 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeedance 1.0: Exploring the Boundaries of Video Generation Models
Jun 10, 2025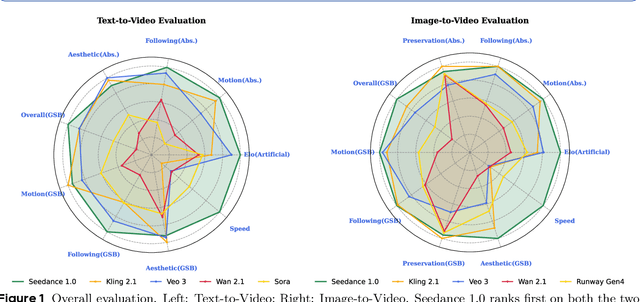
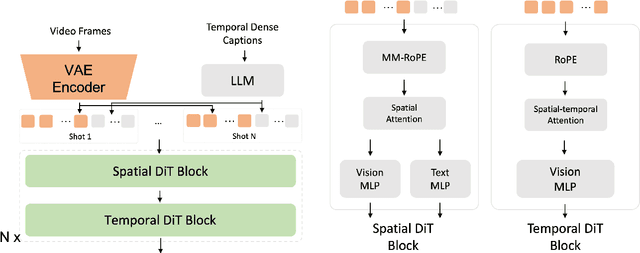
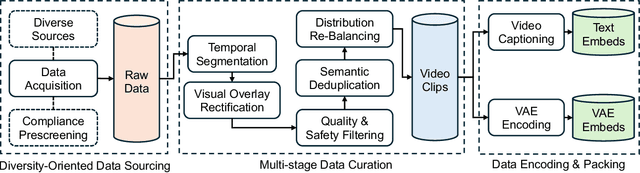
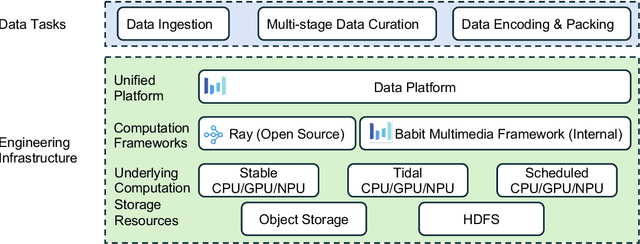
Notable breakthroughs in diffusion modeling have propelled rapid improvements in video generation, yet current foundational model still face critical challenges in simultaneously balancing prompt following, motion plausibility, and visual quality. In this report, we introduce Seedance 1.0, a high-performance and inference-efficient video foundation generation model that integrates several core technical improvements: (i) multi-source data curation augmented with precision and meaningful video captioning, enabling comprehensive learning across diverse scenarios; (ii) an efficient architecture design with proposed training paradigm, which allows for natively supporting multi-shot generation and jointly learning of both text-to-video and image-to-video tasks. (iii) carefully-optimized post-training approaches leveraging fine-grained supervised fine-tuning, and video-specific RLHF with multi-dimensional reward mechanisms for comprehensive performance improvements; (iv) excellent model acceleration achieving ~10x inference speedup through multi-stage distillation strategies and system-level optimizations. Seedance 1.0 can generate a 5-second video at 1080p resolution only with 41.4 seconds (NVIDIA-L20). Compared to state-of-the-art video generation models, Seedance 1.0 stands out with high-quality and fast video generation having superior spatiotemporal fluidity with structural stability, precise instruction adherence in complex multi-subject contexts, native multi-shot narrative coherence with consistent subject representation.
Seaweed-7B: Cost-Effective Training of Video Generation Foundation Model
Apr 11, 2025
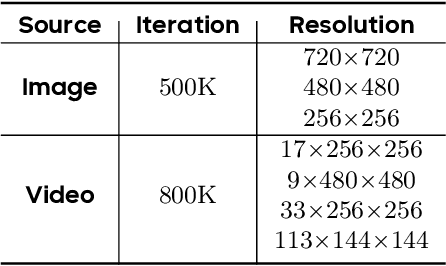
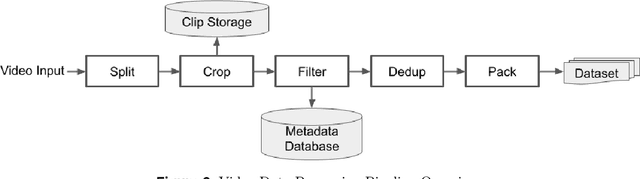

