 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNot All Candidates are Created Equal: A Heterogeneity-Aware Approach to Pre-ranking in Recommender Systems
Mar 04, 2026Most large-scale recommender systems follow a multi-stage cascade of retrieval, pre-ranking, ranking, and re-ranking. A key challenge at the pre-ranking stage arises from the heterogeneity of training instances sampled from coarse-grained retrieval results, fine-grained ranking signals, and exposure feedback. Our analysis reveals that prevailing pre-ranking methods, which indiscriminately mix heterogeneous samples, suffer from gradient conflicts: hard samples dominate training while easy ones remain underutilized, leading to suboptimal performance. We further show that the common practice of uniformly scaling model complexity across all samples is inefficient, as it overspends computation on easy cases and slows training without proportional gains. To address these limitations, this paper presents Heterogeneity-Aware Adaptive Pre-ranking (HAP), a unified framework that mitigates gradient conflicts through conflict-sensitive sampling coupled with tailored loss design, while adaptively allocating computational budgets across candidates. Specifically, HAP disentangles easy and hard samples, directing each subset along dedicated optimization paths. Building on this separation, it first applies lightweight models to all candidates for efficient coverage, and further engages stronger models on the hard ones, maintaining accuracy while reducing cost. This approach not only improves pre-ranking effectiveness but also provides a practical perspective on scaling strategies in industrial recommender systems. HAP has been deployed in the Toutiao production system for 9 months, yielding up to 0.4% improvement in user app usage duration and 0.05% in active days, without additional computational cost. We also release a large-scale industrial hybrid-sample dataset to enable the systematic study of source-driven candidate heterogeneity in pre-ranking.
Next-User Retrieval: Enhancing Cold-Start Recommendations via Generative Next-User Modeling
Jun 18, 2025The item cold-start problem is critical for online recommendation systems, as the success of this phase determines whether high-quality new items can transition to popular ones, receive essential feedback to inspire creators, and thus lead to the long-term retention of creators. However, modern recommendation systems still struggle to address item cold-start challenges due to the heavy reliance on item and historical interactions, which are non-trivial for cold-start items lacking sufficient exposure and feedback. Lookalike algorithms provide a promising solution by extending feedback for new items based on lookalike users. Traditional lookalike algorithms face such limitations: (1) failing to effectively model the lookalike users and further improve recommendations with the existing rule- or model-based methods; and (2) struggling to utilize the interaction signals and incorporate diverse features in modern recommendation systems. Inspired by lookalike algorithms, we propose Next-User Retrieval, a novel framework for enhancing cold-start recommendations via generative next-user modeling. Specifically, we employ a transformer-based model to capture the unidirectional relationships among recently interacted users and utilize these sequences to generate the next potential user who is most likely to interact with the item. The additional item features are also integrated as prefix prompt embeddings to assist the next-user generation. The effectiveness of Next-User Retrieval is evaluated through both offline experiments and online A/B tests. Our method achieves significant improvements with increases of 0.0142% in daily active users and +0.1144% in publications in Douyin, showcasing its practical applicability and scalability.
ContentV: Efficient Training of Video Generation Models with Limited Compute
Jun 05, 2025Recent advances in video generation demand increasingly efficient training recipes to mitigate escalating computational costs. In this report, we present ContentV, an 8B-parameter text-to-video model that achieves state-of-the-art performance (85.14 on VBench) after training on 256 x 64GB Neural Processing Units (NPUs) for merely four weeks. ContentV generates diverse, high-quality videos across multiple resolutions and durations from text prompts, enabled by three key innovations: (1) A minimalist architecture that maximizes reuse of pre-trained image generation models for video generation; (2) A systematic multi-stage training strategy leveraging flow matching for enhanced efficiency; and (3) A cost-effective reinforcement learning with human feedback framework that improves generation quality without requiring additional human annotations. All the code and models are available at: https://contentv.github.io.
