 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUni-ViGU: Towards Unified Video Generation and Understanding via A Diffusion-Based Video Generator
Apr 09, 2026Unified multimodal models integrating visual understanding and generation face a fundamental challenge: visual generation incurs substantially higher computational costs than understanding, particularly for video. This imbalance motivates us to invert the conventional paradigm: rather than extending understanding-centric MLLMs to support generation, we propose Uni-ViGU, a framework that unifies video generation and understanding by extending a video generator as the foundation. We introduce a unified flow method that performs continuous flow matching for video and discrete flow matching for text within a single process, enabling coherent multimodal generation. We further propose a modality-driven MoE-based framework that augments Transformer blocks with lightweight layers for text generation while preserving generative priors. To repurpose generation knowledge for understanding, we design a bidirectional training mechanism with two stages: Knowledge Recall reconstructs input prompts to leverage learned text-video correspondences, while Capability Refinement fine-tunes on detailed captions to establish discriminative shared representations. Experiments demonstrate that Uni-ViGU achieves competitive performance on both video generation and understanding, validating generation-centric architectures as a scalable path toward unified multimodal intelligence. Project Page and Code: https://fr0zencrane.github.io/uni-vigu-page/.
Nipping the Drift in the Bud: Retrospective Rectification for Robust Vision-Language Navigation
Feb 06, 2026Vision-Language Navigation (VLN) requires embodied agents to interpret natural language instructions and navigate through complex continuous 3D environments. However, the dominant imitation learning paradigm suffers from exposure bias, where minor deviations during inference lead to compounding errors. While DAgger-style approaches attempt to mitigate this by correcting error states, we identify a critical limitation: Instruction-State Misalignment. Forcing an agent to learn recovery actions from off-track states often creates supervision signals that semantically conflict with the original instruction. In response to these challenges, we introduce BudVLN, an online framework that learns from on-policy rollouts by constructing supervision to match the current state distribution. BudVLN performs retrospective rectification via counterfactual re-anchoring and decision-conditioned supervision synthesis, using a geodesic oracle to synthesize corrective trajectories that originate from valid historical states, ensuring semantic consistency. Experiments on the standard R2R-CE and RxR-CE benchmarks demonstrate that BudVLN consistently mitigates distribution shift and achieves state-of-the-art performance in both Success Rate and SPL.
UniCon: A Unified System for Efficient Robot Learning Transfers
Jan 21, 2026Deploying learning-based controllers across heterogeneous robots is challenging due to platform differences, inconsistent interfaces, and inefficient middleware. To address these issues, we present UniCon, a lightweight framework that standardizes states, control flow, and instrumentation across platforms. It decomposes workflows into execution graphs with reusable components, separating system states from control logic to enable plug-and-play deployment across various robot morphologies. Unlike traditional middleware, it prioritizes efficiency through batched, vectorized data flow, minimizing communication overhead and improving inference latency. This modular, data-oriented approach enables seamless sim-to-real transfer with minimal re-engineering. We demonstrate that UniCon reduces code redundancy when transferring workflows and achieves higher inference efficiency compared to ROS-based systems. Deployed on over 12 robot models from 7 manufacturers, it has been successfully integrated into ongoing research projects, proving its effectiveness in real-world scenarios.
Microscopic Robots That Sense, Think, Act, and Compute
Mar 29, 2025While miniaturization has been a goal in robotics for nearly 40 years, roboticists have struggled to access sub-millimeter dimensions without making sacrifices to on-board information processing due to the unique physics of the microscale. Consequently, microrobots often lack the key features that distinguish their macroscopic cousins from other machines, namely on-robot systems for decision making, sensing, feedback, and programmable computation. Here, we take up the challenge of building a microrobot comparable in size to a single-celled paramecium that can sense, think, and act using onboard systems for computation, sensing, memory, locomotion, and communication. Built massively in parallel with fully lithographic processing, these microrobots can execute digitally defined algorithms and autonomously change behavior in response to their surroundings. Combined, these results pave the way for general purpose microrobots that can be programmed many times in a simple setup, cost under $0.01 per machine, and work together to carry out tasks without supervision in uncertain environments.
Beyond Feature Mapping GAP: Integrating Real HDRTV Priors for Superior SDRTV-to-HDRTV Conversion
Nov 16, 2024



The rise of HDR-WCG display devices has highlighted the need to convert SDRTV to HDRTV, as most video sources are still in SDR. Existing methods primarily focus on designing neural networks to learn a single-style mapping from SDRTV to HDRTV. However, the limited information in SDRTV and the diversity of styles in real-world conversions render this process an ill-posed problem, thereby constraining the performance and generalization of these methods. Inspired by generative approaches, we propose a novel method for SDRTV to HDRTV conversion guided by real HDRTV priors. Despite the limited information in SDRTV, introducing real HDRTV as reference priors significantly constrains the solution space of the originally high-dimensional ill-posed problem. This shift transforms the task from solving an unreferenced prediction problem to making a referenced selection, thereby markedly enhancing the accuracy and reliability of the conversion process. Specifically, our approach comprises two stages: the first stage employs a Vector Quantized Generative Adversarial Network to capture HDRTV priors, while the second stage matches these priors to the input SDRTV content to recover realistic HDRTV outputs. We evaluate our method on public datasets, demonstrating its effectiveness with significant improvements in both objective and subjective metrics across real and synthetic datasets.
An End-to-End Real-World Camera Imaging Pipeline
Nov 16, 2024



