 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMing-Omni: A Unified Multimodal Model for Perception and Generation
Jun 11, 2025



We propose Ming-Omni, a unified multimodal model capable of processing images, text, audio, and video, while demonstrating strong proficiency in both speech and image generation. Ming-Omni employs dedicated encoders to extract tokens from different modalities, which are then processed by Ling, an MoE architecture equipped with newly proposed modality-specific routers. This design enables a single model to efficiently process and fuse multimodal inputs within a unified framework, thereby facilitating diverse tasks without requiring separate models, task-specific fine-tuning, or structural redesign. Importantly, Ming-Omni extends beyond conventional multimodal models by supporting audio and image generation. This is achieved through the integration of an advanced audio decoder for natural-sounding speech and Ming-Lite-Uni for high-quality image generation, which also allow the model to engage in context-aware chatting, perform text-to-speech conversion, and conduct versatile image editing. Our experimental results showcase Ming-Omni offers a powerful solution for unified perception and generation across all modalities. Notably, our proposed Ming-Omni is the first open-source model we are aware of to match GPT-4o in modality support, and we release all code and model weights to encourage further research and development in the community.
M2-omni: Advancing Omni-MLLM for Comprehensive Modality Support with Competitive Performance
Feb 26, 2025We present M2-omni, a cutting-edge, open-source omni-MLLM that achieves competitive performance to GPT-4o. M2-omni employs a unified multimodal sequence modeling framework, which empowers Large Language Models(LLMs) to acquire comprehensive cross-modal understanding and generation capabilities. Specifically, M2-omni can process arbitrary combinations of audio, video, image, and text modalities as input, generating multimodal sequences interleaving with audio, image, or text outputs, thereby enabling an advanced and interactive real-time experience. The training of such an omni-MLLM is challenged by significant disparities in data quantity and convergence rates across modalities. To address these challenges, we propose a step balance strategy during pre-training to handle the quantity disparities in modality-specific data. Additionally, a dynamically adaptive balance strategy is introduced during the instruction tuning stage to synchronize the modality-wise training progress, ensuring optimal convergence. Notably, we prioritize preserving strong performance on pure text tasks to maintain the robustness of M2-omni's language understanding capability throughout the training process. To our best knowledge, M2-omni is currently a very competitive open-source model to GPT-4o, characterized by its comprehensive modality and task support, as well as its exceptional performance. We expect M2-omni will advance the development of omni-MLLMs, thus facilitating future research in this domain.
Accelerating Pre-training of Multimodal LLMs via Chain-of-Sight
Jul 22, 2024

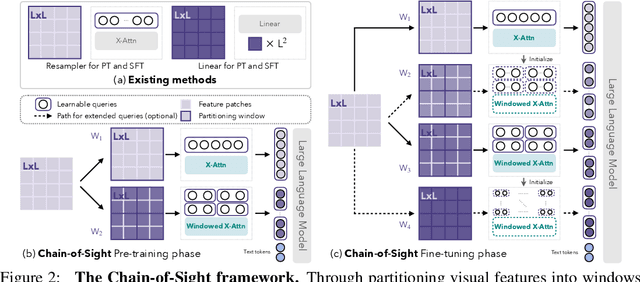

This paper introduces Chain-of-Sight, a vision-language bridge module that accelerates the pre-training of Multimodal Large Language Models (MLLMs). Our approach employs a sequence of visual resamplers that capture visual details at various spacial scales. This architecture not only leverages global and local visual contexts effectively, but also facilitates the flexible extension of visual tokens through a compound token scaling strategy, allowing up to a 16x increase in the token count post pre-training. Consequently, Chain-of-Sight requires significantly fewer visual tokens in the pre-training phase compared to the fine-tuning phase. This intentional reduction of visual tokens during pre-training notably accelerates the pre-training process, cutting down the wall-clock training time by ~73%. Empirical results on a series of vision-language benchmarks reveal that the pre-train acceleration through Chain-of-Sight is achieved without sacrificing performance, matching or surpassing the standard pipeline of utilizing all visual tokens throughout the entire training process. Further scaling up the number of visual tokens for pre-training leads to stronger performances, competitive to existing approaches in a series of benchmarks.
