 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAMTok: Representing Any Mask with Two Words
Jan 22, 2026Pixel-wise capabilities are essential for building interactive intelligent systems. However, pixel-wise multi-modal LLMs (MLLMs) remain difficult to scale due to complex region-level encoders, specialized segmentation decoders, and incompatible training objectives. To address these challenges, we present SAMTok, a discrete mask tokenizer that converts any region mask into two special tokens and reconstructs the mask using these tokens with high fidelity. By treating masks as new language tokens, SAMTok enables base MLLMs (such as the QwenVL series) to learn pixel-wise capabilities through standard next-token prediction and simple reinforcement learning, without architectural modifications and specialized loss design. SAMTok builds on SAM2 and is trained on 209M diverse masks using a mask encoder and residual vector quantizer to produce discrete, compact, and information-rich tokens. With 5M SAMTok-formatted mask understanding and generation data samples, QwenVL-SAMTok attains state-of-the-art or comparable results on region captioning, region VQA, grounded conversation, referring segmentation, scene graph parsing, and multi-round interactive segmentation. We further introduce a textual answer-matching reward that enables efficient reinforcement learning for mask generation, delivering substantial improvements on GRES and GCG benchmarks. Our results demonstrate a scalable and straightforward paradigm for equipping MLLMs with strong pixel-wise capabilities. Our code and models are available.
Grasp Any Region: Towards Precise, Contextual Pixel Understanding for Multimodal LLMs
Oct 22, 2025While Multimodal Large Language Models (MLLMs) excel at holistic understanding, they struggle in capturing the dense world with complex scenes, requiring fine-grained analysis of intricate details and object inter-relationships. Region-level MLLMs have been a promising step. However, previous attempts are generally optimized to understand given regions in isolation, neglecting crucial global contexts. To address this, we introduce Grasp Any Region (GAR) for comprehen- sive region-level visual understanding. Empowered by an effective RoI-aligned feature replay technique, GAR supports (1) precise perception by leveraging necessary global contexts, and (2) modeling interactions between multiple prompts. Together, it then naturally achieves (3) advanced compositional reasoning to answer specific free-form questions about any region, shifting the paradigm from passive description to active dialogue. Moreover, we construct GAR-Bench, which not only provides a more accurate evaluation of single-region comprehension, but also, more importantly, measures interactions and complex reasoning across multiple regions. Extensive experiments have demonstrated that GAR-1B not only maintains the state-of-the-art captioning capabilities, e.g., outperforming DAM-3B +4.5 on DLC-Bench, but also excels at modeling relationships between multiple prompts with advanced comprehension capabilities, even surpassing InternVL3-78B on GAR-Bench-VQA. More importantly, our zero-shot GAR-8B even outperforms in-domain VideoRefer-7B on VideoRefer-BenchQ, indicating its strong capabilities can be easily transferred to videos.
SAIL-VL2 Technical Report
Sep 18, 2025We introduce SAIL-VL2, an open-suite vision-language foundation model (LVM) for comprehensive multimodal understanding and reasoning. As the successor to SAIL-VL, SAIL-VL2 achieves state-of-the-art performance at the 2B and 8B parameter scales across diverse image and video benchmarks, demonstrating strong capabilities from fine-grained perception to complex reasoning. Its effectiveness is driven by three core innovations. First, a large-scale data curation pipeline with scoring and filtering strategies enhances both quality and distribution across captioning, OCR, QA, and video data, improving training efficiency. Second, a progressive training framework begins with a powerful pre-trained vision encoder (SAIL-ViT), advances through multimodal pre-training, and culminates in a thinking-fusion SFT-RL hybrid paradigm that systematically strengthens model capabilities. Third, architectural advances extend beyond dense LLMs to efficient sparse Mixture-of-Experts (MoE) designs. With these contributions, SAIL-VL2 demonstrates competitive performance across 106 datasets and achieves state-of-the-art results on challenging reasoning benchmarks such as MMMU and MathVista. Furthermore, on the OpenCompass leaderboard, SAIL-VL2-2B ranks first among officially released open-source models under the 4B parameter scale, while serving as an efficient and extensible foundation for the open-source multimodal community.
