 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTreeNet: A lightweight One-Shot Aggregation Convolutional Network
Sep 29, 2021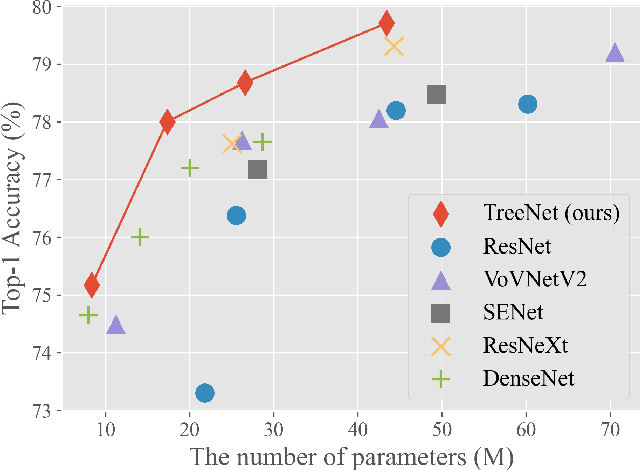
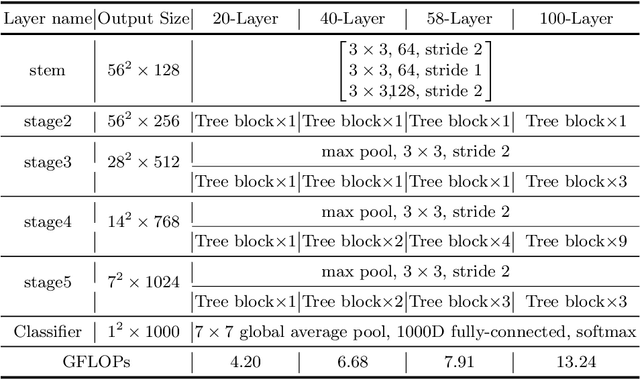
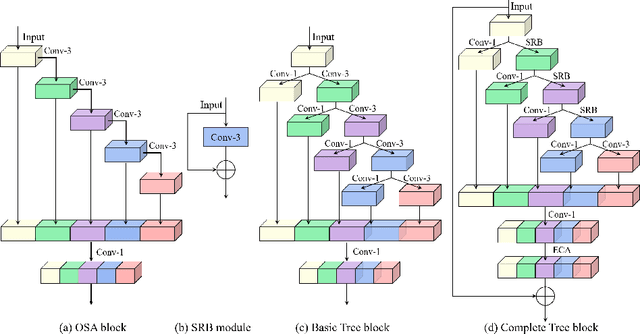
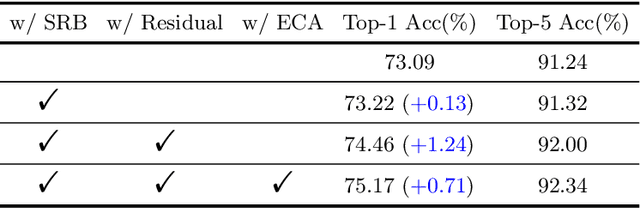
The architecture of deep convolutional networks (CNNs) has evolved for years, becoming more accurate and faster. However, it is still challenging to design reasonable network structures that aim at obtaining the best accuracy under a limited computational budget. In this paper, we propose a Tree block, named after its appearance, which extends the One-Shot Aggregation (OSA) module while being more lightweight and flexible. Specifically, the Tree block replaces each of the $3\times3$ Conv layers in OSA into a stack of shallow residual block (SRB) and $1\times1$ Conv layer. The $1\times1$ Conv layer is responsible for dimension increasing and the SRB is fed into the next step. By doing this, when aggregating the same number of subsequent feature maps, the Tree block has a deeper network structure while having less model complexity. In addition, residual connection and efficient channel attention(ECA) is added to the Tree block to further improve the performance of the network. Based on the Tree block, we build efficient backbone models calling TreeNets. TreeNet has a similar network architecture to ResNet, making it flexible to replace ResNet in various computer vision frameworks. We comprehensively evaluate TreeNet on common-used benchmarks, including ImageNet-1k for classification, MS COCO for object detection, and instance segmentation. Experimental results demonstrate that TreeNet is more efficient and performs favorably against the current state-of-the-art backbone methods.