RoboCodeX: Multimodal Code Generation for Robotic Behavior Synthesis
Feb 25, 2024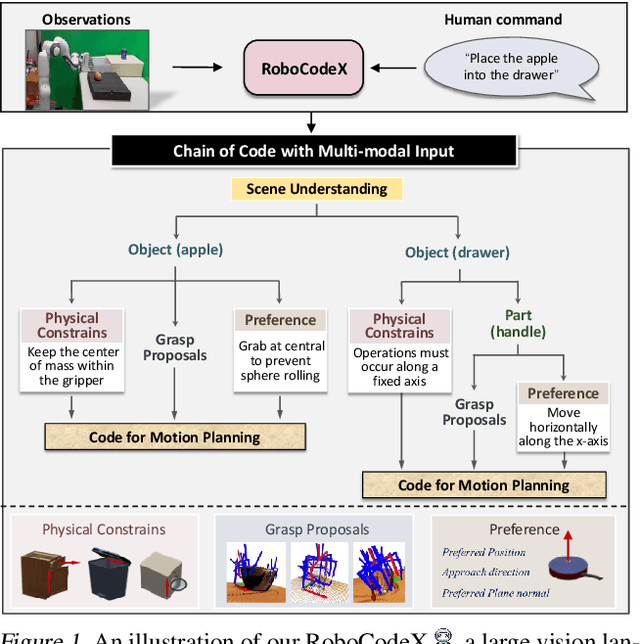
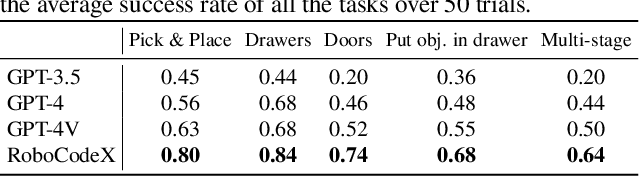
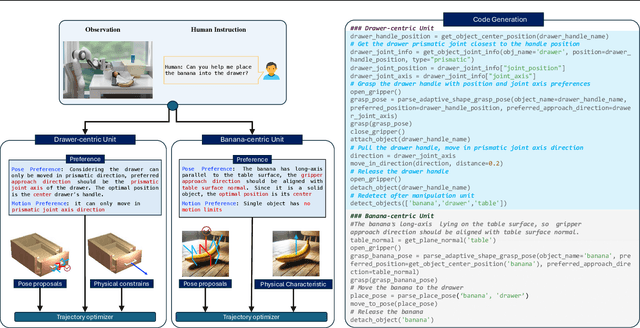

Robotic behavior synthesis, the problem of understanding multimodal inputs and generating precise physical control for robots, is an important part of Embodied AI. Despite successes in applying multimodal large language models for high-level understanding, it remains challenging to translate these conceptual understandings into detailed robotic actions while achieving generalization across various scenarios. In this paper, we propose a tree-structured multimodal code generation framework for generalized robotic behavior synthesis, termed RoboCodeX. RoboCodeX decomposes high-level human instructions into multiple object-centric manipulation units consisting of physical preferences such as affordance and safety constraints, and applies code generation to introduce generalization ability across various robotics platforms. To further enhance the capability to map conceptual and perceptual understanding into control commands, a specialized multimodal reasoning dataset is collected for pre-training and an iterative self-updating methodology is introduced for supervised fine-tuning. Extensive experiments demonstrate that RoboCodeX achieves state-of-the-art performance in both simulators and real robots on four different kinds of manipulation tasks and one navigation task.
InternVL: Scaling up Vision Foundation Models and Aligning for Generic Visual-Linguistic Tasks
Jan 15, 2024The exponential growth of large language models (LLMs) has opened up numerous possibilities for multimodal AGI systems. However, the progress in vision and vision-language foundation models, which are also critical elements of multi-modal AGI, has not kept pace with LLMs. In this work, we design a large-scale vision-language foundation model (InternVL), which scales up the vision foundation model to 6 billion parameters and progressively aligns it with the LLM, using web-scale image-text data from various sources. This model can be broadly applied to and achieve state-of-the-art performance on 32 generic visual-linguistic benchmarks including visual perception tasks such as image-level or pixel-level recognition, vision-language tasks such as zero-shot image/video classification, zero-shot image/video-text retrieval, and link with LLMs to create multi-modal dialogue systems. It has powerful visual capabilities and can be a good alternative to the ViT-22B. We hope that our research could contribute to the development of multi-modal large models. Code and models are available at https://github.com/OpenGVLab/InternVL.