Recent advances in neural camera imaging pipelines have demonstrated notable progress. Nevertheless, the real-world imaging pipeline still faces challenges including the lack of joint optimization in system components, computational redundancies, and optical distortions such as lens shading.In light of this, we propose an end-to-end camera imaging pipeline (RealCamNet) to enhance real-world camera imaging performance. Our methodology diverges from conventional, fragmented multi-stage image signal processing towards end-to-end architecture. This architecture facilitates joint optimization across the full pipeline and the restoration of coordinate-biased distortions. RealCamNet is designed for high-quality conversion from RAW to RGB and compact image compression. Specifically, we deeply analyze coordinate-dependent optical distortions, e.g., vignetting and dark shading, and design a novel Coordinate-Aware Distortion Restoration (CADR) module to restore coordinate-biased distortions. Furthermore, we propose a Coordinate-Independent Mapping Compression (CIMC) module to implement tone mapping and redundant information compression. Existing datasets suffer from misalignment and overly idealized conditions, making them inadequate for training real-world imaging pipelines. Therefore, we collected a real-world imaging dataset. Experiment results show that RealCamNet achieves the best rate-distortion performance with lower inference latency.
Diff-Tracker: Text-to-Image Diffusion Models are Unsupervised Trackers
Jul 11, 2024



We introduce Diff-Tracker, a novel approach for the challenging unsupervised visual tracking task leveraging the pre-trained text-to-image diffusion model. Our main idea is to leverage the rich knowledge encapsulated within the pre-trained diffusion model, such as the understanding of image semantics and structural information, to address unsupervised visual tracking. To this end, we design an initial prompt learner to enable the diffusion model to recognize the tracking target by learning a prompt representing the target. Furthermore, to facilitate dynamic adaptation of the prompt to the target's movements, we propose an online prompt updater. Extensive experiments on five benchmark datasets demonstrate the effectiveness of our proposed method, which also achieves state-of-the-art performance.
Active Learning Enabled Low-cost Cell Image Segmentation Using Bounding Box Annotation
May 02, 2024Cell image segmentation is usually implemented using fully supervised deep learning methods, which heavily rely on extensive annotated training data. Yet, due to the complexity of cell morphology and the requirement for specialized knowledge, pixel-level annotation of cell images has become a highly labor-intensive task. To address the above problems, we propose an active learning framework for cell segmentation using bounding box annotations, which greatly reduces the data annotation cost of cell segmentation algorithms. First, we generate a box-supervised learning method (denoted as YOLO-SAM) by combining the YOLOv8 detector with the Segment Anything Model (SAM), which effectively reduces the complexity of data annotation. Furthermore, it is integrated into an active learning framework that employs the MC DropBlock method to train the segmentation model with fewer box-annotated samples. Extensive experiments demonstrate that our model saves more than ninety percent of data annotation time compared to mask-supervised deep learning methods.
Beyond Alignment: Blind Video Face Restoration via Parsing-Guided Temporal-Coherent Transformer
Apr 21, 2024



Multiple complex degradations are coupled in low-quality video faces in the real world. Therefore, blind video face restoration is a highly challenging ill-posed problem, requiring not only hallucinating high-fidelity details but also enhancing temporal coherence across diverse pose variations. Restoring each frame independently in a naive manner inevitably introduces temporal incoherence and artifacts from pose changes and keypoint localization errors. To address this, we propose the first blind video face restoration approach with a novel parsing-guided temporal-coherent transformer (PGTFormer) without pre-alignment. PGTFormer leverages semantic parsing guidance to select optimal face priors for generating temporally coherent artifact-free results. Specifically, we pre-train a temporal-spatial vector quantized auto-encoder on high-quality video face datasets to extract expressive context-rich priors. Then, the temporal parse-guided codebook predictor (TPCP) restores faces in different poses based on face parsing context cues without performing face pre-alignment. This strategy reduces artifacts and mitigates jitter caused by cumulative errors from face pre-alignment. Finally, the temporal fidelity regulator (TFR) enhances fidelity through temporal feature interaction and improves video temporal consistency. Extensive experiments on face videos show that our method outperforms previous face restoration baselines. The code will be released on \href{https://github.com/kepengxu/PGTFormer}{https://github.com/kepengxu/PGTFormer}.
6D-Diff: A Keypoint Diffusion Framework for 6D Object Pose Estimation
Jan 02, 2024


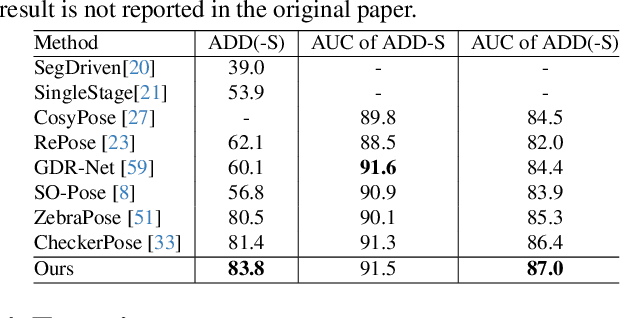
Estimating the 6D object pose from a single RGB image often involves noise and indeterminacy due to challenges such as occlusions and cluttered backgrounds. Meanwhile, diffusion models have shown appealing performance in generating high-quality images from random noise with high indeterminacy through step-by-step denoising. Inspired by their denoising capability, we propose a novel diffusion-based framework (6D-Diff) to handle the noise and indeterminacy in object pose estimation for better performance. In our framework, to establish accurate 2D-3D correspondence, we formulate 2D keypoints detection as a reverse diffusion (denoising) process. To facilitate such a denoising process, we design a Mixture-of-Cauchy-based forward diffusion process and condition the reverse process on the object features. Extensive experiments on the LM-O and YCB-V datasets demonstrate the effectiveness of our framework.