 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Much MRI Preprocessing Is Enough? A Cost-Utility Study for Brain MRI Foundation Models
Jun 06, 2026MRI preprocessing defines the input distribution seen by brain MRI foundation models, yet it is usually treated as routine data cleaning rather than a modeling choice. We ask how much preprocessing is worth its computational cost for self-supervised 3D MRI pretraining. Keeping the corpus, 3D ViT backbone, masking protocol, and downstream evaluations fixed, we compare a graded P0-P7 preprocessing spectrum for masked autoencoding (MAE) and joint-embedding predictive learning (JEPA) on 20,000 heterogeneous brain MRI volumes, then transfer the encoders to IDH prediction, MCI classification, brain age regression, and GLI/PED tumor segmentation. The results do not support a simple "more is better" rule. P0/P1 are numerically unstable, making P2 the lowest-cost feasible level; beyond P2, choosing the best feasible preprocessing level improves aggregate utility by only 3.4 percentage points for MAE and 1.8 percentage points for JEPA, with most paired gains statistically unresolved. Stronger preprocessing is beneficial only in selected regimes: IDH improves modestly, AGE and GLI/PED are often near or best at P2, and MCI shows the clearest empirical P7 gain. Cross-level MCI transfer further shows that much of the P7 advantage can be recovered by applying stronger preprocessing downstream, without requiring P7 throughout pretraining. These findings recast MRI preprocessing as a downstream-aware cost-utility decision rather than a default escalation pipeline. Code is available at https://github.com/PangJiangShuan/PreBrain.
Determinism in the Undetermined: Deterministic Output in Charge-Conserving Continuous-Time Neuromorphic Systems with Temporal Stochasticity
Mar 16, 2026Achieving deterministic computation results in asynchronous neuromorphic systems remains a fundamental challenge due to the inherent temporal stochasticity of continuous-time hardware. To address this, we develop a unified continuous-time framework for spiking neural networks (SNNs) that couples the Law of Charge Conservation with minimal neuron-level constraints. This integration ensures that the terminal state depends solely on the aggregate input charge, providing a unique cumulated output invariant to temporal stochasticity. We prove that this mapping is strictly invariant to spike timing in acyclic networks, whereas recurrent connectivity can introduce temporal sensitivity. Furthermore, we establish an exact representational correspondence between these charge-conserving SNNs and quantized artificial neural networks, bridging the gap between static deep learning and event-driven dynamics without approximation errors. These results establish a rigorous theoretical basis for designing continuous-time neuromorphic systems that harness the efficiency of asynchronous processing while maintaining algorithmic determinism.
ERNIE 5.0 Technical Report
Feb 04, 2026In this report, we introduce ERNIE 5.0, a natively autoregressive foundation model desinged for unified multimodal understanding and generation across text, image, video, and audio. All modalities are trained from scratch under a unified next-group-of-tokens prediction objective, based on an ultra-sparse mixture-of-experts (MoE) architecture with modality-agnostic expert routing. To address practical challenges in large-scale deployment under diverse resource constraints, ERNIE 5.0 adopts a novel elastic training paradigm. Within a single pre-training run, the model learns a family of sub-models with varying depths, expert capacities, and routing sparsity, enabling flexible trade-offs among performance, model size, and inference latency in memory- or time-constrained scenarios. Moreover, we systematically address the challenges of scaling reinforcement learning to unified foundation models, thereby guaranteeing efficient and stable post-training under ultra-sparse MoE architectures and diverse multimodal settings. Extensive experiments demonstrate that ERNIE 5.0 achieves strong and balanced performance across multiple modalities. To the best of our knowledge, among publicly disclosed models, ERNIE 5.0 represents the first production-scale realization of a trillion-parameter unified autoregressive model that supports both multimodal understanding and generation. To facilitate further research, we present detailed visualizations of modality-agnostic expert routing in the unified model, alongside comprehensive empirical analysis of elastic training, aiming to offer profound insights to the community.
MERGE: Next-Generation Item Indexing Paradigm for Large-Scale Streaming Recommendation
Jan 28, 2026Item indexing, which maps a large corpus of items into compact discrete representations, is critical for both discriminative and generative recommender systems, yet existing Vector Quantization (VQ)-based approaches struggle with the highly skewed and non-stationary item distributions common in streaming industry recommenders, leading to poor assignment accuracy, imbalanced cluster occupancy, and insufficient cluster separation. To address these challenges, we propose MERGE, a next-generation item indexing paradigm that adaptively constructs clusters from scratch, dynamically monitors cluster occupancy, and forms hierarchical index structures via fine-to-coarse merging. Extensive experiments demonstrate that MERGE significantly improves assignment accuracy, cluster uniformity, and cluster separation compared with existing indexing methods, while online A/B tests show substantial gains in key business metrics, highlighting its potential as a foundational indexing approach for large-scale recommendation.