EmbodiedGPT: Vision-Language Pre-Training via Embodied Chain of Thought
May 24, 2023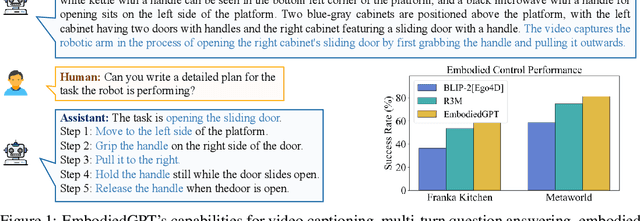

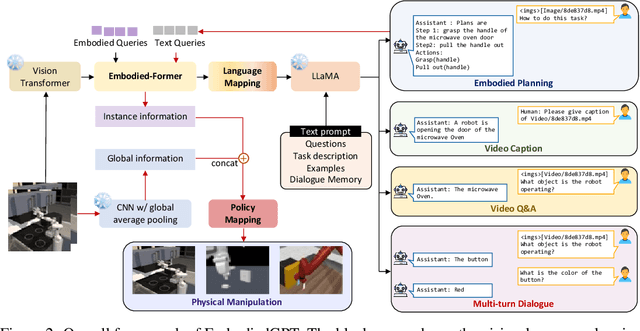

Embodied AI is a crucial frontier in robotics, capable of planning and executing action sequences for robots to accomplish long-horizon tasks in physical environments. In this work, we introduce EmbodiedGPT, an end-to-end multi-modal foundation model for embodied AI, empowering embodied agents with multi-modal understanding and execution capabilities. To achieve this, we have made the following efforts: (i) We craft a large-scale embodied planning dataset, termed EgoCOT. The dataset consists of carefully selected videos from the Ego4D dataset, along with corresponding high-quality language instructions. Specifically, we generate a sequence of sub-goals with the "Chain of Thoughts" mode for effective embodied planning. (ii) We introduce an efficient training approach to EmbodiedGPT for high-quality plan generation, by adapting a 7B large language model (LLM) to the EgoCOT dataset via prefix tuning. (iii) We introduce a paradigm for extracting task-related features from LLM-generated planning queries to form a closed loop between high-level planning and low-level control. Extensive experiments show the effectiveness of EmbodiedGPT on embodied tasks, including embodied planning, embodied control, visual captioning, and visual question answering. Notably, EmbodiedGPT significantly enhances the success rate of the embodied control task by extracting more effective features. It has achieved a remarkable 1.6 times increase in success rate on the Franka Kitchen benchmark and a 1.3 times increase on the Meta-World benchmark, compared to the BLIP-2 baseline fine-tuned with the Ego4D dataset.
InternGPT: Solving Vision-Centric Tasks by Interacting with ChatGPT Beyond Language
May 11, 2023



We present an interactive visual framework named InternGPT, or iGPT for short. The framework integrates chatbots that have planning and reasoning capabilities, such as ChatGPT, with non-verbal instructions like pointing movements that enable users to directly manipulate images or videos on the screen. Pointing (including gestures, cursors, etc.) movements can provide more flexibility and precision in performing vision-centric tasks that require fine-grained control, editing, and generation of visual content. The name InternGPT stands for \textbf{inter}action, \textbf{n}onverbal, and \textbf{chat}bots. Different from existing interactive systems that rely on pure language, by incorporating pointing instructions, the proposed iGPT significantly improves the efficiency of communication between users and chatbots, as well as the accuracy of chatbots in vision-centric tasks, especially in complicated visual scenarios where the number of objects is greater than 2. Additionally, in iGPT, an auxiliary control mechanism is used to improve the control capability of LLM, and a large vision-language model termed Husky is fine-tuned for high-quality multi-modal dialogue (impressing ChatGPT-3.5-turbo with 93.89\% GPT-4 Quality). We hope this work can spark new ideas and directions for future interactive visual systems. Welcome to watch the code at https://github.com/OpenGVLab/InternGPT.