AdaF^2M^2: Comprehensive Learning and Responsive Leveraging Features in Recommendation System
Jan 27, 2025



Feature modeling, which involves feature representation learning and leveraging, plays an essential role in industrial recommendation systems. However, the data distribution in real-world applications usually follows a highly skewed long-tail pattern due to the popularity bias, which easily leads to over-reliance on ID-based features, such as user/item IDs and ID sequences of interactions. Such over-reliance makes it hard for models to learn features comprehensively, especially for those non-ID meta features, e.g., user/item characteristics. Further, it limits the feature leveraging ability in models, getting less generalized and more susceptible to data noise. Previous studies on feature modeling focus on feature extraction and interaction, hardly noticing the problems brought about by the long-tail data distribution. To achieve better feature representation learning and leveraging on real-world data, we propose a model-agnostic framework AdaF^2M^2, short for Adaptive Feature Modeling with Feature Mask. The feature-mask mechanism helps comprehensive feature learning via multi-forward training with augmented samples, while the adapter applies adaptive weights on features responsive to different user/item states. By arming base models with AdaF^2M^2, we conduct online A/B tests on multiple recommendation scenarios, obtaining +1.37% and +1.89% cumulative improvements on user active days and app duration respectively. Besides, the extended offline experiments on different models show improvements as well. AdaF$^2$M$^2$ has been widely deployed on both retrieval and ranking tasks in multiple applications of Douyin Group, indicating its superior effectiveness and universality.
Long-Term Interest Clock: Fine-Grained Time Perception in Streaming Recommendation System
Jan 27, 2025


User interests manifest a dynamic pattern within the course of a day, e.g., a user usually favors soft music at 8 a.m. but may turn to ambient music at 10 p.m. To model dynamic interests in a day, hour embedding is widely used in traditional daily-trained industrial recommendation systems. However, its discreteness can cause periodical online patterns and instability in recent streaming recommendation systems. Recently, Interest Clock has achieved remarkable performance in streaming recommendation systems. Nevertheless, it models users' dynamic interests in a coarse-grained manner, merely encoding users' discrete interests of 24 hours from short-term behaviors. In this paper, we propose a fine-grained method for perceiving time information for streaming recommendation systems, named Long-term Interest Clock (LIC). The key idea of LIC is adaptively calculating current user interests by taking into consideration the relevance of long-term behaviors around current time (e.g., 8 a.m.) given a candidate item. LIC consists of two modules: (1) Clock-GSU retrieves a sub-sequence by searching through long-term behaviors, using query information from a candidate item and current time, (2) Clock-ESU employs a time-gap-aware attention mechanism to aggregate sub-sequence with the candidate item. With Clock-GSU and Clock-ESU, LIC is capable of capturing users' dynamic fine-grained interests from long-term behaviors. We conduct online A/B tests, obtaining +0.122% improvements on user active days. Besides, the extended offline experiments show improvements as well. Long-term Interest Clock has been integrated into Douyin Music App's recommendation system.
Real-time Indexing for Large-scale Recommendation by Streaming Vector Quantization Retriever
Jan 15, 2025Retrievers, which form one of the most important recommendation stages, are responsible for efficiently selecting possible positive samples to the later stages under strict latency limitations. Because of this, large-scale systems always rely on approximate calculations and indexes to roughly shrink candidate scale, with a simple ranking model. Considering simple models lack the ability to produce precise predictions, most of the existing methods mainly focus on incorporating complicated ranking models. However, another fundamental problem of index effectiveness remains unresolved, which also bottlenecks complication. In this paper, we propose a novel index structure: streaming Vector Quantization model, as a new generation of retrieval paradigm. Streaming VQ attaches items with indexes in real time, granting it immediacy. Moreover, through meticulous verification of possible variants, it achieves additional benefits like index balancing and reparability, enabling it to support complicated ranking models as existing approaches. As a lightweight and implementation-friendly architecture, streaming VQ has been deployed and replaced all major retrievers in Douyin and Douyin Lite, resulting in remarkable user engagement gain.
Interest Clock: Time Perception in Real-Time Streaming Recommendation System
Apr 30, 2024



User preferences follow a dynamic pattern over a day, e.g., at 8 am, a user might prefer to read news, while at 8 pm, they might prefer to watch movies. Time modeling aims to enable recommendation systems to perceive time changes to capture users' dynamic preferences over time, which is an important and challenging problem in recommendation systems. Especially, streaming recommendation systems in the industry, with only available samples of the current moment, present greater challenges for time modeling. There is still a lack of effective time modeling methods for streaming recommendation systems. In this paper, we propose an effective and universal method Interest Clock to perceive time information in recommendation systems. Interest Clock first encodes users' time-aware preferences into a clock (hour-level personalized features) and then uses Gaussian distribution to smooth and aggregate them into the final interest clock embedding according to the current time for the final prediction. By arming base models with Interest Clock, we conduct online A/B tests, obtaining +0.509% and +0.758% improvements on user active days and app duration respectively. Besides, the extended offline experiments show improvements as well. Interest Clock has been deployed on Douyin Music App.
