 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemory in the LLM Era: Modular Architectures and Strategies in a Unified Framework
Apr 02, 2026Memory emerges as the core module in the large language model (LLM)-based agents for long-horizon complex tasks (e.g., multi-turn dialogue, game playing, scientific discovery), where memory can enable knowledge accumulation, iterative reasoning and self-evolution. A number of memory methods have been proposed in the literature. However, these methods have not been systematically and comprehensively compared under the same experimental settings. In this paper, we first summarize a unified framework that incorporates all the existing agent memory methods from a high-level perspective. We then extensively compare representative agent memory methods on two well-known benchmarks and examine the effectiveness of all methods, providing a thorough analysis of those methods. As a byproduct of our experimental analysis, we also design a new memory method by exploiting modules in the existing methods, which outperforms the state-of-the-art methods. Finally, based on these findings, we offer promising future research opportunities. We believe that a deeper understanding of the behavior of existing methods can provide valuable new insights for future research.
Late-to-Early Training: LET LLMs Learn Earlier, So Faster and Better
Feb 05, 2026As Large Language Models (LLMs) achieve remarkable empirical success through scaling model and data size, pretraining has become increasingly critical yet computationally prohibitive, hindering rapid development. Despite the availability of numerous pretrained LLMs developed at significant computational expense, a fundamental real-world question remains underexplored: \textit{Can we leverage existing small pretrained models to accelerate the training of larger models?} In this paper, we propose a Late-to-Early Training (LET) paradigm that enables LLMs to explicitly learn later knowledge in earlier steps and earlier layers. The core idea is to guide the early layers of an LLM during early training using representations from the late layers of a pretrained (i.e. late training phase) model. We identify two key mechanisms that drive LET's effectiveness: late-to-early-step learning and late-to-early-layer learning. These mechanisms significantly accelerate training convergence while robustly enhancing both language modeling capabilities and downstream task performance, enabling faster training with superior performance. Extensive experiments on 1.4B and 7B parameter models demonstrate LET's efficiency and effectiveness. Notably, when training a 1.4B LLM on the Pile dataset, our method achieves up to 1.6$\times$ speedup with nearly 5\% improvement in downstream task accuracy compared to standard training, even when using a pretrained model with 10$\times$ fewer parameters than the target model.
IndexTTS 2.5 Technical Report
Jan 08, 2026In prior work, we introduced IndexTTS 2, a zero-shot neural text-to-speech foundation model comprising two core components: a transformer-based Text-to-Semantic (T2S) module and a non-autoregressive Semantic-to-Mel (S2M) module, which together enable faithful emotion replication and establish the first autoregressive duration-controllable generative paradigm. Building upon this, we present IndexTTS 2.5, which significantly enhances multilingual coverage, inference speed, and overall synthesis quality through four key improvements: 1) Semantic Codec Compression: we reduce the semantic codec frame rate from 50 Hz to 25 Hz, halving sequence length and substantially lowering both training and inference costs; 2) Architectural Upgrade: we replace the U-DiT-based backbone of the S2M module with a more efficient Zipformer-based modeling architecture, achieving notable parameter reduction and faster mel-spectrogram generation; 3) Multilingual Extension: We propose three explicit cross-lingual modeling strategies, boundary-aware alignment, token-level concatenation, and instruction-guided generation, establishing practical design principles for zero-shot multilingual emotional TTS that supports Chinese, English, Japanese, and Spanish, and enables robust emotion transfer even without target-language emotional training data; 4) Reinforcement Learning Optimization: we apply GRPO in post-training of the T2S module, improving pronunciation accuracy and natrualness. Experiments show that IndexTTS 2.5 not only supports broader language coverage but also replicates emotional prosody in unseen languages under the same zero-shot setting. IndexTTS 2.5 achieves a 2.28 times improvement in RTF while maintaining comparable WER and speaker similarity to IndexTTS 2.
