 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSecFwT: Efficient Privacy-Preserving Fine-Tuning of Large Language Models Using Forward-Only Passes
Jun 18, 2025Large language models (LLMs) have transformed numerous fields, yet their adaptation to specialized tasks in privacy-sensitive domains, such as healthcare and finance, is constrained by the scarcity of accessible training data due to stringent privacy requirements. Secure multi-party computation (MPC)-based privacy-preserving machine learning offers a powerful approach to protect both model parameters and user data, but its application to LLMs has been largely limited to inference, as fine-tuning introduces significant computational challenges, particularly in privacy-preserving backward propagation and optimizer operations. This paper identifies two primary obstacles to MPC-based privacy-preserving fine-tuning of LLMs: (1) the substantial computational overhead of backward and optimizer processes, and (2) the inefficiency of softmax-based attention mechanisms in MPC settings. To address these challenges, we propose SecFwT, the first MPC-based framework designed for efficient, privacy-preserving LLM fine-tuning. SecFwT introduces a forward-only tuning paradigm to eliminate backward and optimizer computations and employs MPC-friendly Random Feature Attention to approximate softmax attention, significantly reducing costly non-linear operations and computational complexity. Experimental results demonstrate that SecFwT delivers substantial improvements in efficiency and privacy preservation, enabling scalable and secure fine-tuning of LLMs for privacy-critical applications.
Centaur: Bridging the Impossible Trinity of Privacy, Efficiency, and Performance in Privacy-Preserving Transformer Inference
Dec 14, 2024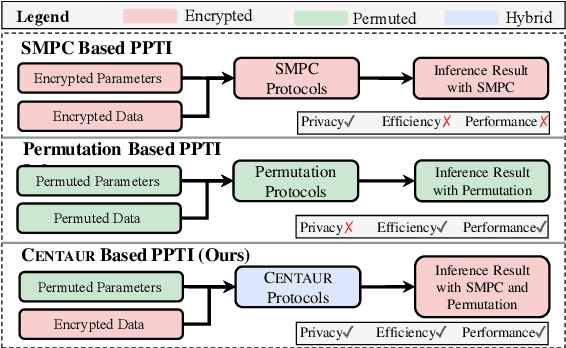
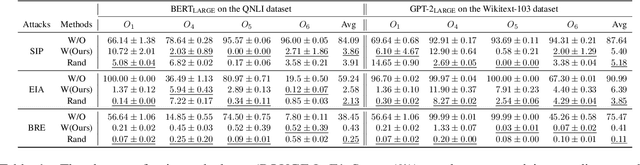
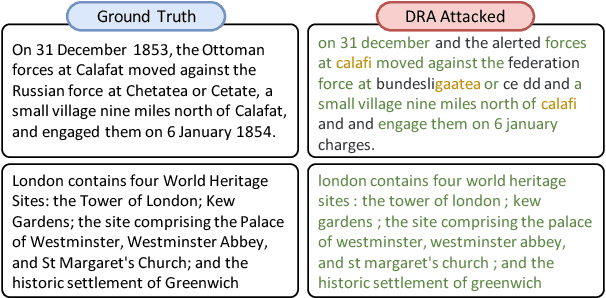
As pre-trained models, like Transformers, are increasingly deployed on cloud platforms for inference services, the privacy concerns surrounding model parameters and inference data are becoming more acute. Current Privacy-Preserving Transformer Inference (PPTI) frameworks struggle with the "impossible trinity" of privacy, efficiency, and performance. For instance, Secure Multi-Party Computation (SMPC)-based solutions offer strong privacy guarantees but come with significant inference overhead and performance trade-offs. On the other hand, PPTI frameworks that use random permutations achieve inference efficiency close to that of plaintext and maintain accurate results but require exposing some model parameters and intermediate results, thereby risking substantial privacy breaches. Addressing this "impossible trinity" with a single technique proves challenging. To overcome this challenge, we propose Centaur, a novel hybrid PPTI framework. Unlike existing methods, Centaur protects model parameters with random permutations and inference data with SMPC, leveraging the structure of Transformer models. By designing a series of efficient privacy-preserving algorithms, Centaur leverages the strengths of both techniques to achieve a better balance between privacy, efficiency, and performance in PPTI. We comprehensively evaluate the effectiveness of Centaur on various types of Transformer models and datasets. Experimental results demonstrate that the privacy protection capabilities offered by Centaur can withstand various existing model inversion attack methods. In terms of performance and efficiency, Centaur not only maintains the same performance as plaintext inference but also improves inference speed by $5.0-30.4$ times.
