 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeedance 1.0: Exploring the Boundaries of Video Generation Models
Jun 10, 2025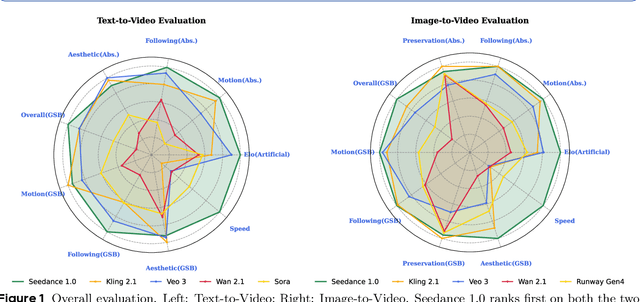
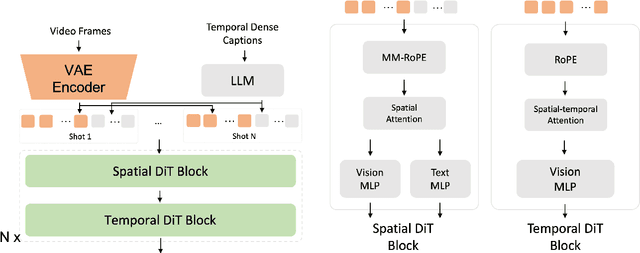
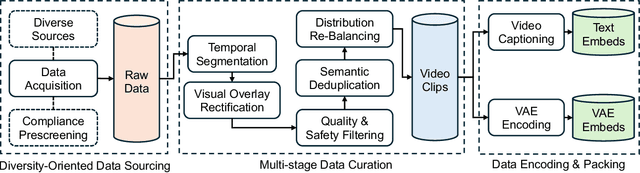
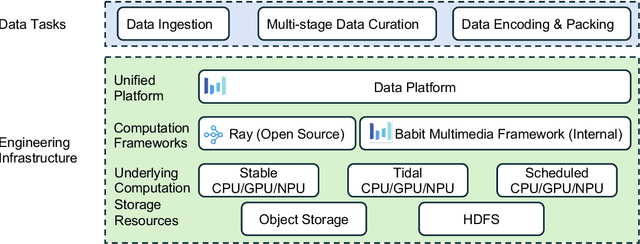
Notable breakthroughs in diffusion modeling have propelled rapid improvements in video generation, yet current foundational model still face critical challenges in simultaneously balancing prompt following, motion plausibility, and visual quality. In this report, we introduce Seedance 1.0, a high-performance and inference-efficient video foundation generation model that integrates several core technical improvements: (i) multi-source data curation augmented with precision and meaningful video captioning, enabling comprehensive learning across diverse scenarios; (ii) an efficient architecture design with proposed training paradigm, which allows for natively supporting multi-shot generation and jointly learning of both text-to-video and image-to-video tasks. (iii) carefully-optimized post-training approaches leveraging fine-grained supervised fine-tuning, and video-specific RLHF with multi-dimensional reward mechanisms for comprehensive performance improvements; (iv) excellent model acceleration achieving ~10x inference speedup through multi-stage distillation strategies and system-level optimizations. Seedance 1.0 can generate a 5-second video at 1080p resolution only with 41.4 seconds (NVIDIA-L20). Compared to state-of-the-art video generation models, Seedance 1.0 stands out with high-quality and fast video generation having superior spatiotemporal fluidity with structural stability, precise instruction adherence in complex multi-subject contexts, native multi-shot narrative coherence with consistent subject representation.