FedKNOW: Federated Continual Learning with Signature Task Knowledge Integration at Edge
Dec 04, 2022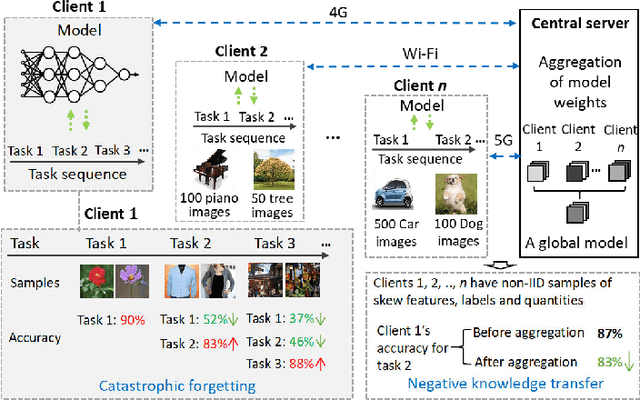
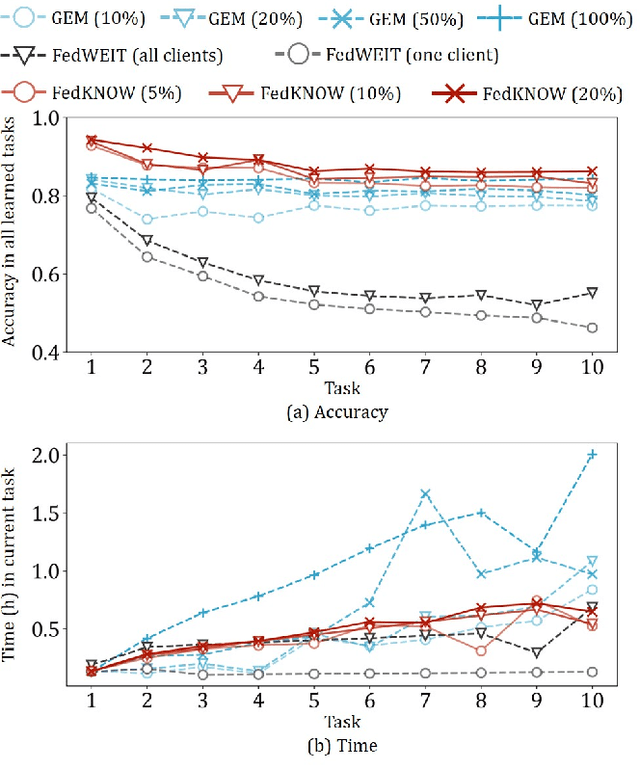
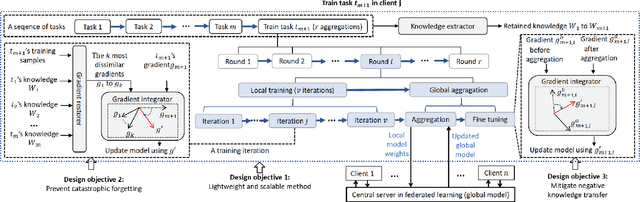
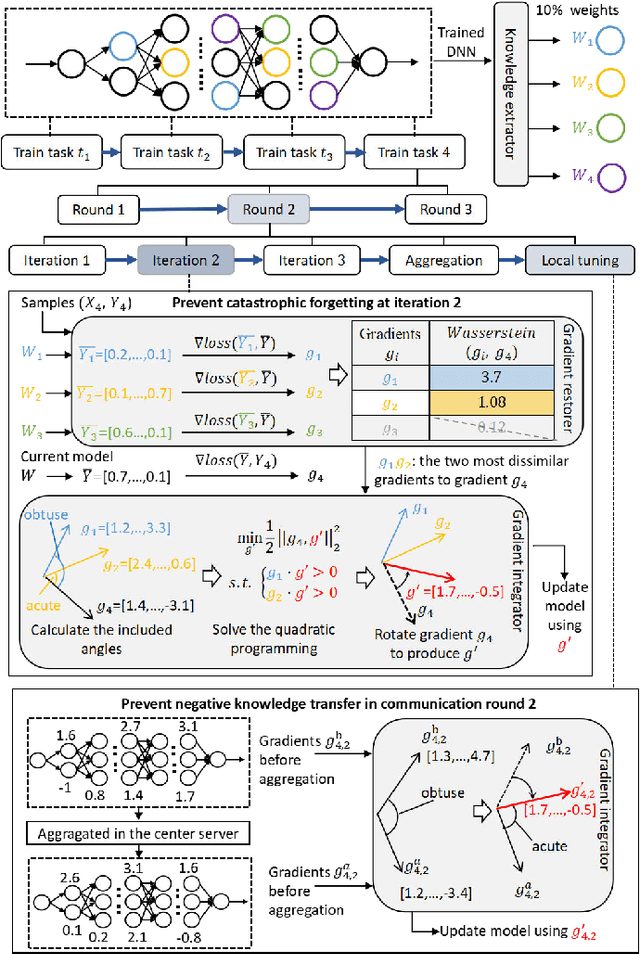
Deep Neural Networks (DNNs) have been ubiquitously adopted in internet of things and are becoming an integral of our daily life. When tackling the evolving learning tasks in real world, such as classifying different types of objects, DNNs face the challenge to continually retrain themselves according to the tasks on different edge devices. Federated continual learning is a promising technique that offers partial solutions but yet to overcome the following difficulties: the significant accuracy loss due to the limited on-device processing, the negative knowledge transfer caused by the limited communication of non-IID data, and the limited scalability on the tasks and edge devices. In this paper, we propose FedKNOW, an accurate and scalable federated continual learning framework, via a novel concept of signature task knowledge. FedKNOW is a client side solution that continuously extracts and integrates the knowledge of signature tasks which are highly influenced by the current task. Each client of FedKNOW is composed of a knowledge extractor, a gradient restorer and, most importantly, a gradient integrator. Upon training for a new task, the gradient integrator ensures the prevention of catastrophic forgetting and mitigation of negative knowledge transfer by effectively combining signature tasks identified from the past local tasks and other clients' current tasks through the global model. We implement FedKNOW in PyTorch and extensively evaluate it against state-of-the-art techniques using popular federated continual learning