Virtual Width Networks
Nov 17, 2025



We introduce Virtual Width Networks (VWN), a framework that delivers the benefits of wider representations without incurring the quadratic cost of increasing the hidden size. VWN decouples representational width from backbone width, expanding the embedding space while keeping backbone compute nearly constant. In our large-scale experiment, an 8-times expansion accelerates optimization by over 2 times for next-token and 3 times for next-2-token prediction. The advantage amplifies over training as both the loss gap grows and the convergence-speedup ratio increases, showing that VWN is not only token-efficient but also increasingly effective with scale. Moreover, we identify an approximately log-linear scaling relation between virtual width and loss reduction, offering an initial empirical basis and motivation for exploring virtual-width scaling as a new dimension of large-model efficiency.
Scaling Latent Reasoning via Looped Language Models
Oct 29, 2025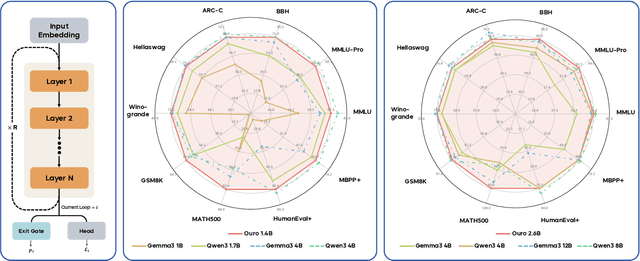
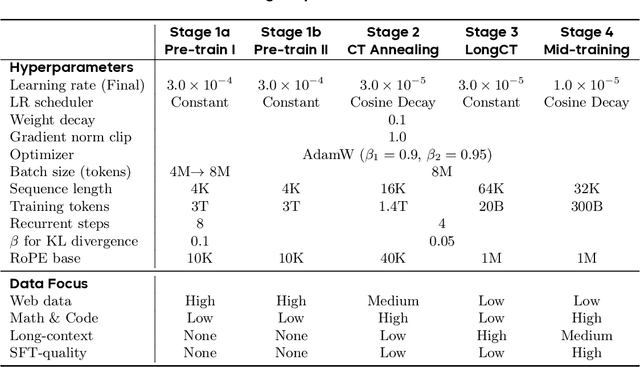
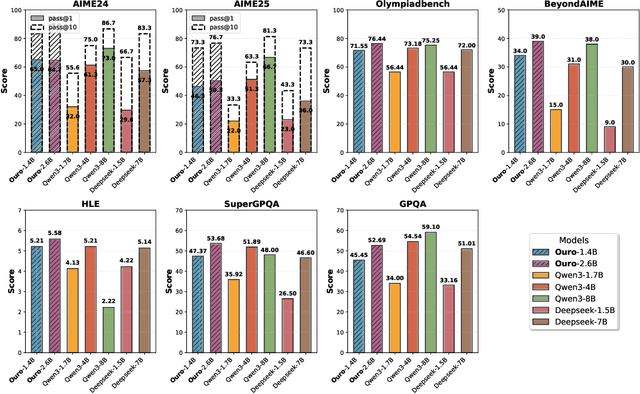

Modern LLMs are trained to "think" primarily via explicit text generation, such as chain-of-thought (CoT), which defers reasoning to post-training and under-leverages pre-training data. We present and open-source Ouro, named after the recursive Ouroboros, a family of pre-trained Looped Language Models (LoopLM) that instead build reasoning into the pre-training phase through (i) iterative computation in latent space, (ii) an entropy-regularized objective for learned depth allocation, and (iii) scaling to 7.7T tokens. Ouro 1.4B and 2.6B models enjoy superior performance that match the results of up to 12B SOTA LLMs across a wide range of benchmarks. Through controlled experiments, we show this advantage stems not from increased knowledge capacity, but from superior knowledge manipulation capabilities. We also show that LoopLM yields reasoning traces more aligned with final outputs than explicit CoT. We hope our results show the potential of LoopLM as a novel scaling direction in the reasoning era. Our model could be found in: http://ouro-llm.github.io.
