 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSlideSparse: Fast and Flexible (2N-2):2N Structured Sparsity
Mar 05, 2026NVIDIA's 2:4 Sparse Tensor Cores deliver 2x throughput but demand strict 50% pruning -- a ratio that collapses LLM reasoning accuracy (Qwen3: 54% to 15%). Milder $(2N-2):2N$ patterns (e.g., 6:8, 25% pruning) preserve accuracy yet receive no hardware support, falling back to dense execution without any benefit from sparsity. We present SlideSparse, the first system to unlock Sparse Tensor Core acceleration for the $(2N-2):2N$ model family on commodity GPUs. Our Sliding Window Decomposition reconstructs any $(2N-2):2N$ weight block into $N-1$ overlapping 2:4-compliant windows without any accuracy loss; Activation Lifting fuses the corresponding activation rearrangement into per-token quantization at near-zero cost. Integrated into vLLM, SlideSparse is evaluated across various GPUs (A100, H100, B200, RTX 4090, RTX 5080, DGX-spark), precisions (FP4, INT8, FP8, BF16, FP16), and model families (Llama, Qwen, BitNet). On compute-bound workloads, the measured speedup ratio (1.33x) approaches the theoretical upper-bound $N/(N-1)=4/3$ at 6:8 weight sparsity in Qwen2.5-7B, establishing $(2N-2):2N$ as a practical path to accuracy-preserving LLM acceleration. Code available at https://github.com/bcacdwk/vllmbench.
Reducing False Positives in Static Bug Detection with LLMs: An Empirical Study in Industry
Jan 26, 2026Static analysis tools (SATs) are widely adopted in both academia and industry for improving software quality, yet their practical use is often hindered by high false positive rates, especially in large-scale enterprise systems. These false alarms demand substantial manual inspection, creating severe inefficiencies in industrial code review. While recent work has demonstrated the potential of large language models (LLMs) for false alarm reduction on open-source benchmarks, their effectiveness in real-world enterprise settings remains unclear. To bridge this gap, we conduct the first comprehensive empirical study of diverse LLM-based false alarm reduction techniques in an industrial context at Tencent, one of the largest IT companies in China. Using data from Tencent's enterprise-customized SAT on its large-scale Advertising and Marketing Services software, we construct a dataset of 433 alarms (328 false positives, 105 true positives) covering three common bug types. Through interviewing developers and analyzing the data, our results highlight the prevalence of false positives, which wastes substantial manual effort (e.g., 10-20 minutes of manual inspection per alarm). Meanwhile, our results show the huge potential of LLMs for reducing false alarms in industrial settings (e.g., hybrid techniques of LLM and static analysis eliminate 94-98% of false positives with high recall). Furthermore, LLM-based techniques are cost-effective, with per-alarm costs as low as 2.1-109.5 seconds and $0.0011-$0.12, representing orders-of-magnitude savings compared to manual review. Finally, our case analysis further identifies key limitations of LLM-based false alarm reduction in industrial settings.
Can Deep Research Agents Find and Organize? Evaluating the Synthesis Gap with Expert Taxonomies
Jan 18, 2026Deep Research Agents are increasingly used for automated survey generation. However, whether they can write surveys like human experts remains unclear. Existing benchmarks focus on fluency or citation accuracy, but none evaluates the core capabilities: retrieving essential papers and organizing them into coherent knowledge structures. We introduce TaxoBench, a diagnostic benchmark derived from 72 highly-cited computer science surveys. We manually extract expert-authored taxonomy trees containing 3,815 precisely categorized citations as ground truth. Our benchmark supports two evaluation modes: Deep Research mode tests end-to-end retrieval and organization given only a topic, while Bottom-Up mode isolates structuring capability by providing the exact papers human experts used. We evaluate 7 leading Deep Research agents and 12 frontier LLMs. Results reveal a dual bottleneck: the best agent recalls only 20.9% of expert-selected papers, and even with perfect input, the best model achieves only 0.31 ARI in organization. Current deep research agents remain far from expert-level survey writing. Our benchmark is publicly available at https://github.com/KongLongGeFDU/TaxoBench.