Group-CAM: Group Score-Weighted Visual Explanations for Deep Convolutional Networks
Mar 26, 2021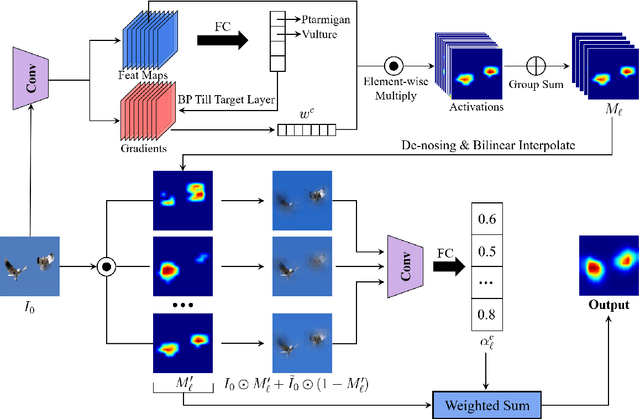

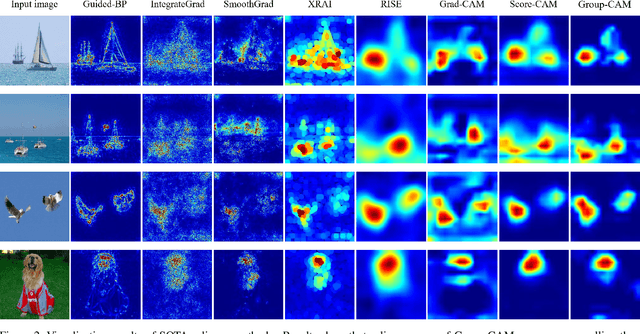
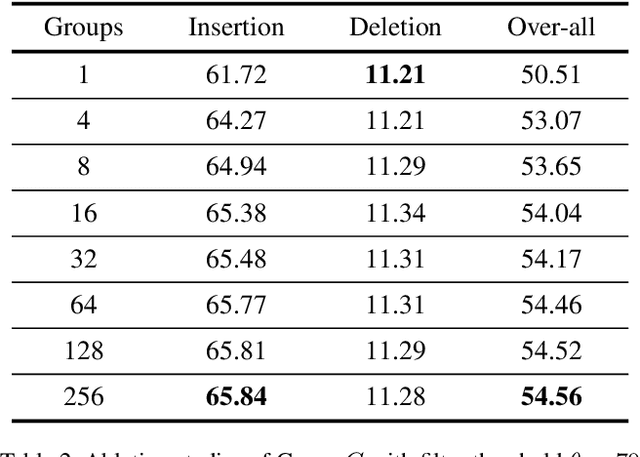
In this paper, we propose an efficient saliency map generation method, called Group score-weighted Class Activation Mapping (Group-CAM), which adopts the "split-transform-merge" strategy to generate saliency maps. Specifically, for an input image, the class activations are firstly split into groups. In each group, the sub-activations are summed and de-noised as an initial mask. After that, the initial masks are transformed with meaningful perturbations and then applied to preserve sub-pixels of the input (i.e., masked inputs), which are then fed into the network to calculate the confidence scores. Finally, the initial masks are weighted summed to form the final saliency map, where the weights are confidence scores produced by the masked inputs. Group-CAM is efficient yet effective, which only requires dozens of queries to the network while producing target-related saliency maps. As a result, Group-CAM can be served as an effective data augment trick for fine-tuning the networks. We comprehensively evaluate the performance of Group-CAM on common-used benchmarks, including deletion and insertion tests on ImageNet-1k, and pointing game tests on COCO2017. Extensive experimental results demonstrate that Group-CAM achieves better visual performance than the current state-of-the-art explanation approaches. The code is available at https://github.com/wofmanaf/Group-CAM.