SecFormer: Towards Fast and Accurate Privacy-Preserving Inference for Large Language Models
Jan 06, 2024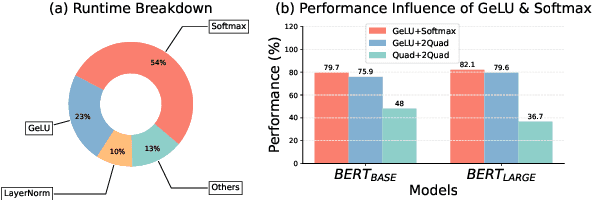
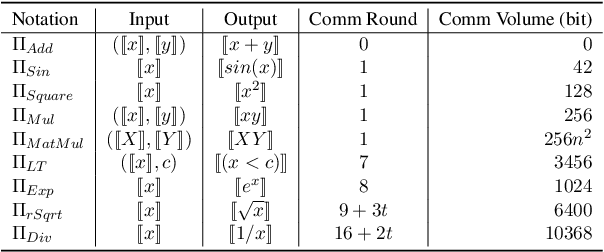
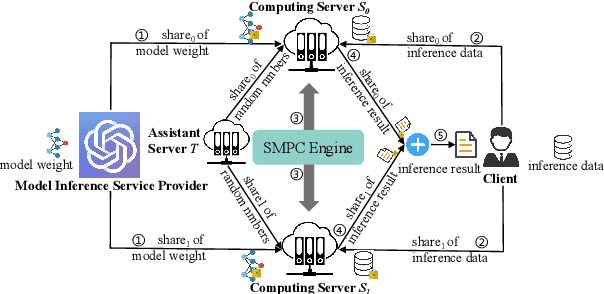
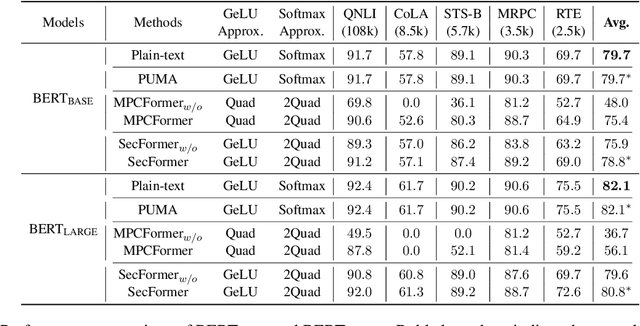
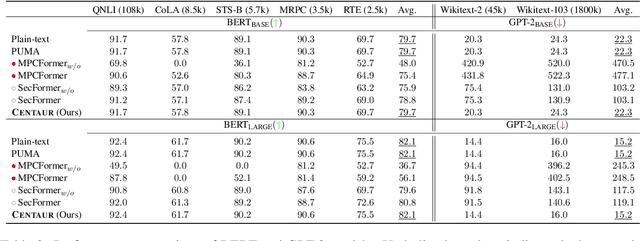
With the growing use of large language models hosted on cloud platforms to offer inference services, privacy concerns are escalating, especially concerning sensitive data like investment plans and bank account details. Secure Multi-Party Computing (SMPC) emerges as a promising solution to protect the privacy of inference data and model parameters. However, the application of SMPC in Privacy-Preserving Inference (PPI) for large language models, particularly those based on the Transformer architecture, often leads to considerable slowdowns or declines in performance. This is largely due to the multitude of nonlinear operations in the Transformer architecture, which are not well-suited to SMPC and difficult to circumvent or optimize effectively. To address this concern, we introduce an advanced optimization framework called SecFormer, to achieve fast and accurate PPI for Transformer models. By implementing model design optimization, we successfully eliminate the high-cost exponential and maximum operations in PPI without sacrificing model performance. Additionally, we have developed a suite of efficient SMPC protocols that utilize segmented polynomials, Fourier series and Goldschmidt's method to handle other complex nonlinear functions within PPI, such as GeLU, LayerNorm, and Softmax. Our extensive experiments reveal that SecFormer outperforms MPCFormer in performance, showing improvements of $5.6\%$ and $24.2\%$ for BERT$_{\text{BASE}}$ and BERT$_{\text{LARGE}}$, respectively. In terms of efficiency, SecFormer is 3.56 and 3.58 times faster than Puma for BERT$_{\text{BASE}}$ and BERT$_{\text{LARGE}}$, demonstrating its effectiveness and speed.
