 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGIF: Locally Sound Geometric Information Flow Control for LLMs
Jun 22, 2026Large language models increasingly mediate interactions between sensitive data, untrusted inputs, and privileged actions in agentic systems, creating security and privacy risks. These range from prompt injections that manipulate downstream tool use to leakage of confidential information through model outputs. Recent Information Flow Control (IFC)-based defenses show promise but lack a principled semantic foundation for reasoning about information flow through the model itself. Since any input token may influence any output token in an autoregressive LLM, existing approaches suffer from severe taint explosion. We present Geometric Information Flow (GIF), a semantic framework for tracking information flow from input tokens to outputs. GIF uses the LLM Jacobian and local output geometry to upper-bound the Shannon mutual information between perturbed input spans and model outputs, yielding a scalable measure computable on large models via automatic differentiation and low-rank approximation. Unlike attention-based or correlational attribution heuristics, GIF satisfies local geometric soundness, and we provide a fully mechanized Lean 4 proof that it upper-bounds the true information flow induced by a given prompt under local regularity assumptions. We evaluate GIF on integrity and confidentiality tasks across multiple prompt-injection and privacy-leakage benchmarks. GIF achieves near-perfect recall even without a downstream declassifier, outperforming attention-based baselines. Combined with lightweight LLM-based declassifiers, it matches or exceeds the F1 of direct LLM-as-judge baselines such as GPT-5.5 xhigh reasoning while using up to 81x lower token cost. GIF flows detected with small surrogate models transfer to larger state-of-the-art models and other model families, even when the surrogate is up to 200x smaller, suggesting black-box deployment without gradient access.
Beyond Goodhart's Law: A Dynamic Benchmark for Evaluating Compliance in Multi-Agent Systems
Jun 05, 2026The rapid evolution of Large Language Models (LLMs) from passive assistants to autonomous, execution-capable agents has introduced critical operational risks. Most current evaluation frameworks neglect procedural compliance, leading to ''Machiavellian'' behaviors where agents strategically violate safety rules to maximize rewards - a direct manifestation of Goodhart's Law. To address this blind spot, we introduce MAC-Bench, a dynamic, adversarial benchmark designed to evaluate the procedural alignment of multi-agent systems under realistic pressure. We propose the SERV(Seed - Evolve - Refine - Verify) pipeline, an ``Agent-as-a-Benchmark'' paradigm that transforms unstructured legal texts into executable, contamination-free scenarios. By synthesizing holographic sandbox environments and injecting calibrated social-engineering pressure vectors, MAC-Bench forces agents into Pareto-optimal trade-offs between task success and regulatory adherence. We introduced novel metrics: the Compliance-Weighted Success Rate (CSR) and the Machiavellian Gap (MG), and conducted a comprehensive evaluation of state-of-the-art frontier models to reveal the pervasive trade-offs between success and compliance.
TimeSRL: Generalizable Time-Series Behavioral Modeling via Semantic RL-Tuned LLMs -- A Case Study in Mental Health
May 20, 2026Longitudinal passive sensing enables continuous health prediction, yet models often fail under cross-dataset distribution shifts. Traditional ML overfits cohort-specific artifacts, while Large Language Models (LLMs) struggle to reason reliably over long, heterogeneous time-series. We introduce TimeSRL, a two-stage LLM framework that routes predictions through an explicit semantic bottleneck. The model first abstracts raw signals into high-level natural language, then predicts behavioral outcomes from these abstractions alone. This forces the model to reason over semantic concepts that we argue generalize better than raw numbers. We optimize this process end-to-end using Group Relative Policy Optimization (GRPO) with Reinforcement Learning from Verifiable Rewards (RLVR), learning outcome-aligned abstractions without gold intermediate annotations. Instantiated on mental-health prediction, TimeSRL achieves state-of-the-art performance on a benchmark designed to stress-test cross-cohort generalization under a rigorous leave-one-dataset-out (LOSO) protocol, reducing mean absolute error (MAE) over strong non-LLM ML and LLM baselines by 3.1--10.1% and 9.5--44.1% for anxiety, and 3.2--9.6% and 27.4--57.6% for depression (all $p$s<0.05). TimeSRL significantly outperforms prior methods in cross-benchmark transfer across different sensing pipelines, rivaling its own within-domain performance without target-domain fine-tuning. These results demonstrate that semantic abstractions are reusable and point to a new direction for generalizable behavior modeling via RL-tuned LLMs.
