 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-time Indexing for Large-scale Recommendation by Streaming Vector Quantization Retriever
Jan 15, 2025Retrievers, which form one of the most important recommendation stages, are responsible for efficiently selecting possible positive samples to the later stages under strict latency limitations. Because of this, large-scale systems always rely on approximate calculations and indexes to roughly shrink candidate scale, with a simple ranking model. Considering simple models lack the ability to produce precise predictions, most of the existing methods mainly focus on incorporating complicated ranking models. However, another fundamental problem of index effectiveness remains unresolved, which also bottlenecks complication. In this paper, we propose a novel index structure: streaming Vector Quantization model, as a new generation of retrieval paradigm. Streaming VQ attaches items with indexes in real time, granting it immediacy. Moreover, through meticulous verification of possible variants, it achieves additional benefits like index balancing and reparability, enabling it to support complicated ranking models as existing approaches. As a lightweight and implementation-friendly architecture, streaming VQ has been deployed and replaced all major retrievers in Douyin and Douyin Lite, resulting in remarkable user engagement gain.
Trinity: Syncretizing Multi-/Long-tail/Long-term Interests All in One
Feb 05, 2024Interest modeling in recommender system has been a constant topic for improving user experience, and typical interest modeling tasks (e.g. multi-interest, long-tail interest and long-term interest) have been investigated in many existing works. However, most of them only consider one interest in isolation, while neglecting their interrelationships. In this paper, we argue that these tasks suffer from a common "interest amnesia" problem, and a solution exists to mitigate it simultaneously. We figure that long-term cues can be the cornerstone since they reveal multi-interest and clarify long-tail interest. Inspired by the observation, we propose a novel and unified framework in the retrieval stage, "Trinity", to solve interest amnesia problem and improve multiple interest modeling tasks. We construct a real-time clustering system that enables us to project items into enumerable clusters, and calculate statistical interest histograms over these clusters. Based on these histograms, Trinity recognizes underdelivered themes and remains stable when facing emerging hot topics. Trinity is more appropriate for large-scale industry scenarios because of its modest computational overheads. Its derived retrievers have been deployed on the recommender system of Douyin, significantly improving user experience and retention. We believe that such practical experience can be well generalized to other scenarios.
POSO: Personalized Cold Start Modules for Large-scale Recommender Systems