This technical report presents a cost-efficient strategy for training a video generation foundation model. We present a mid-sized research model with approximately 7 billion parameters (7B) called Seaweed-7B trained from scratch using 665,000 H100 GPU hours. Despite being trained with moderate computational resources, Seaweed-7B demonstrates highly competitive performance compared to contemporary video generation models of much larger size. Design choices are especially crucial in a resource-constrained setting. This technical report highlights the key design decisions that enhance the performance of the medium-sized diffusion model. Empirically, we make two observations: (1) Seaweed-7B achieves performance comparable to, or even surpasses, larger models trained on substantially greater GPU resources, and (2) our model, which exhibits strong generalization ability, can be effectively adapted across a wide range of downstream applications either by lightweight fine-tuning or continue training. See the project page at https://seaweed.video/
UVE: Are MLLMs Unified Evaluators for AI-Generated Videos?
Mar 13, 2025With the rapid growth of video generative models (VGMs), it is essential to develop reliable and comprehensive automatic metrics for AI-generated videos (AIGVs). Existing methods either use off-the-shelf models optimized for other tasks or rely on human assessment data to train specialized evaluators. These approaches are constrained to specific evaluation aspects and are difficult to scale with the increasing demands for finer-grained and more comprehensive evaluations. To address this issue, this work investigates the feasibility of using multimodal large language models (MLLMs) as a unified evaluator for AIGVs, leveraging their strong visual perception and language understanding capabilities. To evaluate the performance of automatic metrics in unified AIGV evaluation, we introduce a benchmark called UVE-Bench. UVE-Bench collects videos generated by state-of-the-art VGMs and provides pairwise human preference annotations across 15 evaluation aspects. Using UVE-Bench, we extensively evaluate 16 MLLMs. Our empirical results suggest that while advanced MLLMs (e.g., Qwen2VL-72B and InternVL2.5-78B) still lag behind human evaluators, they demonstrate promising ability in unified AIGV evaluation, significantly surpassing existing specialized evaluation methods. Additionally, we conduct an in-depth analysis of key design choices that impact the performance of MLLM-driven evaluators, offering valuable insights for future research on AIGV evaluation. The code is available at https://github.com/bytedance/UVE.
Parallelized Autoregressive Visual Generation
Dec 19, 2024



Autoregressive models have emerged as a powerful approach for visual generation but suffer from slow inference speed due to their sequential token-by-token prediction process. In this paper, we propose a simple yet effective approach for parallelized autoregressive visual generation that improves generation efficiency while preserving the advantages of autoregressive modeling. Our key insight is that parallel generation depends on visual token dependencies-tokens with weak dependencies can be generated in parallel, while strongly dependent adjacent tokens are difficult to generate together, as their independent sampling may lead to inconsistencies. Based on this observation, we develop a parallel generation strategy that generates distant tokens with weak dependencies in parallel while maintaining sequential generation for strongly dependent local tokens. Our approach can be seamlessly integrated into standard autoregressive models without modifying the architecture or tokenizer. Experiments on ImageNet and UCF-101 demonstrate that our method achieves a 3.6x speedup with comparable quality and up to 9.5x speedup with minimal quality degradation across both image and video generation tasks. We hope this work will inspire future research in efficient visual generation and unified autoregressive modeling. Project page: https://epiphqny.github.io/PAR-project.
World to Code: Multi-modal Data Generation via Self-Instructed Compositional Captioning and Filtering
Sep 30, 2024



