 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Learning with Diverse User Preferences
Feb 04, 2019
In this paper, we investigate the impact of diverse user preference on learning under the stochastic multi-armed bandit (MAB) framework. We aim to show that when the user preferences are sufficiently diverse and each arm can be optimal for certain users, the O(log T) regret incurred by exploring the sub-optimal arms under the standard stochastic MAB setting can be reduced to a constant. Our intuition is that to achieve sub-linear regret, the number of times an optimal arm being pulled should scale linearly in time; when all arms are optimal for certain users and pulled frequently, the estimated arm statistics can quickly converge to their true values, thus reducing the need of exploration dramatically. We cast the problem into a stochastic linear bandits model, where both the users preferences and the state of arms are modeled as {independent and identical distributed (i.i.d)} d-dimensional random vectors. After receiving the user preference vector at the beginning of each time slot, the learner pulls an arm and receives a reward as the linear product of the preference vector and the arm state vector. We also assume that the state of the pulled arm is revealed to the learner once its pulled. We propose a Weighted Upper Confidence Bound (W-UCB) algorithm and show that it can achieve a constant regret when the user preferences are sufficiently diverse. The performance of W-UCB under general setups is also completely characterized and validated with synthetic data.
Cost-aware Cascading Bandits
May 22, 2018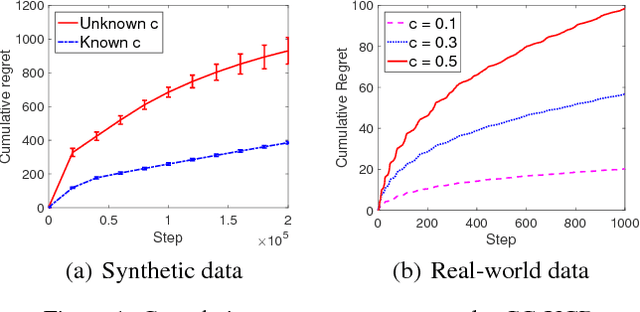
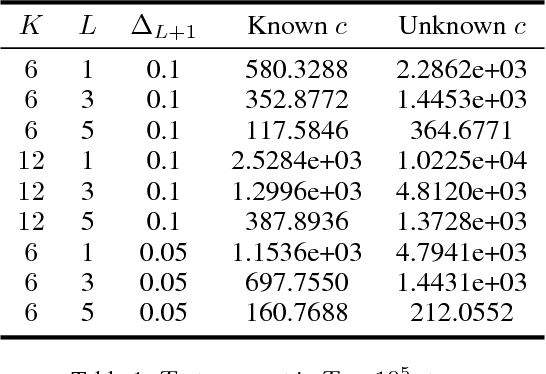
In this paper, we propose a cost-aware cascading bandits model, a new variant of multi-armed ban- dits with cascading feedback, by considering the random cost of pulling arms. In each step, the learning agent chooses an ordered list of items and examines them sequentially, until certain stopping condition is satisfied. Our objective is then to max- imize the expected net reward in each step, i.e., the reward obtained in each step minus the total cost in- curred in examining the items, by deciding the or- dered list of items, as well as when to stop examina- tion. We study both the offline and online settings, depending on whether the state and cost statistics of the items are known beforehand. For the of- fline setting, we show that the Unit Cost Ranking with Threshold 1 (UCR-T1) policy is optimal. For the online setting, we propose a Cost-aware Cas- cading Upper Confidence Bound (CC-UCB) algo- rithm, and show that the cumulative regret scales in O(log T ). We also provide a lower bound for all {\alpha}-consistent policies, which scales in {\Omega}(log T ) and matches our upper bound. The performance of the CC-UCB algorithm is evaluated with both synthetic and real-world data.
