the-art approaches on multiple segmentation datasets with a remarkable boost in inference speed, while maintaining strong understanding capabilities.
Vision-Centric Activation and Coordination for Multimodal Large Language Models
Oct 16, 2025Multimodal large language models (MLLMs) integrate image features from visual encoders with LLMs, demonstrating advanced comprehension capabilities. However, mainstream MLLMs are solely supervised by the next-token prediction of textual tokens, neglecting critical vision-centric information essential for analytical abilities. To track this dilemma, we introduce VaCo, which optimizes MLLM representations through Vision-Centric activation and Coordination from multiple vision foundation models (VFMs). VaCo introduces visual discriminative alignment to integrate task-aware perceptual features extracted from VFMs, thereby unifying the optimization of both textual and visual outputs in MLLMs. Specifically, we incorporate the learnable Modular Task Queries (MTQs) and Visual Alignment Layers (VALs) into MLLMs, activating specific visual signals under the supervision of diverse VFMs. To coordinate representation conflicts across VFMs, the crafted Token Gateway Mask (TGM) restricts the information flow among multiple groups of MTQs. Extensive experiments demonstrate that VaCo significantly improves the performance of different MLLMs on various benchmarks, showcasing its superior capabilities in visual comprehension.
Ming-Omni: A Unified Multimodal Model for Perception and Generation
Jun 11, 2025



We propose Ming-Omni, a unified multimodal model capable of processing images, text, audio, and video, while demonstrating strong proficiency in both speech and image generation. Ming-Omni employs dedicated encoders to extract tokens from different modalities, which are then processed by Ling, an MoE architecture equipped with newly proposed modality-specific routers. This design enables a single model to efficiently process and fuse multimodal inputs within a unified framework, thereby facilitating diverse tasks without requiring separate models, task-specific fine-tuning, or structural redesign. Importantly, Ming-Omni extends beyond conventional multimodal models by supporting audio and image generation. This is achieved through the integration of an advanced audio decoder for natural-sounding speech and Ming-Lite-Uni for high-quality image generation, which also allow the model to engage in context-aware chatting, perform text-to-speech conversion, and conduct versatile image editing. Our experimental results showcase Ming-Omni offers a powerful solution for unified perception and generation across all modalities. Notably, our proposed Ming-Omni is the first open-source model we are aware of to match GPT-4o in modality support, and we release all code and model weights to encourage further research and development in the community.
Advancing 3D Medical Image Segmentation: Unleashing the Potential of Planarian Neural Networks in Artificial Intelligence
May 07, 2025Our study presents PNN-UNet as a method for constructing deep neural networks that replicate the planarian neural network (PNN) structure in the context of 3D medical image data. Planarians typically have a cerebral structure comprising two neural cords, where the cerebrum acts as a coordinator, and the neural cords serve slightly different purposes within the organism's neurological system. Accordingly, PNN-UNet comprises a Deep-UNet and a Wide-UNet as the nerve cords, with a densely connected autoencoder performing the role of the brain. This distinct architecture offers advantages over both monolithic (UNet) and modular networks (Ensemble-UNet). Our outcomes on a 3D MRI hippocampus dataset, with and without data augmentation, demonstrate that PNN-UNet outperforms the baseline UNet and several other UNet variants in image segmentation.