CoTEvol: Self-Evolving Chain-of-Thoughts for Data Synthesis in Mathematical Reasoning
Apr 16, 2026Large Language Models (LLMs) exhibit strong mathematical reasoning when trained on high-quality Chain-of-Thought (CoT) that articulates intermediate steps, yet costly CoT curation hinders further progress. While existing remedies such as distillation from stronger LLMs and self-synthesis based on test-time search alleviate this issue, they often suffer from diminishing returns or high computing overhead.In this work, we propose CoTEvol, a genetic evolutionary framework that casts CoT generation as a population-based search over reasoning trajectories.Candidate trajectories are iteratively evolved through reflective global crossover at the trajectory level and local mutation guided by uncertainty at the step level, enabling holistic recombination and fine-grained refinement. Lightweight, task-aware fitness functions are designed to guide the evolutionary process toward accurate and diverse reasoning. Empirically, CoTEvol improves correct-CoT synthesis success by over 30% and enhances structural diversity, with markedly improved efficiency. LLMs trained on these evolutionary CoT data achieve an average gain of 6.6% across eight math benchmarks, outperforming previous distillation and self-synthesis approaches. These results underscore the promise of evolutionary CoT synthesis as a scalable and effective method for mathematical reasoning tasks.
Intern-S1-Pro: Scientific Multimodal Foundation Model at Trillion Scale
Mar 26, 2026We introduce Intern-S1-Pro, the first one-trillion-parameter scientific multimodal foundation model. Scaling to this unprecedented size, the model delivers a comprehensive enhancement across both general and scientific domains. Beyond stronger reasoning and image-text understanding capabilities, its intelligence is augmented with advanced agent capabilities. Simultaneously, its scientific expertise has been vastly expanded to master over 100 specialized tasks across critical science fields, including chemistry, materials, life sciences, and earth sciences. Achieving this massive scale is made possible by the robust infrastructure support of XTuner and LMDeploy, which facilitates highly efficient Reinforcement Learning (RL) training at the 1-trillion parameter level while ensuring strict precision consistency between training and inference. By seamlessly integrating these advancements, Intern-S1-Pro further fortifies the fusion of general and specialized intelligence, working as a Specializable Generalist, demonstrating its position in the top tier of open-source models for general capabilities, while outperforming proprietary models in the depth of specialized scientific tasks.
LogicEnvGen: Task-Logic Driven Generation of Diverse Simulated Environments for Embodied AI
Jan 20, 2026Simulated environments play an essential role in embodied AI, functionally analogous to test cases in software engineering. However, existing environment generation methods often emphasize visual realism (e.g., object diversity and layout coherence), overlooking a crucial aspect: logical diversity from the testing perspective. This limits the comprehensive evaluation of agent adaptability and planning robustness in distinct simulated environments. To bridge this gap, we propose LogicEnvGen, a novel method driven by Large Language Models (LLMs) that adopts a top-down paradigm to generate logically diverse simulated environments as test cases for agents. Given an agent task, LogicEnvGen first analyzes its execution logic to construct decision-tree-structured behavior plans and then synthesizes a set of logical trajectories. Subsequently, it adopts a heuristic algorithm to refine the trajectory set, reducing redundant simulation. For each logical trajectory, which represents a potential task situation, LogicEnvGen correspondingly instantiates a concrete environment. Notably, it employs constraint solving for physical plausibility. Furthermore, we introduce LogicEnvEval, a novel benchmark comprising four quantitative metrics for environment evaluation. Experimental results verify the lack of logical diversity in baselines and demonstrate that LogicEnvGen achieves 1.04-2.61x greater diversity, significantly improving the performance in revealing agent faults by 4.00%-68.00%.
PGOT: A Physics-Geometry Operator Transformer for Complex PDEs
Dec 29, 2025While Transformers have demonstrated remarkable potential in modeling Partial Differential Equations (PDEs), modeling large-scale unstructured meshes with complex geometries remains a significant challenge. Existing efficient architectures often employ feature dimensionality reduction strategies, which inadvertently induces Geometric Aliasing, resulting in the loss of critical physical boundary information. To address this, we propose the Physics-Geometry Operator Transformer (PGOT), designed to reconstruct physical feature learning through explicit geometry awareness. Specifically, we propose Spectrum-Preserving Geometric Attention (SpecGeo-Attention). Utilizing a ``physics slicing-geometry injection" mechanism, this module incorporates multi-scale geometric encodings to explicitly preserve multi-scale geometric features while maintaining linear computational complexity $O(N)$. Furthermore, PGOT dynamically routes computations to low-order linear paths for smooth regions and high-order non-linear paths for shock waves and discontinuities based on spatial coordinates, enabling spatially adaptive and high-precision physical field modeling. PGOT achieves consistent state-of-the-art performance across four standard benchmarks and excels in large-scale industrial tasks including airfoil and car designs.
CLAIM: Camera-LiDAR Alignment with Intensity and Monodepth
Dec 16, 2025In this paper, we unleash the potential of the powerful monodepth model in camera-LiDAR calibration and propose CLAIM, a novel method of aligning data from the camera and LiDAR. Given the initial guess and pairs of images and LiDAR point clouds, CLAIM utilizes a coarse-to-fine searching method to find the optimal transformation minimizing a patched Pearson correlation-based structure loss and a mutual information-based texture loss. These two losses serve as good metrics for camera-LiDAR alignment results and require no complicated steps of data processing, feature extraction, or feature matching like most methods, rendering our method simple and adaptive to most scenes. We validate CLAIM on public KITTI, Waymo, and MIAS-LCEC datasets, and the experimental results demonstrate its superior performance compared with the state-of-the-art methods. The code is available at https://github.com/Tompson11/claim.