Privacy in Large Language Models: Attacks, Defenses and Future Directions
Oct 16, 2023The advancement of large language models (LLMs) has significantly enhanced the ability to effectively tackle various downstream NLP tasks and unify these tasks into generative pipelines. On the one hand, powerful language models, trained on massive textual data, have brought unparalleled accessibility and usability for both models and users. On the other hand, unrestricted access to these models can also introduce potential malicious and unintentional privacy risks. Despite ongoing efforts to address the safety and privacy concerns associated with LLMs, the problem remains unresolved. In this paper, we provide a comprehensive analysis of the current privacy attacks targeting LLMs and categorize them according to the adversary's assumed capabilities to shed light on the potential vulnerabilities present in LLMs. Then, we present a detailed overview of prominent defense strategies that have been developed to counter these privacy attacks. Beyond existing works, we identify upcoming privacy concerns as LLMs evolve. Lastly, we point out several potential avenues for future exploration.
Practical Privacy-Preserving Gaussian Process Regression via Secret Sharing
Jun 26, 2023Gaussian process regression (GPR) is a non-parametric model that has been used in many real-world applications that involve sensitive personal data (e.g., healthcare, finance, etc.) from multiple data owners. To fully and securely exploit the value of different data sources, this paper proposes a privacy-preserving GPR method based on secret sharing (SS), a secure multi-party computation (SMPC) technique. In contrast to existing studies that protect the data privacy of GPR via homomorphic encryption, differential privacy, or federated learning, our proposed method is more practical and can be used to preserve the data privacy of both the model inputs and outputs for various data-sharing scenarios (e.g., horizontally/vertically-partitioned data). However, it is non-trivial to directly apply SS on the conventional GPR algorithm, as it includes some operations whose accuracy and/or efficiency have not been well-enhanced in the current SMPC protocol. To address this issue, we derive a new SS-based exponentiation operation through the idea of 'confusion-correction' and construct an SS-based matrix inversion algorithm based on Cholesky decomposition. More importantly, we theoretically analyze the communication cost and the security of the proposed SS-based operations. Empirical results show that our proposed method can achieve reasonable accuracy and efficiency under the premise of preserving data privacy.
A Survey of Trustworthy Federated Learning with Perspectives on Security, Robustness, and Privacy
Feb 21, 2023Trustworthy artificial intelligence (AI) technology has revolutionized daily life and greatly benefited human society. Among various AI technologies, Federated Learning (FL) stands out as a promising solution for diverse real-world scenarios, ranging from risk evaluation systems in finance to cutting-edge technologies like drug discovery in life sciences. However, challenges around data isolation and privacy threaten the trustworthiness of FL systems. Adversarial attacks against data privacy, learning algorithm stability, and system confidentiality are particularly concerning in the context of distributed training in federated learning. Therefore, it is crucial to develop FL in a trustworthy manner, with a focus on security, robustness, and privacy. In this survey, we propose a comprehensive roadmap for developing trustworthy FL systems and summarize existing efforts from three key aspects: security, robustness, and privacy. We outline the threats that pose vulnerabilities to trustworthy federated learning across different stages of development, including data processing, model training, and deployment. To guide the selection of the most appropriate defense methods, we discuss specific technical solutions for realizing each aspect of Trustworthy FL (TFL). Our approach differs from previous work that primarily discusses TFL from a legal perspective or presents FL from a high-level, non-technical viewpoint.