Ming-Lite-Uni: Advancements in Unified Architecture for Natural Multimodal Interaction
May 05, 2025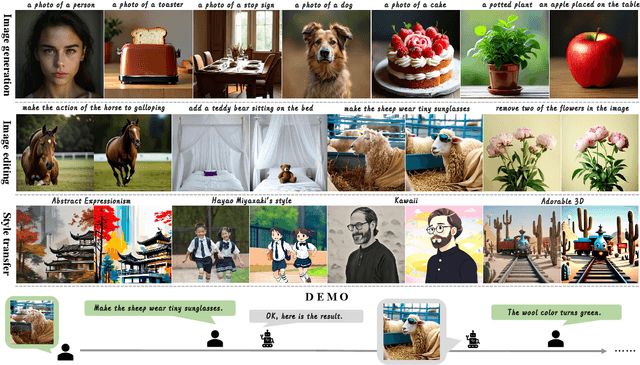

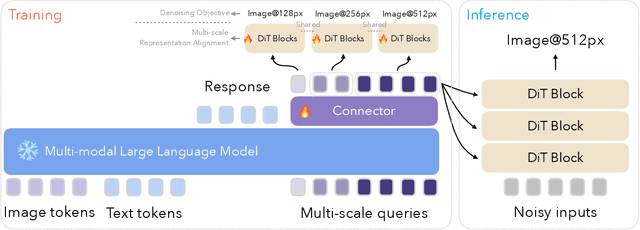
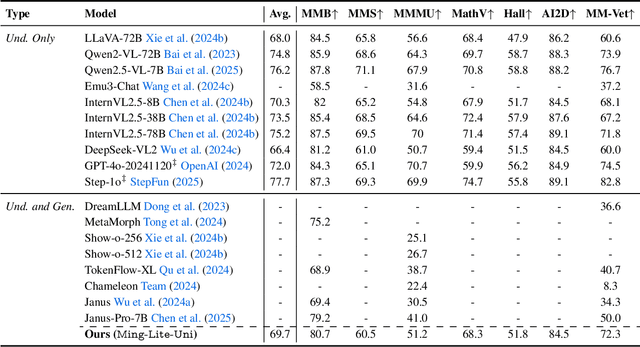
We introduce Ming-Lite-Uni, an open-source multimodal framework featuring a newly designed unified visual generator and a native multimodal autoregressive model tailored for unifying vision and language. Specifically, this project provides an open-source implementation of the integrated MetaQueries and M2-omni framework, while introducing the novel multi-scale learnable tokens and multi-scale representation alignment strategy. By leveraging a fixed MLLM and a learnable diffusion model, Ming-Lite-Uni enables native multimodal AR models to perform both text-to-image generation and instruction based image editing tasks, expanding their capabilities beyond pure visual understanding. Our experimental results demonstrate the strong performance of Ming-Lite-Uni and illustrate the impressive fluid nature of its interactive process. All code and model weights are open-sourced to foster further exploration within the community. Notably, this work aligns with concurrent multimodal AI milestones - such as ChatGPT-4o with native image generation updated in March 25, 2025 - underscoring the broader significance of unified models like Ming-Lite-Uni on the path toward AGI. Ming-Lite-Uni is in alpha stage and will soon be further refined.
ADAM-1: AI and Bioinformatics for Alzheimer's Detection and Microbiome-Clinical Data Integrations
Jan 14, 2025



The Alzheimer's Disease Analysis Model Generation 1 (ADAM) is a multi-agent large language model (LLM) framework designed to integrate and analyze multi-modal data, including microbiome profiles, clinical datasets, and external knowledge bases, to enhance the understanding and detection of Alzheimer's disease (AD). By leveraging retrieval-augmented generation (RAG) techniques along with its multi-agent architecture, ADAM-1 synthesizes insights from diverse data sources and contextualizes findings using literature-driven evidence. Comparative evaluation against XGBoost revealed similar mean F1 scores but significantly reduced variance for ADAM-1, highlighting its robustness and consistency, particularly in small laboratory datasets. While currently tailored for binary classification tasks, future iterations aim to incorporate additional data modalities, such as neuroimaging and biomarkers, to broaden the scalability and applicability for Alzheimer's research and diagnostics.
Planarian Neural Networks: Evolutionary Patterns from Basic Bilateria Shaping Modern Artificial Neural Network Architectures
Jan 08, 2025



This study examined the viability of enhancing the prediction accuracy of artificial neural networks (ANNs) in image classification tasks by developing ANNs with evolution patterns similar to those of biological neural networks. ResNet is a widely used family of neural networks with both deep and wide variants; therefore, it was selected as the base model for our investigation. The aim of this study is to improve the image classification performance of ANNs via a novel approach inspired by the biological nervous system architecture of planarians, which comprises a brain and two nerve cords. We believe that the unique neural architecture of planarians offers valuable insights into the performance enhancement of ANNs. The proposed planarian neural architecture-based neural network was evaluated on the CIFAR-10 and CIFAR-100 datasets. Our results indicate that the proposed method exhibits higher prediction accuracy than the baseline neural network models in image classification tasks. These findings demonstrate the significant potential of biologically inspired neural network architectures in improving the performance of ANNs in a wide range of applications.