Seaweed-7B: Cost-Effective Training of Video Generation Foundation Model
Apr 11, 2025
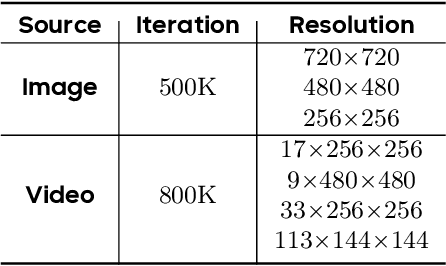
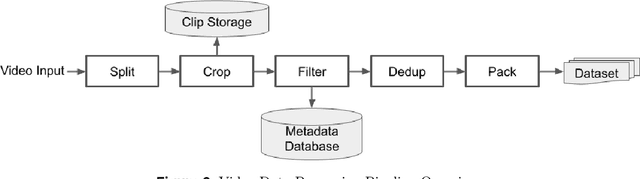

This technical report presents a cost-efficient strategy for training a video generation foundation model. We present a mid-sized research model with approximately 7 billion parameters (7B) called Seaweed-7B trained from scratch using 665,000 H100 GPU hours. Despite being trained with moderate computational resources, Seaweed-7B demonstrates highly competitive performance compared to contemporary video generation models of much larger size. Design choices are especially crucial in a resource-constrained setting. This technical report highlights the key design decisions that enhance the performance of the medium-sized diffusion model. Empirically, we make two observations: (1) Seaweed-7B achieves performance comparable to, or even surpasses, larger models trained on substantially greater GPU resources, and (2) our model, which exhibits strong generalization ability, can be effectively adapted across a wide range of downstream applications either by lightweight fine-tuning or continue training. See the project page at https://seaweed.video/
Accelerating Pre-training of Multimodal LLMs via Chain-of-Sight
Jul 22, 2024

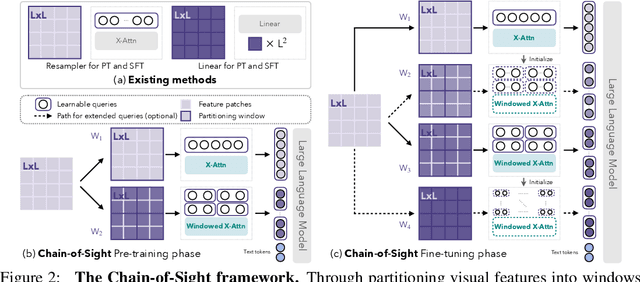

This paper introduces Chain-of-Sight, a vision-language bridge module that accelerates the pre-training of Multimodal Large Language Models (MLLMs). Our approach employs a sequence of visual resamplers that capture visual details at various spacial scales. This architecture not only leverages global and local visual contexts effectively, but also facilitates the flexible extension of visual tokens through a compound token scaling strategy, allowing up to a 16x increase in the token count post pre-training. Consequently, Chain-of-Sight requires significantly fewer visual tokens in the pre-training phase compared to the fine-tuning phase. This intentional reduction of visual tokens during pre-training notably accelerates the pre-training process, cutting down the wall-clock training time by ~73%. Empirical results on a series of vision-language benchmarks reveal that the pre-train acceleration through Chain-of-Sight is achieved without sacrificing performance, matching or surpassing the standard pipeline of utilizing all visual tokens throughout the entire training process. Further scaling up the number of visual tokens for pre-training leads to stronger performances, competitive to existing approaches in a series of benchmarks.
A Recipe for Scaling up Text-to-Video Generation with Text-free Videos
Dec 25, 2023
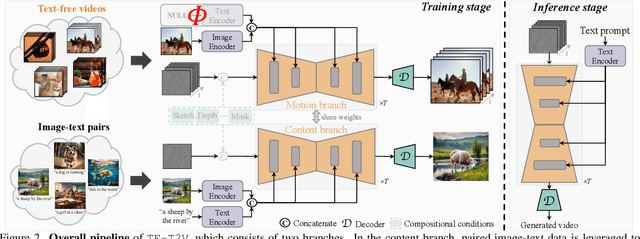
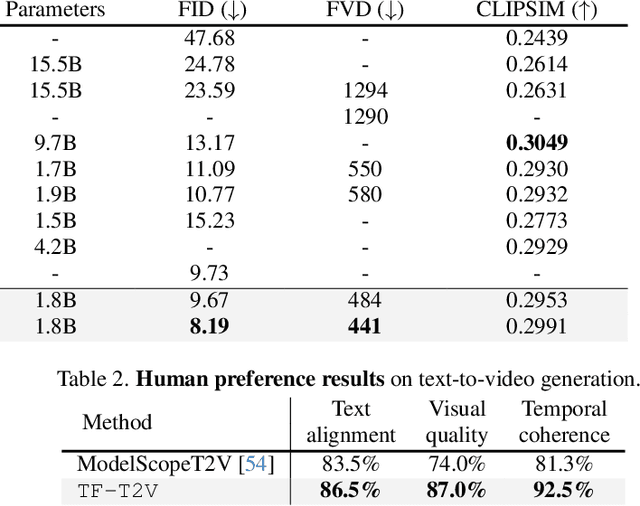

Diffusion-based text-to-video generation has witnessed impressive progress in the past year yet still falls behind text-to-image generation. One of the key reasons is the limited scale of publicly available data (e.g., 10M video-text pairs in WebVid10M vs. 5B image-text pairs in LAION), considering the high cost of video captioning. Instead, it could be far easier to collect unlabeled clips from video platforms like YouTube. Motivated by this, we come up with a novel text-to-video generation framework, termed TF-T2V, which can directly learn with text-free videos. The rationale behind is to separate the process of text decoding from that of temporal modeling. To this end, we employ a content branch and a motion branch, which are jointly optimized with weights shared. Following such a pipeline, we study the effect