Reconstructing Quantitative Cerebral Perfusion Images Directly From Measured Sinogram Data Acquired Using C-arm Cone-Beam CT
Dec 06, 2024



To shorten the door-to-puncture time for better treating patients with acute ischemic stroke, it is highly desired to obtain quantitative cerebral perfusion images using C-arm cone-beam computed tomography (CBCT) equipped in the interventional suite. However, limited by the slow gantry rotation speed, the temporal resolution and temporal sampling density of typical C-arm CBCT are much poorer than those of multi-detector-row CT in the diagnostic imaging suite. The current quantitative perfusion imaging includes two cascaded steps: time-resolved image reconstruction and perfusion parametric estimation. For time-resolved image reconstruction, the technical challenge imposed by poor temporal resolution and poor sampling density causes inaccurate quantification of the temporal variation of cerebral artery and tissue attenuation values. For perfusion parametric estimation, it remains a technical challenge to appropriately design the handcrafted regularization for better solving the associated deconvolution problem. These two challenges together prevent obtaining quantitatively accurate perfusion images using C-arm CBCT. The purpose of this work is to simultaneously address these two challenges by combining the two cascaded steps into a single joint optimization problem and reconstructing quantitative perfusion images directly from the measured sinogram data. In the developed direct cerebral perfusion parametric image reconstruction technique, TRAINER in short, the quantitative perfusion images have been represented as a subject-specific conditional generative model trained under the constraint of the time-resolved CT forward model, perfusion convolutional model, and the subject's own measured sinogram data. Results shown in this paper demonstrated that using TRAINER, quantitative cerebral perfusion images can be accurately obtained using C-arm CBCT in the interventional suite.
RLCP: A Reinforcement Learning-based Copyright Protection Method for Text-to-Image Diffusion Model
Sep 02, 2024



The increasing sophistication of text-to-image generative models has led to complex challenges in defining and enforcing copyright infringement criteria and protection. Existing methods, such as watermarking and dataset deduplication, fail to provide comprehensive solutions due to the lack of standardized metrics and the inherent complexity of addressing copyright infringement in diffusion models. To deal with these challenges, we propose a Reinforcement Learning-based Copyright Protection(RLCP) method for Text-to-Image Diffusion Model, which minimizes the generation of copyright-infringing content while maintaining the quality of the model-generated dataset. Our approach begins with the introduction of a novel copyright metric grounded in copyright law and court precedents on infringement. We then utilize the Denoising Diffusion Policy Optimization (DDPO) framework to guide the model through a multi-step decision-making process, optimizing it using a reward function that incorporates our proposed copyright metric. Additionally, we employ KL divergence as a regularization term to mitigate some failure modes and stabilize RL fine-tuning. Experiments conducted on 3 mixed datasets of copyright and non-copyright images demonstrate that our approach significantly reduces copyright infringement risk while maintaining image quality.
Trinity: Syncretizing Multi-/Long-tail/Long-term Interests All in One
Feb 05, 2024Interest modeling in recommender system has been a constant topic for improving user experience, and typical interest modeling tasks (e.g. multi-interest, long-tail interest and long-term interest) have been investigated in many existing works. However, most of them only consider one interest in isolation, while neglecting their interrelationships. In this paper, we argue that these tasks suffer from a common "interest amnesia" problem, and a solution exists to mitigate it simultaneously. We figure that long-term cues can be the cornerstone since they reveal multi-interest and clarify long-tail interest. Inspired by the observation, we propose a novel and unified framework in the retrieval stage, "Trinity", to solve interest amnesia problem and improve multiple interest modeling tasks. We construct a real-time clustering system that enables us to project items into enumerable clusters, and calculate statistical interest histograms over these clusters. Based on these histograms, Trinity recognizes underdelivered themes and remains stable when facing emerging hot topics. Trinity is more appropriate for large-scale industry scenarios because of its modest computational overheads. Its derived retrievers have been deployed on the recommender system of Douyin, significantly improving user experience and retention. We believe that such practical experience can be well generalized to other scenarios.
The Blessings of Multiple Treatments and Outcomes in Treatment Effect Estimation
Oct 14, 2023



Assessing causal effects in the presence of unobserved confounding is a challenging problem. Existing studies leveraged proxy variables or multiple treatments to adjust for the confounding bias. In particular, the latter approach attributes the impact on a single outcome to multiple treatments, allowing estimating latent variables for confounding control. Nevertheless, these methods primarily focus on a single outcome, whereas in many real-world scenarios, there is greater interest in studying the effects on multiple outcomes. Besides, these outcomes are often coupled with multiple treatments. Examples include the intensive care unit (ICU), where health providers evaluate the effectiveness of therapies on multiple health indicators. To accommodate these scenarios, we consider a new setting dubbed as multiple treatments and multiple outcomes. We then show that parallel studies of multiple outcomes involved in this setting can assist each other in causal identification, in the sense that we can exploit other treatments and outcomes as proxies for each treatment effect under study. We proceed with a causal discovery method that can effectively identify such proxies for causal estimation. The utility of our method is demonstrated in synthetic data and sepsis disease.