Cost-Aware Learning and Optimization for Opportunistic Spectrum Access
Apr 11, 2018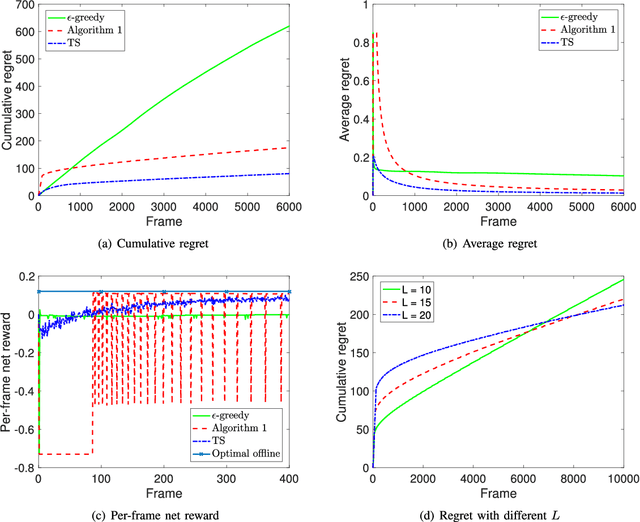
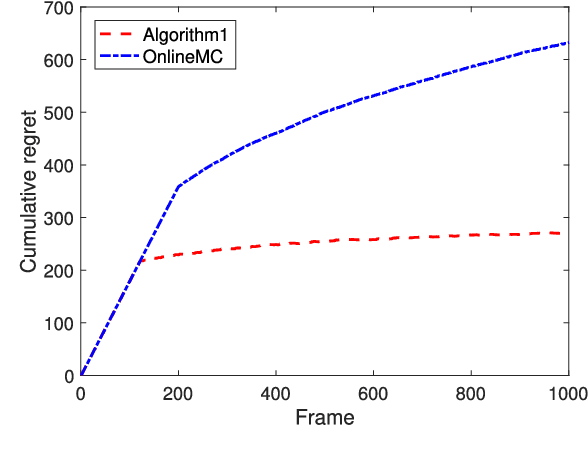
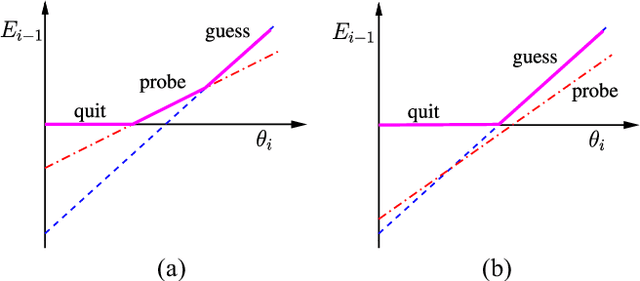
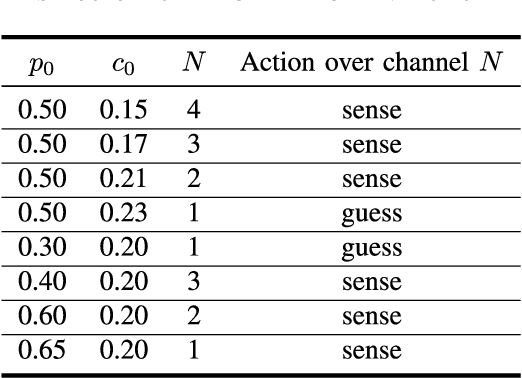
In this paper, we investigate cost-aware joint learning and optimization for multi-channel opportunistic spectrum access in a cognitive radio system. We investigate a discrete time model where the time axis is partitioned into frames. Each frame consists of a sensing phase, followed by a transmission phase. During the sensing phase, the user is able to sense a subset of channels sequentially before it decides to use one of them in the following transmission phase. We assume the channel states alternate between busy and idle according to independent Bernoulli random processes from frame to frame. To capture the inherent uncertainty in channel sensing, we assume the reward of each transmission when the channel is idle is a random variable. We also associate random costs with sensing and transmission actions. Our objective is to understand how the costs and reward of the actions would affect the optimal behavior of the user in both offline and online settings, and design the corresponding opportunistic spectrum access strategies to maximize the expected cumulative net reward (i.e., reward-minus-cost). We start with an offline setting where the statistics of the channel status, costs and reward are known beforehand. We show that the the optimal policy exhibits a recursive double threshold structure, and the user needs to compare the channel statistics with those thresholds sequentially in order to decide its actions. With such insights, we then study the online setting, where the statistical information of the channels, costs and reward are unknown a priori. We judiciously balance exploration and exploitation, and show that the cumulative regret scales in O(log T). We also establish a matched lower bound, which implies that our online algorithm is order-optimal. Simulation results corroborate our theoretical analysis.