of doubling the scale of training set (i.e., video-only WebVid10M) with some randomly collected text-free videos and are encouraged to observe the performance improvement (FID from 9.67 to 8.19 and FVD from 484 to 441), demonstrating the scalability of our approach. We also find that our model could enjoy sustainable performance gain (FID from 8.19 to 7.64 and FVD from 441 to 366) after reintroducing some text labels for training. Finally, we validate the effectiveness and generalizability of our ideology on both native text-to-video generation and compositional video synthesis paradigms. Code and models will be publicly available at https://tf-t2v.github.io/.
DreamVideo: Composing Your Dream Videos with Customized Subject and Motion
Dec 07, 2023Customized generation using diffusion models has made impressive progress in image generation, but remains unsatisfactory in the challenging video generation task, as it requires the controllability of both subjects and motions. To that end, we present DreamVideo, a novel approach to generating personalized videos from a few static images of the desired subject and a few videos of target motion. DreamVideo decouples this task into two stages, subject learning and motion learning, by leveraging a pre-trained video diffusion model. The subject learning aims to accurately capture the fine appearance of the subject from provided images, which is achieved by combining textual inversion and fine-tuning of our carefully designed identity adapter. In motion learning, we architect a motion adapter and fine-tune it on the given videos to effectively model the target motion pattern. Combining these two lightweight and efficient adapters allows for flexible customization of any subject with any motion. Extensive experimental results demonstrate the superior performance of our DreamVideo over the state-of-the-art methods for customized video generation. Our project page is at https://dreamvideo-t2v.github.io.
Hierarchical Spatio-temporal Decoupling for Text-to-Video Generation
Dec 07, 2023
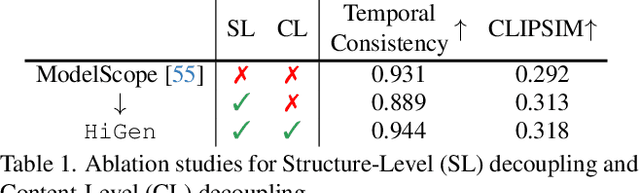
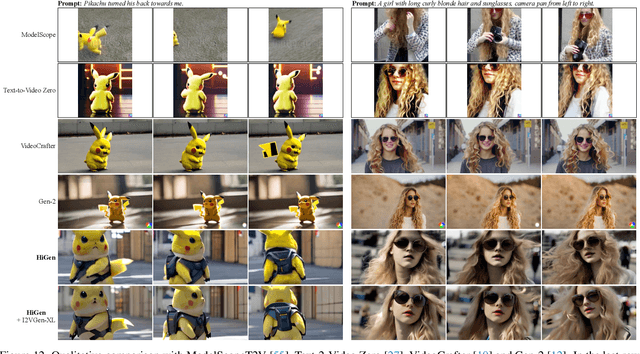

Despite diffusion models having shown powerful abilities to generate photorealistic images, generating videos that are realistic and diverse still remains in its infancy. One of the key reasons is that current methods intertwine spatial content and temporal dynamics together, leading to a notably increased complexity of text-to-video generation (T2V). In this work, we propose HiGen, a diffusion model-based method that improves performance by decoupling the spatial and temporal factors of videos from two perspectives, i.e., structure level and content level. At the structure level, we decompose the T2V task into two steps, including spatial reasoning and temporal reasoning, using a unified denoiser. Specifically, we generate spatially coherent priors using text during spatial reasoning and then generate temporally coherent motions from these priors during temporal reasoning. At the content level, we extract two subtle cues from the content of the input video that can express motion and appearance changes, respectively. These two cues then guide the model's training for generating videos, enabling flexible content variations and enhancing temporal stability. Through the decoupled paradigm, HiGen can effectively reduce the complexity of this task and generate realistic videos with semantics accuracy and motion stability. Extensive experiments demonstrate the superior performance of HiGen over the state-of-the-art T2V methods.