DS-CIM: Digital Stochastic Computing-In-Memory Featuring Accurate OR-Accumulation via Sample Region Remapping for Edge AI Models
Jan 10, 2026Stochastic computing (SC) offers hardware simplicity but suffers from low throughput, while high-throughput Digital Computing-in-Memory (DCIM) is bottlenecked by costly adder logic for matrix-vector multiplication (MVM). To address this trade-off, this paper introduces a digital stochastic CIM (DS-CIM) architecture that achieves both high accuracy and efficiency. We implement signed multiply-accumulation (MAC) in a compact, unsigned OR-based circuit by modifying the data representation. Throughput is enhanced by replicating this low-cost circuit 64 times with only a 1x area increase. Our core strategy, a shared Pseudo Random Number Generator (PRNG) with 2D partitioning, enables single-cycle mutually exclusive activation to eliminate OR-gate collisions. We also resolve the 1s saturation issue via stochastic process analysis and data remapping, significantly improving accuracy and resilience to input sparsity. Our high-accuracy DS-CIM1 variant achieves 94.45% accuracy for INT8 ResNet18 on CIFAR-10 with a root-mean-squared error (RMSE) of just 0.74%. Meanwhile, our high-efficiency DS-CIM2 variant attains an energy efficiency of 3566.1 TOPS/W and an area efficiency of 363.7 TOPS/mm^2, while maintaining a low RMSE of 3.81%. The DS-CIM capability with larger models is further demonstrated through experiments with INT8 ResNet50 on ImageNet and the FP8 LLaMA-7B model.
A Novel Discrete Memristor-Coupled Heterogeneous Dual-Neuron Model and Its Application in Multi-Scenario Image Encryption
May 30, 2025Simulating brain functions using neural networks is an important area of research. Recently, discrete memristor-coupled neurons have attracted significant attention, as memristors effectively mimic synaptic behavior, which is essential for learning and memory. This highlights the biological relevance of such models. This study introduces a discrete memristive heterogeneous dual-neuron network (MHDNN). The stability of the MHDNN is analyzed with respect to initial conditions and a range of neuronal parameters. Numerical simulations demonstrate complex dynamical behaviors. Various neuronal firing patterns are investigated under different coupling strengths, and synchronization phenomena between neurons are explored. The MHDNN is implemented and validated on the STM32 hardware platform. An image encryption algorithm based on the MHDNN is proposed, along with two hardware platforms tailored for multi-scenario police image encryption. These solutions enable real-time and secure transmission of police data in complex environments, reducing hacking risks and enhancing system security.
Cross Paradigm Representation and Alignment Transformer for Image Deraining
Apr 23, 2025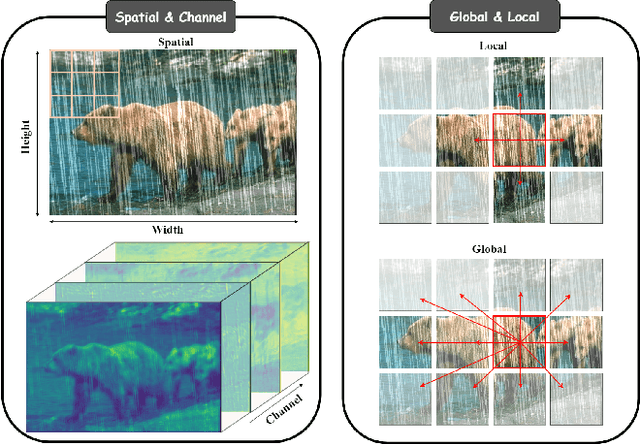
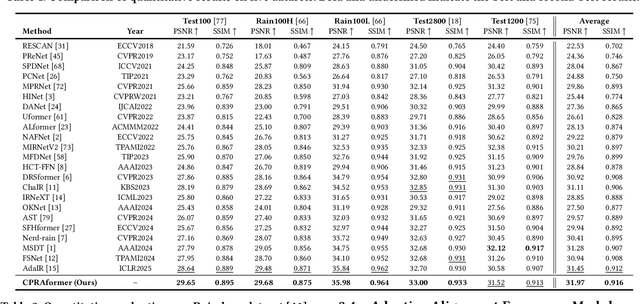
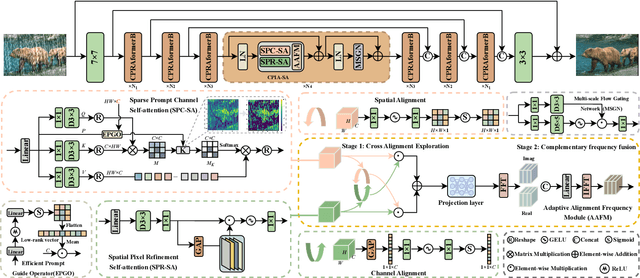
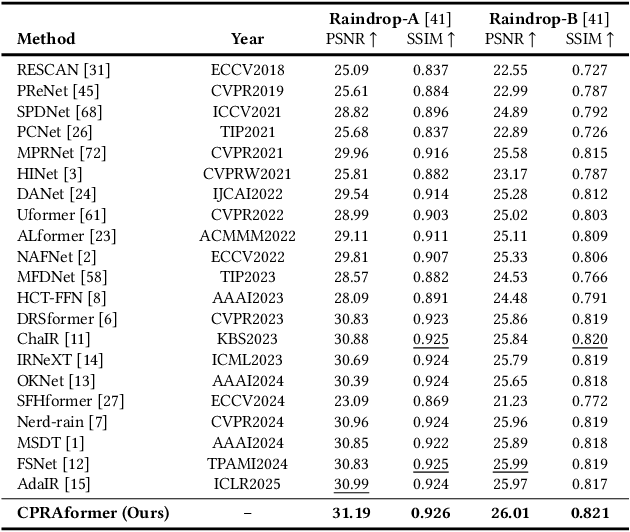