Traceable Evidence Enhanced Visual Grounded Reasoning: Evaluation and Methodology
Jul 10, 2025

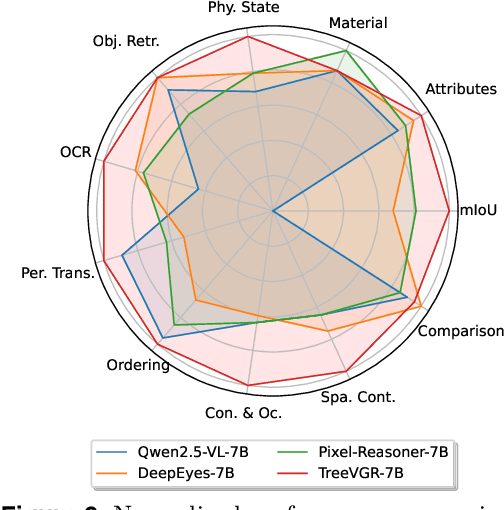
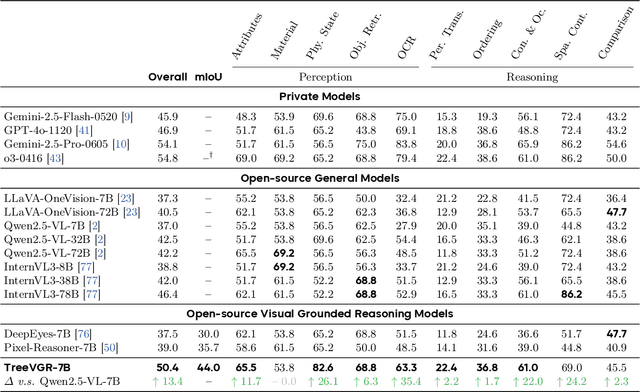
Models like OpenAI-o3 pioneer visual grounded reasoning by dynamically referencing visual regions, just like human "thinking with images". However, no benchmark exists to evaluate these capabilities holistically. To bridge this gap, we propose TreeBench (Traceable Evidence Evaluation Benchmark), a diagnostic benchmark built on three principles: (1) focused visual perception of subtle targets in complex scenes, (2) traceable evidence via bounding box evaluation, and (3) second-order reasoning to test object interactions and spatial hierarchies beyond simple object localization. Prioritizing images with dense objects, we initially sample 1K high-quality images from SA-1B, and incorporate eight LMM experts to manually annotate questions, candidate options, and answers for each image. After three stages of quality control, TreeBench consists of 405 challenging visual question-answering pairs, even the most advanced models struggle with this benchmark, where none of them reach 60% accuracy, e.g., OpenAI-o3 scores only 54.87. Furthermore, we introduce TreeVGR (Traceable Evidence Enhanced Visual Grounded Reasoning), a training paradigm to supervise localization and reasoning jointly with reinforcement learning, enabling accurate localizations and explainable reasoning pathways. Initialized from Qwen2.5-VL-7B, it improves V* Bench (+16.8), MME-RealWorld (+12.6), and TreeBench (+13.4), proving traceability is key to advancing vision-grounded reasoning. The code is available at https://github.com/Haochen-Wang409/TreeVGR.