SMoA: Sparse Mixture of Adapters to Mitigate Multiple Dataset Biases
Feb 28, 2023



Recent studies reveal that various biases exist in different NLP tasks, and over-reliance on biases results in models' poor generalization ability and low adversarial robustness. To mitigate datasets biases, previous works propose lots of debiasing techniques to tackle specific biases, which perform well on respective adversarial sets but fail to mitigate other biases. In this paper, we propose a new debiasing method Sparse Mixture-of-Adapters (SMoA), which can mitigate multiple dataset biases effectively and efficiently. Experiments on Natural Language Inference and Paraphrase Identification tasks demonstrate that SMoA outperforms full-finetuning, adapter tuning baselines, and prior strong debiasing methods. Further analysis indicates the interpretability of SMoA that sub-adapter can capture specific pattern from the training data and specialize to handle specific bias.
Less Learn Shortcut: Analyzing and Mitigating Learning of Spurious Feature-Label Correlation
May 25, 2022
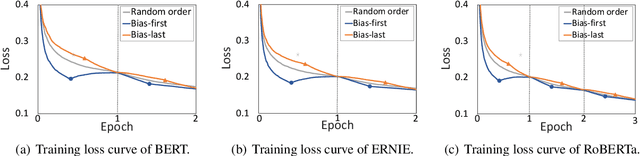
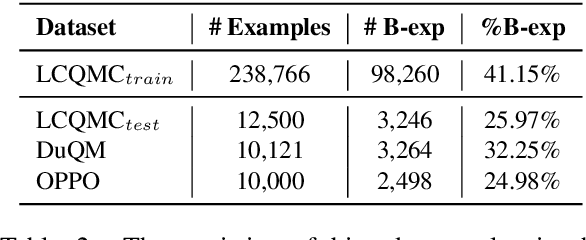
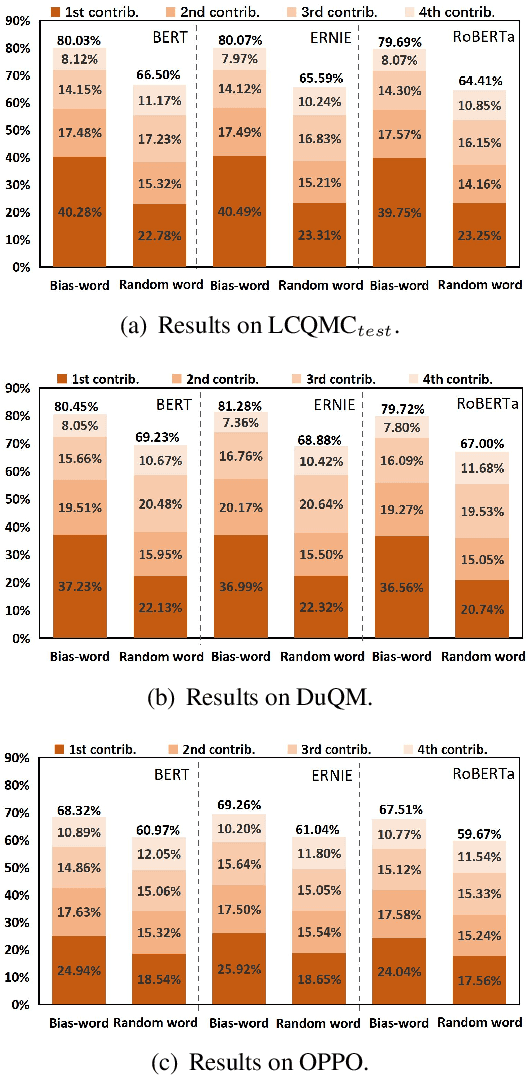
Many recent works indicate that the deep neural networks tend to take dataset biases as shortcuts to make decision, rather than understand the tasks, which results in failures on the real-world applications. In this work, we focus on the spurious correlation between feature and label, which derive from the biased data distribution in the training data, and analyze it concretely. In particular, we define the word highly co-occurring with a specific label as biased word, and the example containing biased word as biased example. Our analysis reveals that the biased examples with spurious correlations are easier for models to learn, and when predicting, the biased words make significantly higher contributions to models' predictions than other words, and the models tend to assign the labels over-relying on the spurious correlation between words and labels. To mitigate the model's over-reliance on the shortcut, we propose a training strategy Less-Learn-Shortcut (LLS): we quantify the biased degree of the biased examples, and down-weight them with the biased degree. Experimental results on QM and NLI tasks show that the models improve the performances both on in-domain and adversarial data (1.57% on DuQM and 2.12% on HANS) with our LLS.