benchmarks. Extensive evaluation results on heterogeneous edge devices show that FedKNOW improves model accuracy by 63.24% without increasing model training time, reduces communication cost by 34.28%, and achieves more improvements under difficult scenarios such as large numbers of tasks or clients, and training different complex networks.
LegoDNN: Block-grained Scaling of Deep Neural Networks for Mobile Vision
Dec 18, 2021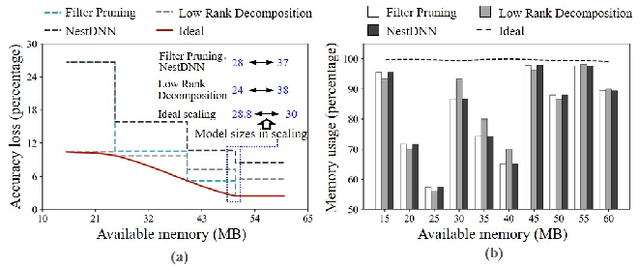
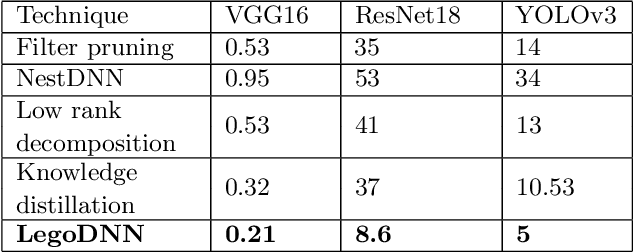
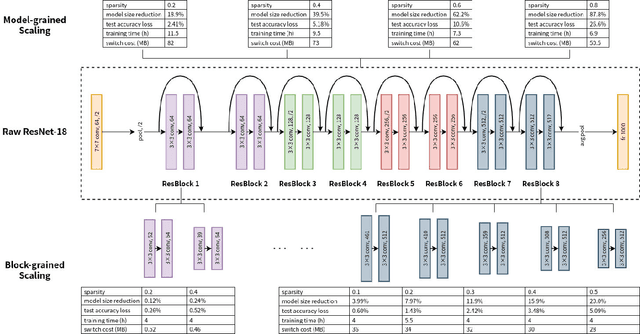
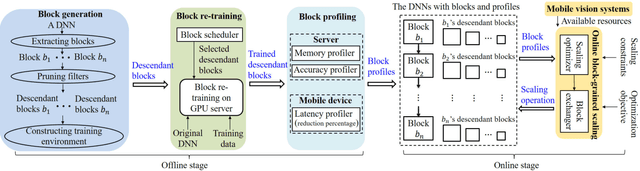
Deep neural networks (DNNs) have become ubiquitous techniques in mobile and embedded systems for applications such as image/object recognition and classification. The trend of executing multiple DNNs simultaneously exacerbate the existing limitations of meeting stringent latency/accuracy requirements on resource constrained mobile devices. The prior art sheds light on exploring the accuracy-resource tradeoff by scaling the model sizes in accordance to resource dynamics. However, such model scaling approaches face to imminent challenges: (i) large space exploration of model sizes, and (ii) prohibitively long training time for different model combinations. In this paper, we present LegoDNN, a lightweight, block-grained scaling solution for running multi-DNN workloads in mobile vision systems. LegoDNN guarantees short model training times by only extracting and training a small number of common blocks (e.g. 5 in VGG and 8 in ResNet) in a DNN. At run-time, LegoDNN optimally combines the descendant models of these blocks to maximize accuracy under specific resources and latency constraints, while reducing switching overhead via smart block-level scaling of the DNN. We implement LegoDNN in TensorFlow Lite