SAILViT: Towards Robust and Generalizable Visual Backbones for MLLMs via Gradual Feature Refinement
Jul 02, 2025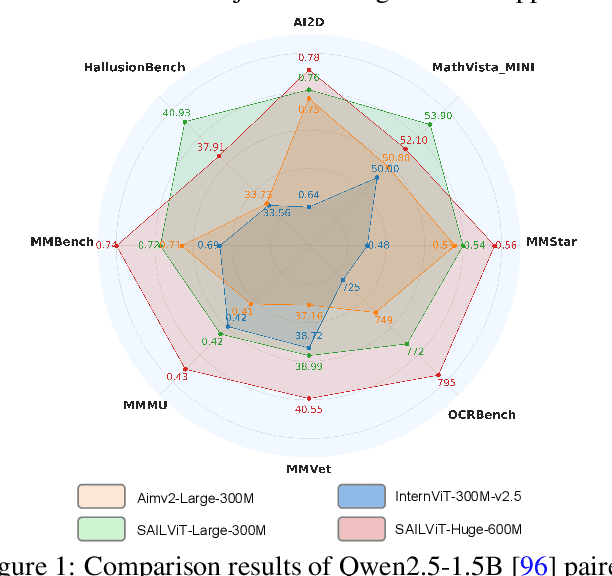
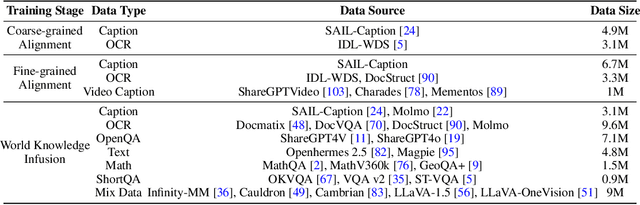
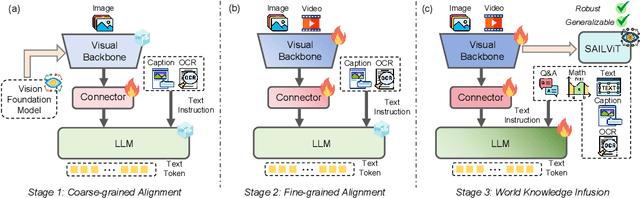
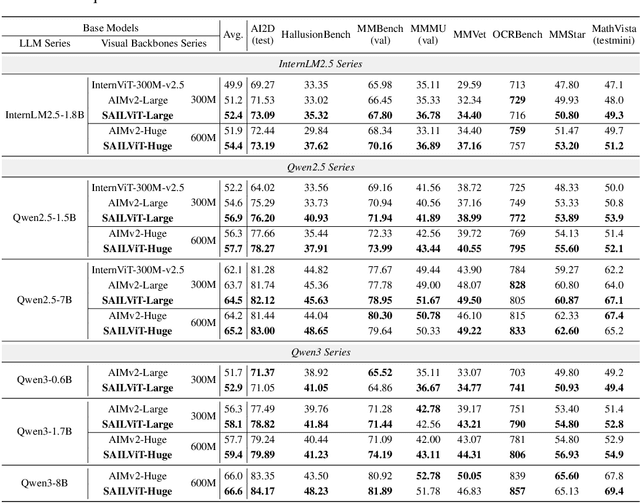
Vision Transformers (ViTs) are essential as foundation backbones in establishing the visual comprehension capabilities of Multimodal Large Language Models (MLLMs). Although most ViTs achieve impressive performance through image-text pair-based contrastive learning or self-supervised mechanisms, they struggle to engage in connector-based co-training directly with LLMs due to potential parameter initialization conflicts and modality semantic gaps. To address the above challenges, this paper proposes SAILViT, a gradual feature learning-enhanced ViT for facilitating MLLMs to break through performance bottlenecks in complex multimodal interactions. SAILViT achieves coarse-to-fine-grained feature alignment and world knowledge infusion with gradual feature refinement, which better serves target training demands. We perform thorough empirical analyses to confirm the powerful robustness and generalizability of SAILViT across different dimensions, including parameter sizes, model architectures, training strategies, and data scales. Equipped with SAILViT, existing MLLMs show significant and consistent performance improvements on the OpenCompass benchmark across extensive downstream tasks. SAILViT series models are released at https://huggingface.co/BytedanceDouyinContent.