UltraMemV2: Memory Networks Scaling to 120B Parameters with Superior Long-Context Learning
Aug 26, 2025



While Mixture of Experts (MoE) models achieve remarkable efficiency by activating only subsets of parameters, they suffer from high memory access costs during inference. Memory-layer architectures offer an appealing alternative with very few memory access, but previous attempts like UltraMem have only matched the performance of 2-expert MoE models, falling significantly short of state-of-the-art 8-expert configurations. We present UltraMemV2, a redesigned memory-layer architecture that closes this performance gap. Our approach introduces five key improvements: integrating memory layers into every transformer block, simplifying value expansion with single linear projections, adopting FFN-based value processing from PEER, implementing principled parameter initialization, and rebalancing memory-to-FFN computation ratios. Through extensive evaluation, we demonstrate that UltraMemV2 achieves performance parity with 8-expert MoE models under same computation and parameters but significantly low memory access. Notably, UltraMemV2 shows superior performance on memory-intensive tasks, with improvements of +1.6 points on long-context memorization, +6.2 points on multi-round memorization, and +7.9 points on in-context learning. We validate our approach at scale with models up to 2.5B activated parameters from 120B total parameters, and establish that activation density has greater impact on performance than total sparse parameter count. Our work brings memory-layer architectures to performance parity with state-of-the-art MoE models, presenting a compelling alternative for efficient sparse computation.
UW-3DGS: Underwater 3D Reconstruction with Physics-Aware Gaussian Splatting
Aug 08, 2025Underwater 3D scene reconstruction faces severe challenges from light absorption, scattering, and turbidity, which degrade geometry and color fidelity in traditional methods like Neural Radiance Fields (NeRF). While NeRF extensions such as SeaThru-NeRF incorporate physics-based models, their MLP reliance limits efficiency and spatial resolution in hazy environments. We introduce UW-3DGS, a novel framework adapting 3D Gaussian Splatting (3DGS) for robust underwater reconstruction. Key innovations include: (1) a plug-and-play learnable underwater image formation module using voxel-based regression for spatially varying attenuation and backscatter; and (2) a Physics-Aware Uncertainty Pruning (PAUP) branch that adaptively removes noisy floating Gaussians via uncertainty scoring, ensuring artifact-free geometry. The pipeline operates in training and rendering stages. During training, noisy Gaussians are optimized end-to-end with underwater parameters, guided by PAUP pruning and scattering modeling. In rendering, refined Gaussians produce clean Unattenuated Radiance Images (URIs) free from media effects, while learned physics enable realistic Underwater Images (UWIs) with accurate light transport. Experiments on SeaThru-NeRF and UWBundle datasets show superior performance, achieving PSNR of 27.604, SSIM of 0.868, and LPIPS of 0.104 on SeaThru-NeRF, with ~65% reduction in floating artifacts.
SecFwT: Efficient Privacy-Preserving Fine-Tuning of Large Language Models Using Forward-Only Passes
Jun 18, 2025Large language models (LLMs) have transformed numerous fields, yet their adaptation to specialized tasks in privacy-sensitive domains, such as healthcare and finance, is constrained by the scarcity of accessible training data due to stringent privacy requirements. Secure multi-party computation (MPC)-based privacy-preserving machine learning offers a powerful approach to protect both model parameters and user data, but its application to LLMs has been largely limited to inference, as fine-tuning introduces significant computational challenges, particularly in privacy-preserving backward propagation and optimizer operations. This paper identifies two primary obstacles to MPC-based privacy-preserving fine-tuning of LLMs: (1) the substantial computational overhead of backward and optimizer processes, and (2) the inefficiency of softmax-based attention mechanisms in MPC settings. To address these challenges, we propose SecFwT, the first MPC-based framework designed for efficient, privacy-preserving LLM fine-tuning. SecFwT introduces a forward-only tuning paradigm to eliminate backward and optimizer computations and employs MPC-friendly Random Feature Attention to approximate softmax attention, significantly reducing costly non-linear operations and computational complexity. Experimental results demonstrate that SecFwT delivers substantial improvements in efficiency and privacy preservation, enabling scalable and secure fine-tuning of LLMs for privacy-critical applications.