Aug 24, 2021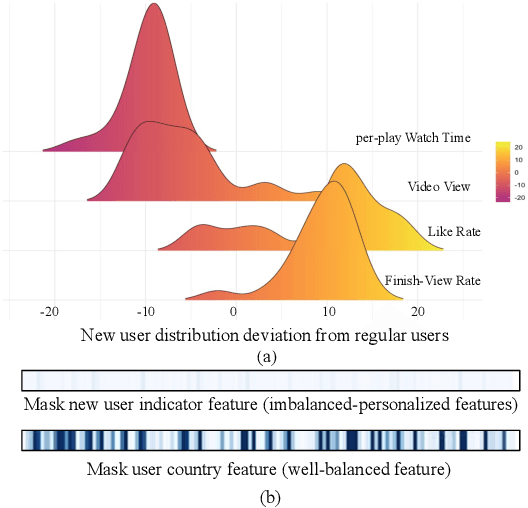
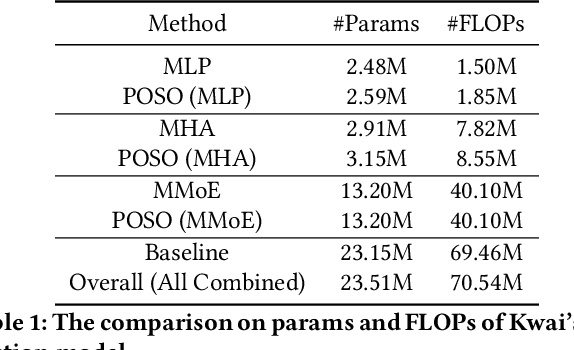
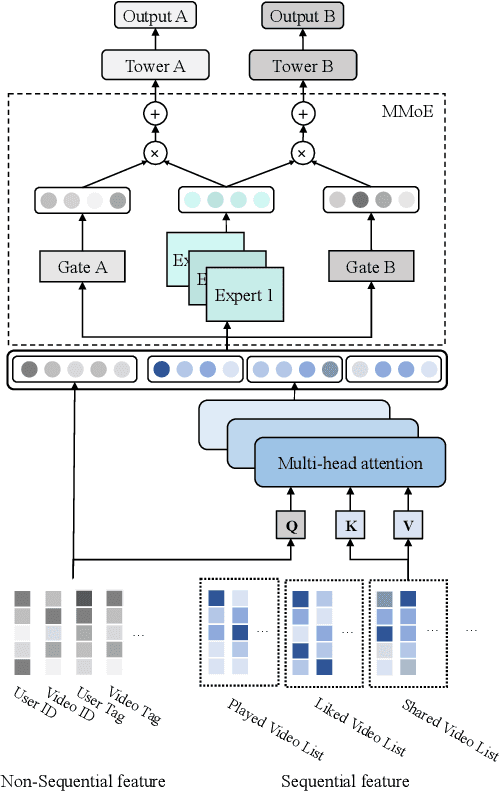
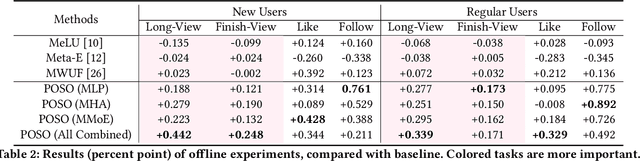
Recommendation for new users, also called user cold start, has been a well-recognized challenge for online recommender systems. Most existing methods view the crux as the lack of initial data. However, in this paper, we argue that there are neglected problems: 1) New users' behaviour follows much different distributions from regular users. 2) Although personalized features are involved, heavily imbalanced samples prevent the model from balancing new/regular user distributions, as if the personalized features are overwhelmed. We name the problem as the "submergence" of personalization. To tackle this problem, we propose a novel module: Personalized COld Start MOdules (POSO). Considering from a model architecture perspective, POSO personalizes existing modules by introducing multiple user-group-specialized sub-modules. Then, it fuses their outputs by personalized gates, resulting in comprehensive representations. In such way, POSO projects imbalanced features to even modules. POSO can be flexibly integrated into many existing modules and effectively improves their performance with negligible computational overheads. The proposed method shows remarkable advantage in industrial scenario. It has been deployed on the large-scale recommender system of Kwai, and improves new user Watch Time by a large margin (+7.75%). Moreover, POSO can be further generalized to regular users, inactive users and returning users (+2%-3% on Watch Time), as well as item cold start (+3.8% on Watch Time). Its effectiveness has also been verified on public dataset (MovieLens 20M). We believe such practical experience can be well generalized to other scenarios.
Short Video-based Advertisements Evaluation System: Self-Organizing Learning Approach
Oct 23, 2020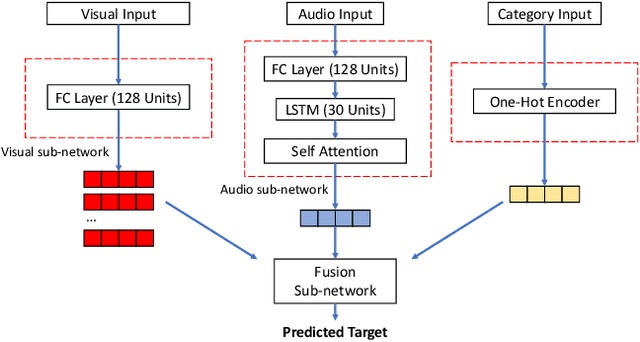
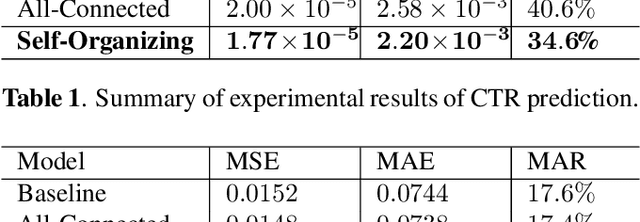
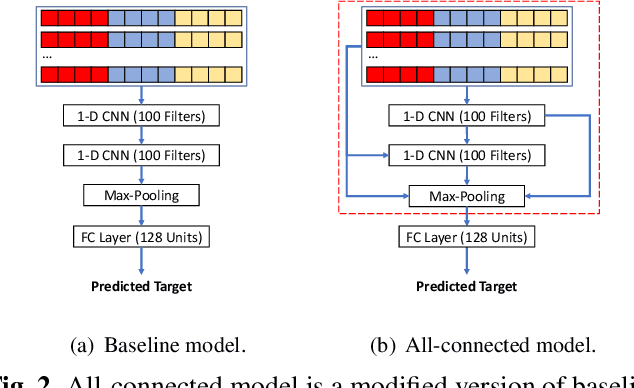
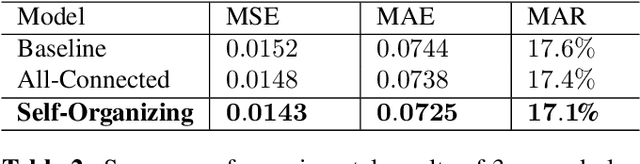
With the rising of short video apps, such as TikTok, Snapchat and Kwai, advertisement in short-term user-generated videos (UGVs) has become a trending form of advertising. Prediction of user behavior without specific user profile is required by advertisers, as they expect to acquire advertisement performance in advance in the scenario of cold start. Current recommender system do not take raw videos as input; additionally, most previous work of Multi-Modal Machine Learning may not deal with unconstrained videos like UGVs. In this paper, we proposed a novel end-to-end self-organizing framework for user behavior prediction. Our model is able to learn the optimal topology of neural network architecture, as well as optimal weights, through training data. We evaluate our proposed method on our in-house dataset. The experimental results reveal that our model achieves the best performance in all our experiments.