VGR: Visual Grounded Reasoning
Jun 16, 2025In the field of multimodal chain-of-thought (CoT) reasoning, existing approaches predominantly rely on reasoning on pure language space, which inherently suffers from language bias and is largely confined to math or science domains. This narrow focus limits their ability to handle complex visual reasoning tasks that demand comprehensive understanding of image details. To address these limitations, this paper introduces VGR, a novel reasoning multimodal large language model (MLLM) with enhanced fine-grained visual perception capabilities. Unlike traditional MLLMs that answer the question or reasoning solely on the language space, our VGR first detects relevant regions that may help to solve problems, and then provides precise answers based on replayed image regions. To achieve this, we conduct a large-scale SFT dataset called VGR -SFT that contains reasoning data with mixed vision grounding and language deduction. The inference pipeline of VGR allows the model to choose bounding boxes for visual reference and a replay stage is introduced to integrates the corresponding regions into the reasoning process, enhancing multimodel comprehension. Experiments on the LLaVA-NeXT-7B baseline show that VGR achieves superior performance on multi-modal benchmarks requiring comprehensive image detail understanding. Compared to the baseline, VGR uses only 30\% of the image token count while delivering scores of +4.1 on MMStar, +7.1 on AI2D, and a +12.9 improvement on ChartQA.
The Scalability of Simplicity: Empirical Analysis of Vision-Language Learning with a Single Transformer
Apr 14, 2025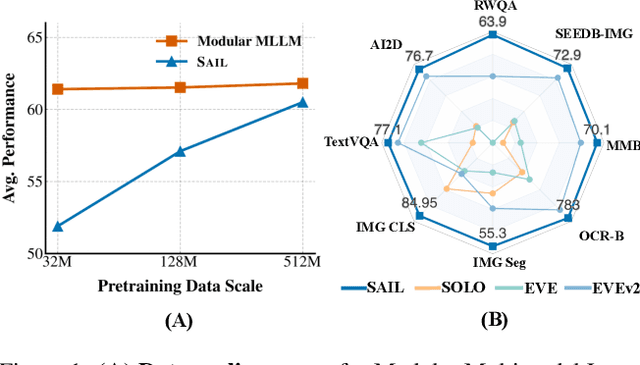
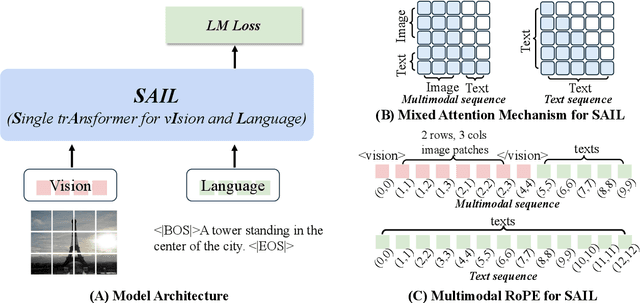
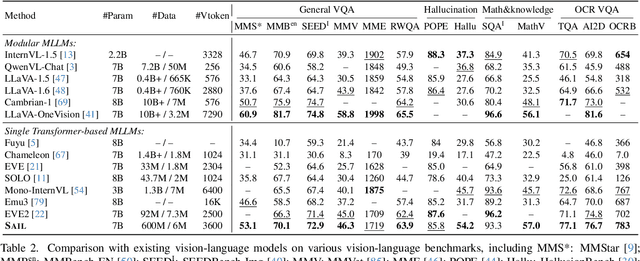
This paper introduces SAIL, a single transformer unified multimodal large language model (MLLM) that integrates raw pixel encoding and language decoding within a singular architecture. Unlike existing modular MLLMs, which rely on a pre-trained vision transformer (ViT), SAIL eliminates the need for a separate vision encoder, presenting a more minimalist architecture design. Instead of introducing novel architectural components, SAIL adapts mix-attention mechanisms and multimodal positional encodings to better align with the distinct characteristics of visual and textual modalities. We systematically compare SAIL's properties-including scalability, cross-modal information flow patterns, and visual representation capabilities-with those of modular MLLMs. By scaling both training data and model size, SAIL achieves performance comparable to modular MLLMs. Notably, the removal of pretrained ViT components enhances SAIL's scalability and results in significantly different cross-modal information flow patterns. Moreover, SAIL demonstrates strong visual representation capabilities, achieving results on par with ViT-22B in vision tasks such as semantic segmentation. Code and models are available at https://github.com/bytedance/SAIL.