Scaling Law for Quantization-Aware Training
May 20, 2025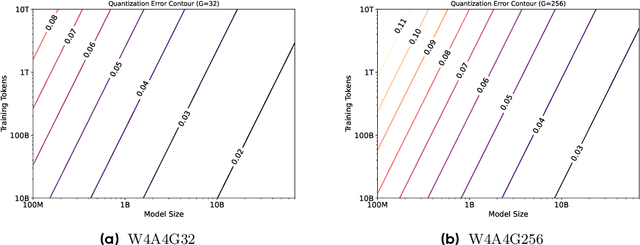
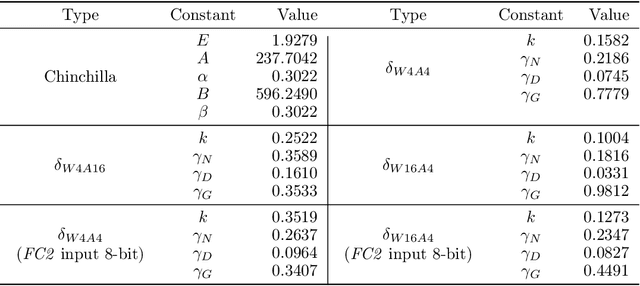
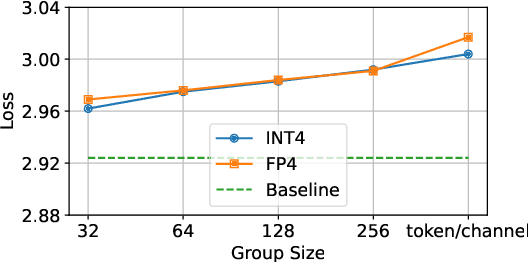
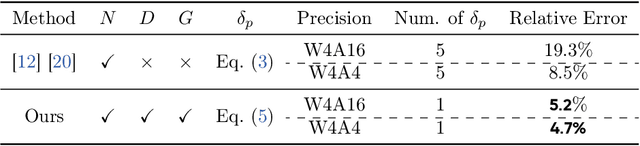
Large language models (LLMs) demand substantial computational and memory resources, creating deployment challenges. Quantization-aware training (QAT) addresses these challenges by reducing model precision while maintaining performance. However, the scaling behavior of QAT, especially at 4-bit precision (W4A4), is not well understood. Existing QAT scaling laws often ignore key factors such as the number of training tokens and quantization granularity, which limits their applicability. This paper proposes a unified scaling law for QAT that models quantization error as a function of model size, training data volume, and quantization group size. Through 268 QAT experiments, we show that quantization error decreases as model size increases, but rises with more training tokens and coarser quantization granularity. To identify the sources of W4A4 quantization error, we decompose it into weight and activation components. Both components follow the overall trend of W4A4 quantization error, but with different sensitivities. Specifically, weight quantization error increases more rapidly with more training tokens. Further analysis shows that the activation quantization error in the FC2 layer, caused by outliers, is the primary bottleneck of W4A4 QAT quantization error. By applying mixed-precision quantization to address this bottleneck, we demonstrate that weight and activation quantization errors can converge to similar levels. Additionally, with more training data, weight quantization error eventually exceeds activation quantization error, suggesting that reducing weight quantization error is also important in such scenarios. These findings offer key insights for improving QAT research and development.
Efficient Pretraining Length Scaling
Apr 21, 2025Recent advances in large language models have demonstrated the effectiveness of length scaling during post-training, yet its potential in pre-training remains underexplored. We present the Parallel Hidden Decoding Transformer (\textit{PHD}-Transformer), a novel framework that enables efficient length scaling during pre-training while maintaining inference efficiency. \textit{PHD}-Transformer achieves this through an innovative KV cache management strategy that distinguishes between original tokens and hidden decoding tokens. By retaining only the KV cache of original tokens for long-range dependencies while immediately discarding hidden decoding tokens after use, our approach maintains the same KV cache size as the vanilla transformer while enabling effective length scaling. To further enhance performance, we introduce two optimized variants: \textit{PHD-SWA} employs sliding window attention to preserve local dependencies, while \textit{PHD-CSWA} implements chunk-wise sliding window attention to eliminate linear growth in pre-filling time. Extensive experiments demonstrate consistent improvements across multiple benchmarks.