Effective Domain Knowledge Transfer with Soft Fine-tuning
Sep 05, 2019



Convolutional neural networks require numerous data for training. Considering the difficulties in data collection and labeling in some specific tasks, existing approaches generally use models pre-trained on a large source domain (e.g. ImageNet), and then fine-tune them on these tasks. However, the datasets from source domain are simply discarded in the fine-tuning process. We argue that the source datasets could be better utilized and benefit fine-tuning. This paper firstly introduces the concept of general discrimination to describe ability of a network to distinguish untrained patterns, and then experimentally demonstrates that general discrimination could potentially enhance the total discrimination ability on target domain. Furthermore, we propose a novel and light-weighted method, namely soft fine-tuning. Unlike traditional fine-tuning which directly replaces optimization objective by a loss function on the target domain, soft fine-tuning effectively keeps general discrimination by holding the previous loss and removes it softly. By doing so, soft fine-tuning improves the robustness of the network to data bias, and meanwhile accelerates the convergence. We evaluate our approach on several visual recognition tasks. Extensive experimental results support that soft fine-tuning provides consistent improvement on all evaluated tasks, and outperforms the state-of-the-art significantly. Codes will be made available to the public.
Single Image Action Recognition using Semantic Body Part Actions
Dec 14, 2016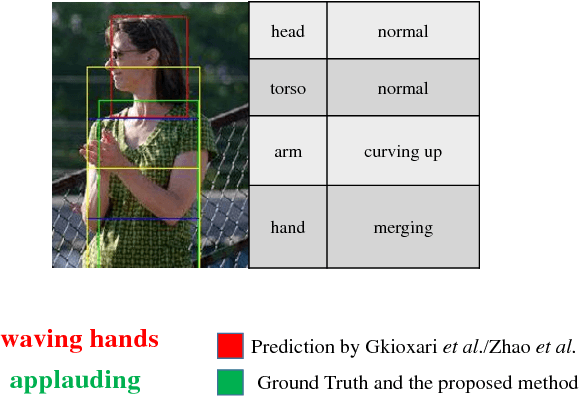
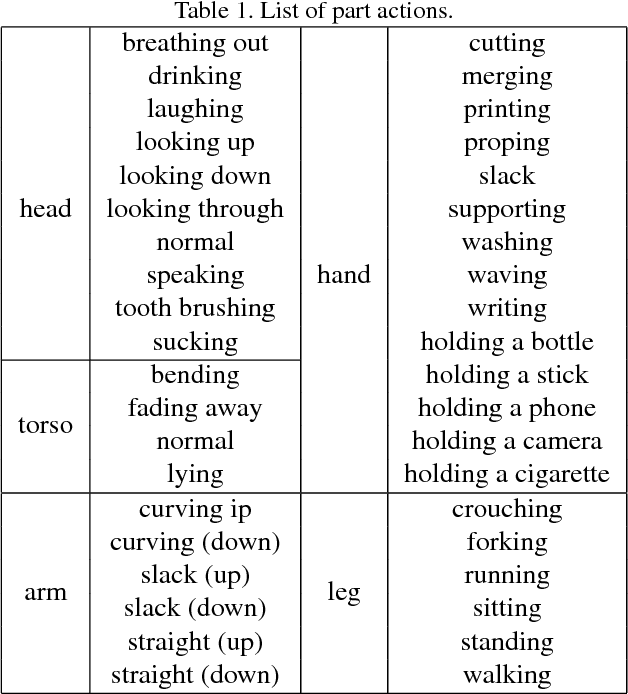
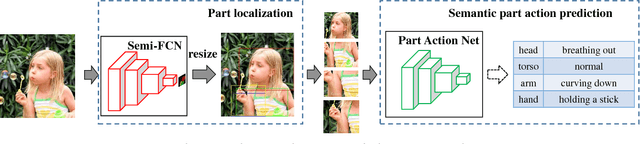

In this paper, we propose a novel single image action recognition algorithm which is based on the idea of semantic body part actions. Unlike existing bottom up methods, we argue that the human action is a combination of meaningful body part actions. In detail, we divide human body into five parts: head, torso, arms, hands and legs. And for each of the body parts, we define several semantic body part actions, e.g., hand holding, hand waving. These semantic body part actions are strongly related to the body actions, e.g., writing, and jogging. Based on the idea, we propose a deep neural network based system: first, body parts are localized by a Semi-FCN network. Second, for each body parts, a Part Action Res-Net is used to predict semantic body part actions. And finally, we use SVM to fuse the body part actions and predict the entire body action. Experiments on two dataset: PASCAL VOC 2012 and Stanford-40 report mAP improvement from the state-of-the-art by 3.8% and 2.6% respectively.