Accelerating Pre-training of Multimodal LLMs via Chain-of-Sight
Jul 22, 2024

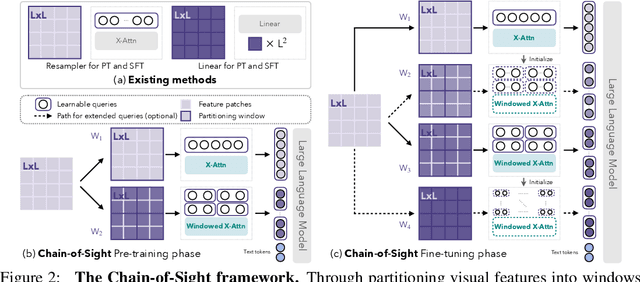

This paper introduces Chain-of-Sight, a vision-language bridge module that accelerates the pre-training of Multimodal Large Language Models (MLLMs). Our approach employs a sequence of visual resamplers that capture visual details at various spacial scales. This architecture not only leverages global and local visual contexts effectively, but also facilitates the flexible extension of visual tokens through a compound token scaling strategy, allowing up to a 16x increase in the token count post pre-training. Consequently, Chain-of-Sight requires significantly fewer visual tokens in the pre-training phase compared to the fine-tuning phase. This intentional reduction of visual tokens during pre-training notably accelerates the pre-training process, cutting down the wall-clock training time by ~73%. Empirical results on a series of vision-language benchmarks reveal that the pre-train acceleration through Chain-of-Sight is achieved without sacrificing performance, matching or surpassing the standard pipeline of utilizing all visual tokens throughout the entire training process. Further scaling up the number of visual tokens for pre-training leads to stronger performances, competitive to existing approaches in a series of benchmarks.
SkySense: A Multi-Modal Remote Sensing Foundation Model Towards Universal Interpretation for Earth Observation Imagery
Dec 15, 2023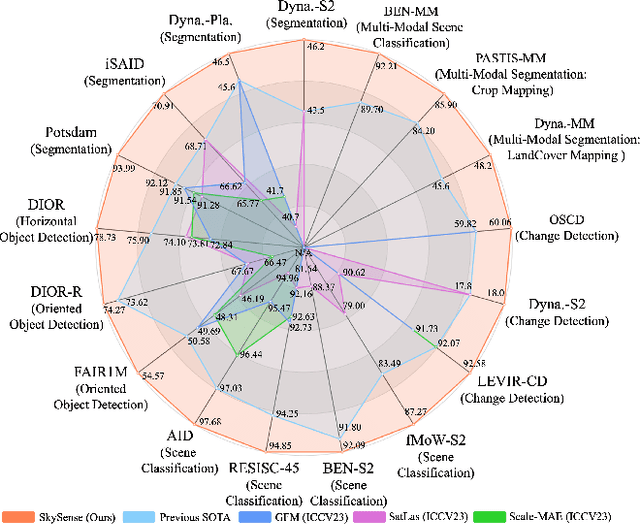
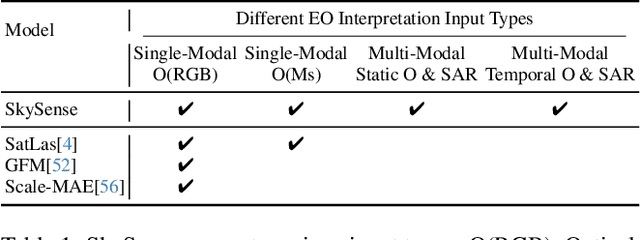
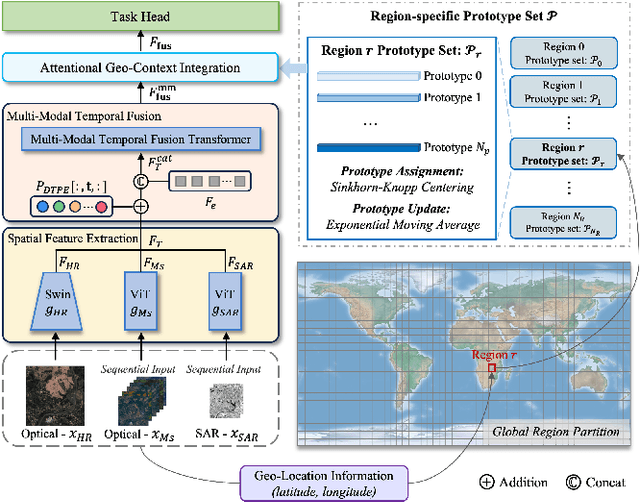
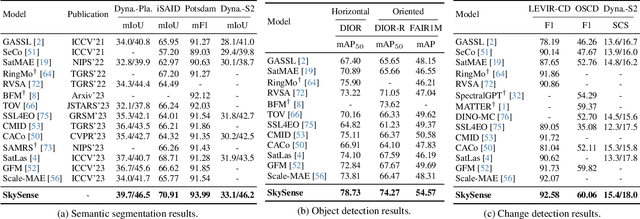
Prior studies on Remote Sensing Foundation Model (RSFM) reveal immense potential towards a generic model for Earth Observation. Nevertheless, these works primarily focus on a single modality without temporal and geo-context modeling, hampering their capabilities for diverse tasks. In this study, we present SkySense, a generic billion-scale model, pre-trained on a curated multi-modal Remote Sensing Imagery (RSI) dataset with 21.5 million temporal sequences. SkySense incorporates a factorized multi-modal spatiotemporal encoder taking temporal sequences of optical and Synthetic Aperture Radar (SAR) data as input. This encoder is pre-trained by our proposed Multi-Granularity Contrastive Learning to learn representations across different modal