Recent advances in Vision-Language Models (VLMs) and the scarcity of high-quality multi-modal alignment data have inspired numerous researches on synthetic VLM data generation. The conventional norm in VLM data construction uses a mixture of specialists in caption and OCR, or stronger VLM APIs and expensive human annotation. In this paper, we present World to Code (W2C), a meticulously curated multi-modal data construction pipeline that organizes the final generation output into a Python code format. The pipeline leverages the VLM itself to extract cross-modal information via different prompts and filter the generated outputs again via a consistency filtering strategy. Experiments have demonstrated the high quality of W2C by improving various existing visual question answering and visual grounding benchmarks across different VLMs. Further analysis also demonstrates that the new code parsing ability of VLMs presents better cross-modal equivalence than the commonly used detail caption ability. Our code is available at https://github.com/foundation-multimodal-models/World2Code.
Benchmarking and Improving Detail Image Caption
May 29, 2024



Image captioning has long been regarded as a fundamental task in visual understanding. Recently, however, few large vision-language model (LVLM) research discusses model's image captioning performance because of the outdated short-caption benchmarks and unreliable evaluation metrics. In this work, we propose to benchmark detail image caption task by curating high-quality evaluation datasets annotated by human experts, GPT-4V and Gemini-1.5-Pro. We also design a more reliable caption evaluation metric called CAPTURE (CAPtion evaluation by exTracting and coUpling coRE information). CAPTURE extracts visual elements, e.g., objects, attributes and relations from captions, and then matches these elements through three stages, achieving the highest consistency with expert judgements over other rule-based or model-based caption metrics. The proposed benchmark and metric provide reliable evaluation for LVLM's detailed image captioning ability. Guided by this evaluation, we further explore to unleash LVLM's detail caption capabilities by synthesizing high-quality data through a five-stage data construction pipeline. Our pipeline only uses a given LVLM itself and other open-source tools, without any human or GPT-4V annotation in the loop. Experiments show that the proposed data construction strategy significantly improves model-generated detail caption data quality for LVLMs with leading performance, and the data quality can be further improved in a self-looping paradigm. All code and dataset will be publicly available at https://github.com/foundation-multimodal-models/CAPTURE.
Seeing the Image: Prioritizing Visual Correlation by Contrastive Alignment
May 28, 2024



Existing image-text modality alignment in Vision Language Models (VLMs) treats each text token equally in an autoregressive manner. Despite being simple and effective, this method results in sub-optimal cross-modal alignment by over-emphasizing the text tokens that are less correlated with or even contradictory with the input images. In this paper, we advocate for assigning distinct contributions for each text token based on its visual correlation. Specifically, we present by contrasting image inputs, the difference in prediction logits on each text token provides strong guidance of visual correlation. We therefore introduce Contrastive ALignment (CAL), a simple yet effective re-weighting strategy that prioritizes training visually correlated tokens. Our experimental results demonstrate that CAL consistently improves different types of VLMs across different resolutions and model sizes on various benchmark datasets. Importantly, our method incurs minimal additional computational overhead, rendering it highly efficient compared to alternative data scaling strategies. Codes are available at https://github.com/foundation-multimodal-models/CAL.
Unveiling the Tapestry of Consistency in Large Vision-Language Models
May 23, 2024Large vision-language models (LVLMs) have recently achieved rapid progress, exhibiting great perception and reasoning abilities concerning visual information. However, when faced with prompts in different sizes of solution spaces, LVLMs fail to always give consistent answers regarding the same knowledge point. This inconsistency of answers between different solution spaces is prevalent in LVLMs and erodes trust. To this end, we provide a multi-modal benchmark ConBench, to intuitively analyze how LVLMs perform when the solution space of a prompt revolves around a knowledge point. Based on the ConBench tool, we are the first to reveal the tapestry and get the following findings: (1) In the discriminate realm, the larger the solution space of the prompt, the lower the accuracy of the answers. (2) Establish the relationship between the discriminative and generative realms: the accuracy of the discriminative question type exhibits a strong positive correlation with its Consistency with the caption. (3) Compared to open-source models, closed-source models exhibit a pronounced bias advantage in terms of Consistency. Eventually, we ameliorate the consistency of LVLMs by trigger-based diagnostic refinement, indirectly improving the performance of their caption. We hope this paper will accelerate the research community in better evaluating their models and encourage future advancements in the consistency domain.