 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCost-aware Cascading Bandits
Paper and Code
May 22, 2018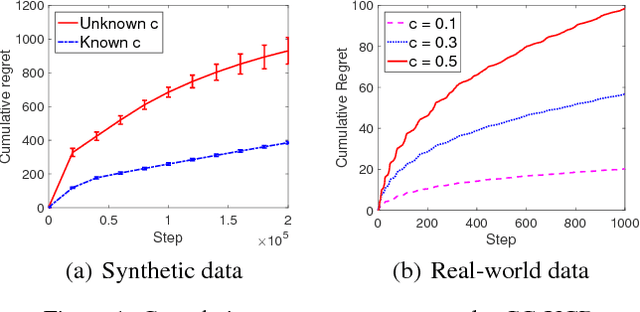
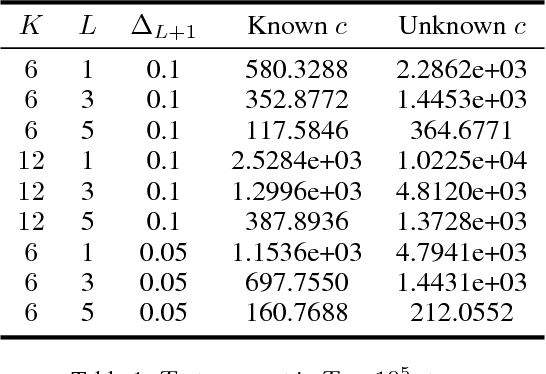
In this paper, we propose a cost-aware cascading bandits model, a new variant of multi-armed ban- dits with cascading feedback, by considering the random cost of pulling arms. In each step, the learning agent chooses an ordered list of items and examines them sequentially, until certain stopping condition is satisfied. Our objective is then to max- imize the expected net reward in each step, i.e., the reward obtained in each step minus the total cost in- curred in examining the items, by deciding the or- dered list of items, as well as when to stop examina- tion. We study both the offline and online settings, depending on whether the state and cost statistics of the items are known beforehand. For the of- fline setting, we show that the Unit Cost Ranking with Threshold 1 (UCR-T1) policy is optimal. For the online setting, we propose a Cost-aware Cas- cading Upper Confidence Bound (CC-UCB) algo- rithm, and show that the cumulative regret scales in O(log T ). We also provide a lower bound for all {\alpha}-consistent policies, which scales in {\Omega}(log T ) and matches our upper bound. The performance of the CC-UCB algorithm is evaluated with both synthetic and real-world data.