and spatial granularities. To further enhance the RSI representations by the geo-context clue, we introduce Geo-Context Prototype Learning to learn region-aware prototypes upon RSI's multi-modal spatiotemporal features. To our best knowledge, SkySense is the largest Multi-Modal RSFM to date, whose modules can be flexibly combined or used individually to accommodate various tasks. It demonstrates remarkable generalization capabilities on a thorough evaluation encompassing 16 datasets over 7 tasks, from single- to multi-modal, static to temporal, and classification to localization. SkySense surpasses 18 recent RSFMs in all test scenarios. Specifically, it outperforms the latest models such as GFM, SatLas and Scale-MAE by a large margin, i.e., 2.76%, 3.67% and 3.61% on average respectively. We will release the pre-trained weights to facilitate future research and Earth Observation applications.
Res-Tuning: A Flexible and Efficient Tuning Paradigm via Unbinding Tuner from Backbone
Oct 30, 2023Parameter-efficient tuning has become a trend in transferring large-scale foundation models to downstream applications. Existing methods typically embed some light-weight tuners into the backbone, where both the design and the learning of the tuners are highly dependent on the base model. This work offers a new tuning paradigm, dubbed Res-Tuning, which intentionally unbinds tuners from the backbone. With both theoretical and empirical evidence, we show that popular tuning approaches have their equivalent counterparts under our unbinding formulation, and hence can be integrated into our framework effortlessly. Thanks to the structural disentanglement, we manage to free the design of tuners from the network architecture, facilitating flexible combination of various tuning strategies. We further propose a memory-efficient variant of Res-Tuning, where the bypass i.e., formed by a sequence of tuners) is effectively detached from the main branch, such that the gradients are back-propagated only to the tuners but not to the backbone. Such a detachment also allows one-time backbone forward for multi-task inference. Extensive experiments on both discriminative and generative tasks demonstrate the superiority of our method over existing alternatives from the perspectives of efficacy and efficiency. Project page: $\href{https://res-tuning.github.io/}{\textit{https://res-tuning.github.io/}}$.