Disentangling Spatial and Temporal Learning for Efficient Image-to-Video Transfer Learning
Sep 14, 2023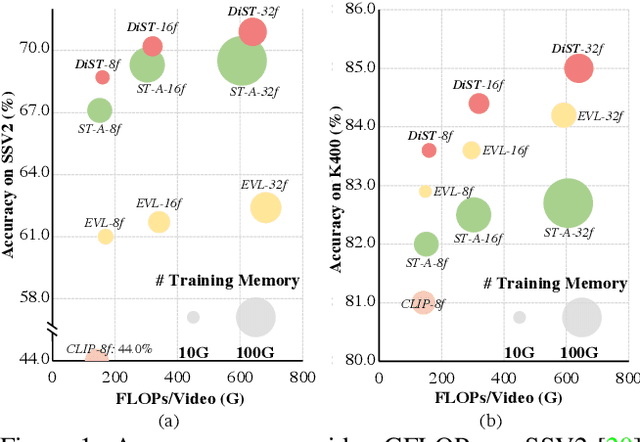
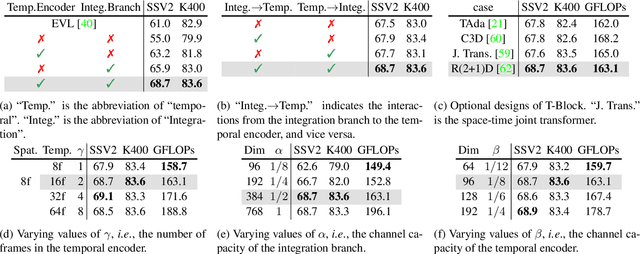

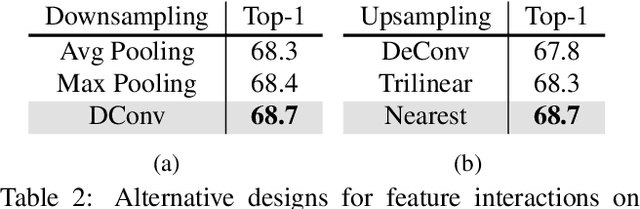
Recently, large-scale pre-trained language-image models like CLIP have shown extraordinary capabilities for understanding spatial contents, but naively transferring such models to video recognition still suffers from unsatisfactory temporal modeling capabilities. Existing methods insert tunable structures into or in parallel with the pre-trained model, which either requires back-propagation through the whole pre-trained model and is thus resource-demanding, or is limited by the temporal reasoning capability of the pre-trained structure. In this work, we present DiST, which disentangles the learning of spatial and temporal aspects of videos. Specifically, DiST uses a dual-encoder structure, where a pre-trained foundation model acts as the spatial encoder, and a lightweight network is introduced as the temporal encoder. An integration branch is inserted between the encoders to fuse spatio-temporal information. The disentangled spatial and temporal learning in DiST is highly efficient because it avoids the back-propagation of massive pre-trained parameters. Meanwhile, we empirically show that disentangled learning with an extra network for integration benefits both spatial and temporal understanding. Extensive experiments on five benchmarks show that DiST delivers better performance than existing state-of-the-art methods by convincing gaps. When pre-training on the large-scale Kinetics-710, we achieve 89.7% on Kinetics-400 with a frozen ViT-L model, which verifies the scalability of DiST. Codes and models can be found in https://github.com/alibaba-mmai-research/DiST.