Transformer-based networks have achieved strong performance in low-level vision tasks like image deraining by utilizing spatial or channel-wise self-attention. However, irregular rain patterns and complex geometric overlaps challenge single-paradigm architectures, necessitating a unified framework to integrate complementary global-local and spatial-channel representations. To address this, we propose a novel Cross Paradigm Representation and Alignment Transformer (CPRAformer). Its core idea is the hierarchical representation and alignment, leveraging the strengths of both paradigms (spatial-channel and global-local) to aid image reconstruction. It bridges the gap within and between paradigms, aligning and coordinating them to enable deep interaction and fusion of features. Specifically, we use two types of self-attention in the Transformer blocks: sparse prompt channel self-attention (SPC-SA) and spatial pixel refinement self-attention (SPR-SA). SPC-SA enhances global channel dependencies through dynamic sparsity, while SPR-SA focuses on spatial rain distribution and fine-grained texture recovery. To address the feature misalignment and knowledge differences between them, we introduce the Adaptive Alignment Frequency Module (AAFM), which aligns and interacts with features in a two-stage progressive manner, enabling adaptive guidance and complementarity. This reduces the information gap within and between paradigms. Through this unified cross-paradigm dynamic interaction framework, we achieve the extraction of the most valuable interactive fusion information from the two paradigms. Extensive experiments demonstrate that our model achieves state-of-the-art performance on eight benchmark datasets and further validates CPRAformer's robustness in other image restoration tasks and downstream applications.
Learning Dual-Domain Multi-Scale Representations for Single Image Deraining
Mar 15, 2025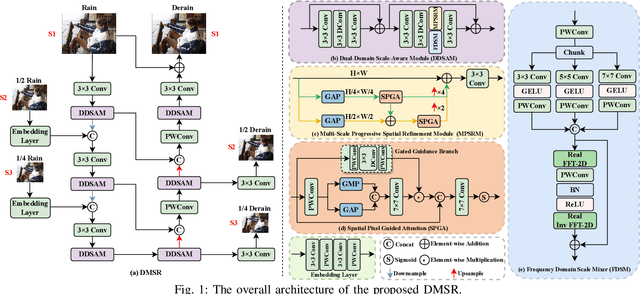
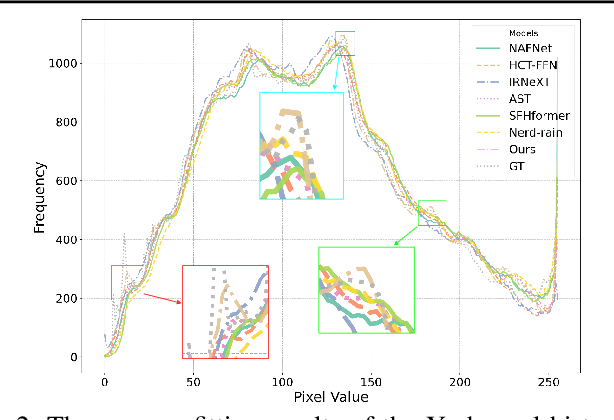

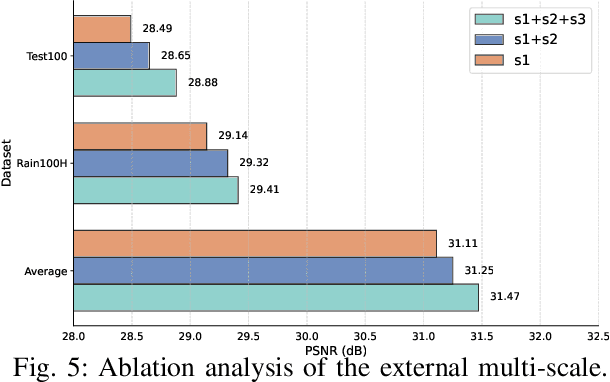
Existing image deraining methods typically rely on single-input, single-output, and single-scale architectures, which overlook the joint multi-scale information between external and internal features. Furthermore, single-domain representations are often too restrictive, limiting their ability to handle the complexities of real-world rain scenarios. To address these challenges, we propose a novel Dual-Domain Multi-Scale Representation Network (DMSR). The key idea is to exploit joint multi-scale representations from both external and internal domains in parallel while leveraging the strengths of both spatial and frequency domains to capture more comprehensive properties. Specifically, our method consists of two main components: the Multi-Scale Progressive Spatial Refinement Module (MPSRM) and the Frequency Domain Scale Mixer (FDSM). The MPSRM enables the interaction and coupling of multi-scale expert information within the internal domain using a hierarchical modulation and fusion strategy. The FDSM extracts multi-scale local information in the spatial domain, while also modeling global dependencies in the frequency domain. Extensive experiments show that our model achieves state-of-the-art performance across six benchmark datasets.