and extensively evaluate it against state-of-the-art techniques (FLOP scaling, knowledge distillation and model compression) using a set of 12 popular DNN models. Evaluation results show that LegoDNN provides 1,296x to 279,936x more options in model sizes without increasing training time, thus achieving as much as 31.74% improvement in inference accuracy and 71.07% reduction in scaling energy consumptions.
* 13 pages, 15 figures
ResT: An Efficient Transformer for Visual Recognition
Jun 06, 2021
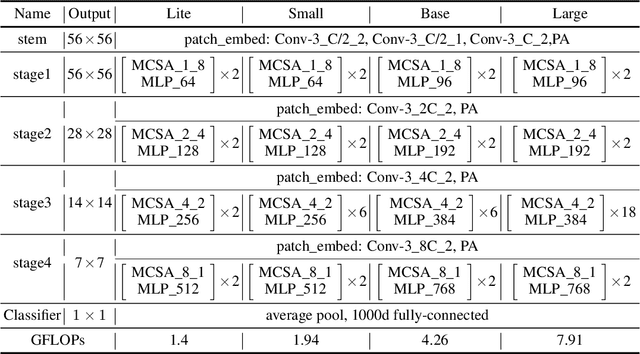


This paper presents an efficient multi-scale vision Transformer, called ResT, that capably served as a general-purpose backbone for image recognition. Unlike existing Transformer methods, which employ standard Transformer blocks to tackle raw images with a fixed resolution, our ResT have several advantages: (1) A memory-efficient multi-head self-attention is built, which compresses the memory by a simple depth-wise convolution, and projects the interaction across the attention-heads dimension while keeping the diversity ability of multi-heads; (2) Position encoding is constructed as spatial attention, which is more flexible and can tackle with input images of arbitrary size without interpolation or fine-tune; (3) Instead of the straightforward tokenization at the beginning of each stage, we design the patch embedding as a stack of overlapping convolution operation with stride on the 2D-reshaped token map. We comprehensively validate ResT on image classification and downstream tasks. Experimental results show that the proposed ResT can outperform the recently state-of-the-art backbones by a large margin, demonstrating the potential of ResT as strong backbones. The code and models will be made publicly available at https://github.com/wofmanaf/ResT.