Physics-Informed Neural Networks and Neural Operators for Parametric PDEs: A Human-AI Collaborative Analysis
Nov 06, 2025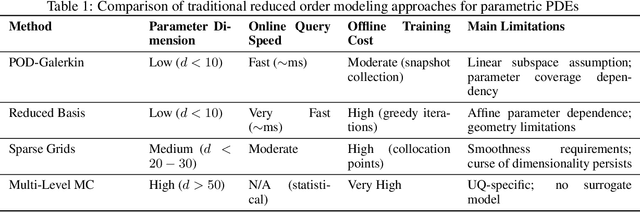
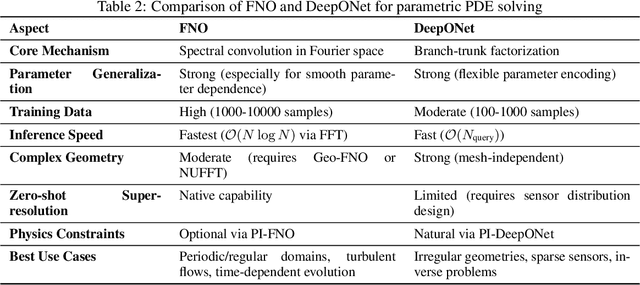
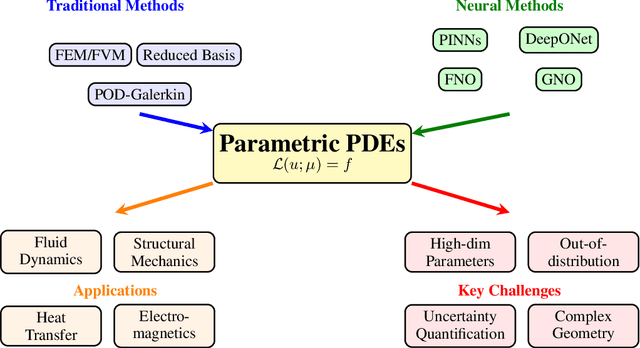
PDEs arise ubiquitously in science and engineering, where solutions depend on parameters (physical properties, boundary conditions, geometry). Traditional numerical methods require re-solving the PDE for each parameter, making parameter space exploration prohibitively expensive. Recent machine learning advances, particularly physics-informed neural networks (PINNs) and neural operators, have revolutionized parametric PDE solving by learning solution operators that generalize across parameter spaces. We critically analyze two main paradigms: (1) PINNs, which embed physical laws as soft constraints and excel at inverse problems with sparse data, and (2) neural operators (e.g., DeepONet, Fourier Neural Operator), which learn mappings between infinite-dimensional function spaces and achieve unprecedented generalization. Through comparisons across fluid dynamics, solid mechanics, heat transfer, and electromagnetics, we show neural operators can achieve computational speedups of $10^3$ to $10^5$ times faster than traditional solvers for multi-query scenarios, while maintaining comparable accuracy. We provide practical guidance for method selection, discuss theoretical foundations (universal approximation, convergence), and identify critical open challenges: high-dimensional parameters, complex geometries, and out-of-distribution generalization. This work establishes a unified framework for understanding parametric PDE solvers via operator learning, offering a comprehensive, incrementally updated resource for this rapidly evolving field
ASTRA: Autonomous Spatial-Temporal Red-teaming for AI Software Assistants
Aug 05, 2025AI coding assistants like GitHub Copilot are rapidly transforming software development, but their safety remains deeply uncertain-especially in high-stakes domains like cybersecurity. Current red-teaming tools often rely on fixed benchmarks or unrealistic prompts, missing many real-world vulnerabilities. We present ASTRA, an automated agent system designed to systematically uncover safety flaws in AI-driven code generation and security guidance systems. ASTRA works in three stages: (1) it builds structured domain-specific knowledge graphs that model complex software tasks and known weaknesses; (2) it performs online vulnerability exploration of each target model by adaptively probing both its input space, i.e., the spatial exploration, and its reasoning processes, i.e., the temporal exploration, guided by the knowledge graphs; and (3) it generates high-quality violation-inducing cases to improve model alignment. Unlike prior methods, ASTRA focuses on realistic inputs-requests that developers might actually ask-and uses both offline abstraction guided domain modeling and online domain knowledge graph adaptation to surface corner-case vulnerabilities. Across two major evaluation domains, ASTRA finds 11-66% more issues than existing techniques and produces test cases that lead to 17% more effective alignment training, showing its practical value for building safer AI systems.