Trinity: Syncretizing Multi-/Long-tail/Long-term Interests All in One
Feb 05, 2024Interest modeling in recommender system has been a constant topic for improving user experience, and typical interest modeling tasks (e.g. multi-interest, long-tail interest and long-term interest) have been investigated in many existing works. However, most of them only consider one interest in isolation, while neglecting their interrelationships. In this paper, we argue that these tasks suffer from a common "interest amnesia" problem, and a solution exists to mitigate it simultaneously. We figure that long-term cues can be the cornerstone since they reveal multi-interest and clarify long-tail interest. Inspired by the observation, we propose a novel and unified framework in the retrieval stage, "Trinity", to solve interest amnesia problem and improve multiple interest modeling tasks. We construct a real-time clustering system that enables us to project items into enumerable clusters, and calculate statistical interest histograms over these clusters. Based on these histograms, Trinity recognizes underdelivered themes and remains stable when facing emerging hot topics. Trinity is more appropriate for large-scale industry scenarios because of its modest computational overheads. Its derived retrievers have been deployed on the recommender system of Douyin, significantly improving user experience and retention. We believe that such practical experience can be well generalized to other scenarios.
Context-aware Ensemble of Multifaceted Factorization Models for Recommendation Prediction in Social Networks
May 03, 2021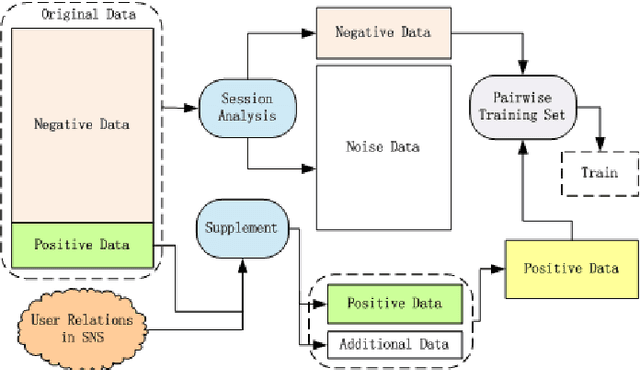
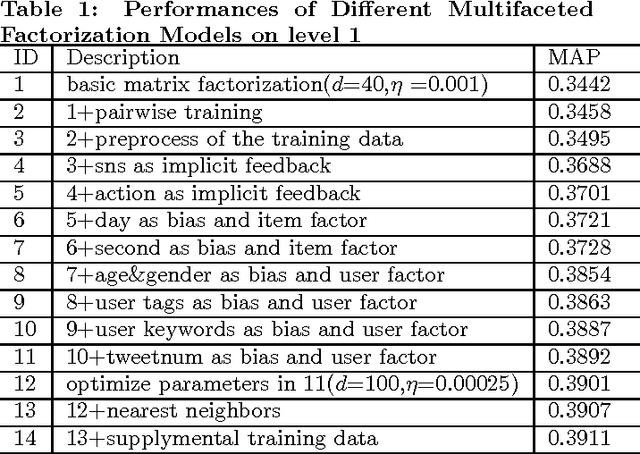
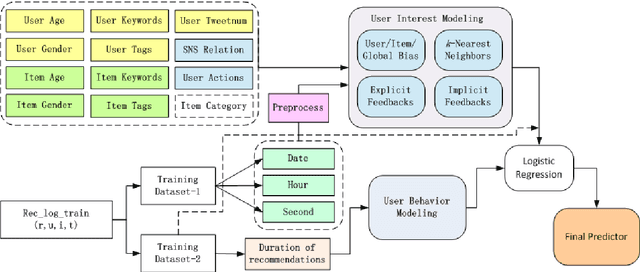

This paper describes the solution of Shanda Innovations team to Task 1 of KDD-Cup 2012. A novel approach called Multifaceted Factorization Models is proposed to incorporate a great variety of features in social networks. Social relationships and actions between users are integrated as implicit feedbacks to improve the recommendation accuracy. Keywords, tags, profiles, time and some other features are also utilized for modeling user interests. In addition, user behaviors are modeled from the durations of recommendation records. A context-aware ensemble framework is then applied to combine multiple predictors and produce final recommendation results. The proposed approach obtained 0.43959 (public score) / 0.41874 (private score) on the testing dataset, which achieved the 2nd place in the KDD-Cup competition.