Fraesormer: Learning Adaptive Sparse Transformer for Efficient Food Recognition
Mar 15, 2025In recent years, Transformer has witnessed significant progress in food recognition. However, most existing approaches still face two critical challenges in lightweight food recognition: (1) the quadratic complexity and redundant feature representation from interactions with irrelevant tokens; (2) static feature recognition and single-scale representation, which overlook the unstructured, non-fixed nature of food images and the need for multi-scale features. To address these, we propose an adaptive and efficient sparse Transformer architecture (Fraesormer) with two core designs: Adaptive Top-k Sparse Partial Attention (ATK-SPA) and Hierarchical Scale-Sensitive Feature Gating Network (HSSFGN). ATK-SPA uses a learnable Gated Dynamic Top-K Operator (GDTKO) to retain critical attention scores, filtering low query-key matches that hinder feature aggregation. It also introduces a partial channel mechanism to reduce redundancy and promote expert information flow, enabling local-global collaborative modeling. HSSFGN employs gating mechanism to achieve multi-scale feature representation, enhancing contextual semantic information. Extensive experiments show that Fraesormer outperforms state-of-the-art methods. code is available at https://zs1314.github.io/Fraesormer.
GIMS: Image Matching System Based on Adaptive Graph Construction and Graph Neural Network
Dec 24, 2024



Feature-based image matching has extensive applications in computer vision. Keypoints detected in images can be naturally represented as graph structures, and Graph Neural Networks (GNNs) have been shown to outperform traditional deep learning techniques. Consequently, the paradigm of image matching via GNNs has gained significant prominence in recent academic research. In this paper, we first introduce an innovative adaptive graph construction method that utilizes a filtering mechanism based on distance and dynamic threshold similarity. This method dynamically adjusts the criteria for incorporating new vertices based on the characteristics of existing vertices, allowing for the construction of more precise and robust graph structures while avoiding redundancy. We further combine the vertex processing capabilities of GNNs with the global awareness capabilities of Transformers to enhance the model's representation of spatial and feature information within graph structures. This hybrid model provides a deeper understanding of the interrelationships between vertices and their contributions to the matching process. Additionally, we employ the Sinkhorn algorithm to iteratively solve for optimal matching results. Finally, we validate our system using extensive image datasets and conduct comprehensive comparative experiments. Experimental results demonstrate that our system achieves an average improvement of 3.8x-40.3x in overall matching performance. Additionally, the number of vertices and edges significantly impacts training efficiency and memory usage; therefore, we employ multi-GPU technology to accelerate the training process. Our code is available at https://github.com/songxf1024/GIMS.
Microscopic-Mamba: Revealing the Secrets of Microscopic Images with Just 4M Parameters
Sep 12, 2024



In the field of medical microscopic image classification (MIC), CNN-based and Transformer-based models have been extensively studied. However, CNNs struggle with modeling long-range dependencies, limiting their ability to fully utilize semantic information in images. Conversely, Transformers are hampered by the complexity of quadratic computations. To address these challenges, we propose a model based on the Mamba architecture: Microscopic-Mamba. Specifically, we designed the Partially Selected Feed-Forward Network (PSFFN) to replace the last linear layer of the Visual State Space Module (VSSM), enhancing Mamba's local feature extraction capabilities. Additionally, we introduced the Modulation Interaction Feature Aggregation (MIFA) module to effectively modulate and dynamically aggregate global and local features. We also incorporated a parallel VSSM mechanism to improve inter-channel information interaction while reducing the number of parameters. Extensive experiments have demonstrated that our method achieves state-of-the-art performance on five public datasets. Code is available at https://github.com/zs1314/Microscopic-Mamba