HR-Pro: Point-supervised Temporal Action Localization via Hierarchical Reliability Propagation
Aug 24, 2023



Point-supervised Temporal Action Localization (PSTAL) is an emerging research direction for label-efficient learning. However, current methods mainly focus on optimizing the network either at the snippet-level or the instance-level, neglecting the inherent reliability of point annotations at both levels. In this paper, we propose a Hierarchical Reliability Propagation (HR-Pro) framework, which consists of two reliability-aware stages: Snippet-level Discrimination Learning and Instance-level Completeness Learning, both stages explore the efficient propagation of high-confidence cues in point annotations. For snippet-level learning, we introduce an online-updated memory to store reliable snippet prototypes for each class. We then employ a Reliability-aware Attention Block to capture both intra-video and inter-video dependencies of snippets, resulting in more discriminative and robust snippet representation. For instance-level learning, we propose a point-based proposal generation approach as a means of connecting snippets and instances, which produces high-confidence proposals for further optimization at the instance level. Through multi-level reliability-aware learning, we obtain more reliable confidence scores and more accurate temporal boundaries of predicted proposals. Our HR-Pro achieves state-of-the-art performance on multiple challenging benchmarks, including an impressive average mAP of 60.3% on THUMOS14. Notably, our HR-Pro largely surpasses all previous point-supervised methods, and even outperforms several competitive fully supervised methods. Code will be available at https://github.com/pipixin321/HR-Pro.
Temporally-Adaptive Models for Efficient Video Understanding
Aug 10, 2023Spatial convolutions are extensively used in numerous deep video models. It fundamentally assumes spatio-temporal invariance, i.e., using shared weights for every location in different frames. This work presents Temporally-Adaptive Convolutions (TAdaConv) for video understanding, which shows that adaptive weight calibration along the temporal dimension is an efficient way to facilitate modeling complex temporal dynamics in videos. Specifically, TAdaConv empowers spatial convolutions with temporal modeling abilities by calibrating the convolution weights for each frame according to its local and global temporal context. Compared to existing operations for temporal modeling, TAdaConv is more efficient as it operates over the convolution kernels instead of the features, whose dimension is an order of magnitude smaller than the spatial resolutions. Further, kernel calibration brings an increased model capacity. Based on this readily plug-in operation TAdaConv as well as its extension, i.e., TAdaConvV2, we construct TAdaBlocks to empower ConvNeXt and Vision Transformer to have strong temporal modeling capabilities. Empirical results show TAdaConvNeXtV2 and TAdaFormer perform competitively against state-of-the-art convolutional and Transformer-based models in various video understanding benchmarks. Our codes and models are released at: https://github.com/alibaba-mmai-research/TAdaConv.
MoLo: Motion-augmented Long-short Contrastive Learning for Few-shot Action Recognition
Apr 03, 2023Current state-of-the-art approaches for few-shot action recognition achieve promising performance by conducting frame-level matching on learned visual features. However, they generally suffer from two limitations: i) the matching procedure between local frames tends to be inaccurate due to the lack of guidance to force long-range temporal perception; ii) explicit motion learning is usually ignored, leading to partial information loss. To address these issues, we develop a Motion-augmented Long-short Contrastive Learning (MoLo) method that contains two crucial components, including a long-short contrastive objective and a motion autodecoder. Specifically, the long-short contrastive objective is to endow local frame features with long-form temporal awareness by maximizing their agreement with the global token of videos belonging to the same class. The motion autodecoder is a lightweight architecture to reconstruct pixel motions from the differential features, which explicitly embeds the network with motion dynamics. By this means, MoLo can simultaneously learn long-range temporal context and motion cues for comprehensive few-shot matching. To demonstrate the effectiveness, we evaluate MoLo on five standard benchmarks, and the results show that MoLo favorably outperforms recent advanced methods. The source code is available at https://github.com/alibaba-mmai-research/MoLo.