UVE: Are MLLMs Unified Evaluators for AI-Generated Videos?
Mar 13, 2025With the rapid growth of video generative models (VGMs), it is essential to develop reliable and comprehensive automatic metrics for AI-generated videos (AIGVs). Existing methods either use off-the-shelf models optimized for other tasks or rely on human assessment data to train specialized evaluators. These approaches are constrained to specific evaluation aspects and are difficult to scale with the increasing demands for finer-grained and more comprehensive evaluations. To address this issue, this work investigates the feasibility of using multimodal large language models (MLLMs) as a unified evaluator for AIGVs, leveraging their strong visual perception and language understanding capabilities. To evaluate the performance of automatic metrics in unified AIGV evaluation, we introduce a benchmark called UVE-Bench. UVE-Bench collects videos generated by state-of-the-art VGMs and provides pairwise human preference annotations across 15 evaluation aspects. Using UVE-Bench, we extensively evaluate 16 MLLMs. Our empirical results suggest that while advanced MLLMs (e.g., Qwen2VL-72B and InternVL2.5-78B) still lag behind human evaluators, they demonstrate promising ability in unified AIGV evaluation, significantly surpassing existing specialized evaluation methods. Additionally, we conduct an in-depth analysis of key design choices that impact the performance of MLLM-driven evaluators, offering valuable insights for future research on AIGV evaluation. The code is available at https://github.com/bytedance/UVE.
World to Code: Multi-modal Data Generation via Self-Instructed Compositional Captioning and Filtering
Sep 30, 2024



Recent advances in Vision-Language Models (VLMs) and the scarcity of high-quality multi-modal alignment data have inspired numerous researches on synthetic VLM data generation. The conventional norm in VLM data construction uses a mixture of specialists in caption and OCR, or stronger VLM APIs and expensive human annotation. In this paper, we present World to Code (W2C), a meticulously curated multi-modal data construction pipeline that organizes the final generation output into a Python code format. The pipeline leverages the VLM itself to extract cross-modal information via different prompts and filter the generated outputs again via a consistency filtering strategy. Experiments have demonstrated the high quality of W2C by improving various existing visual question answering and visual grounding benchmarks across different VLMs. Further analysis also demonstrates that the new code parsing ability of VLMs presents better cross-modal equivalence than the commonly used detail caption ability. Our code is available at https://github.com/foundation-multimodal-models/World2Code.
Benchmarking and Improving Detail Image Caption
May 29, 2024



Image captioning has long been regarded as a fundamental task in visual understanding. Recently, however, few large vision-language model (LVLM) research discusses model's image captioning performance because of the outdated short-caption benchmarks and unreliable evaluation metrics. In this work, we propose to benchmark detail image caption task by curating high-quality evaluation datasets annotated by human experts, GPT-4V and Gemini-1.5-Pro. We also design a more reliable caption evaluation metric called CAPTURE (CAPtion evaluation by exTracting and coUpling coRE information). CAPTURE extracts visual elements, e.g., objects, attributes and relations from captions, and then matches these elements through three stages, achieving the highest consistency with expert judgements over other rule-based or model-based caption metrics. The proposed benchmark and metric provide reliable evaluation for LVLM's detailed image captioning ability. Guided by this evaluation, we further explore to unleash LVLM's detail caption capabilities by synthesizing high-quality data through a five-stage data construction pipeline. Our pipeline only uses a given LVLM itself and other open-source tools, without any human or GPT-4V annotation in the loop. Experiments show that the proposed data construction strategy significantly improves model-generated detail caption data quality for LVLMs with leading performance, and the data quality can be further improved in a self-looping paradigm. All code and dataset will be publicly available at https://github.com/foundation-multimodal-models/CAPTURE.